 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Video Autoencoder with Decoupled Temporal and Spatial Context
Dec 12, 2025Video autoencoders compress videos into compact latent representations for efficient reconstruction, playing a vital role in enhancing the quality and efficiency of video generation. However, existing video autoencoders often entangle spatial and temporal information, limiting their ability to capture temporal consistency and leading to suboptimal performance. To address this, we propose Autoregressive Video Autoencoder (ARVAE), which compresses and reconstructs each frame conditioned on its predecessor in an autoregressive manner, allowing flexible processing of videos with arbitrary lengths. ARVAE introduces a temporal-spatial decoupled representation that combines downsampled flow field for temporal coherence with spatial relative compensation for newly emerged content, achieving high compression efficiency without information loss. Specifically, the encoder compresses the current and previous frames into the temporal motion and spatial supplement, while the decoder reconstructs the original frame from the latent representations given the preceding frame. A multi-stage training strategy is employed to progressively optimize the model. Extensive experiments demonstrate that ARVAE achieves superior reconstruction quality with extremely lightweight models and small-scale training data. Moreover, evaluations on video generation tasks highlight its strong potential for downstream applications.
Decouple Content and Motion for Conditional Image-to-Video Generation
Nov 24, 2023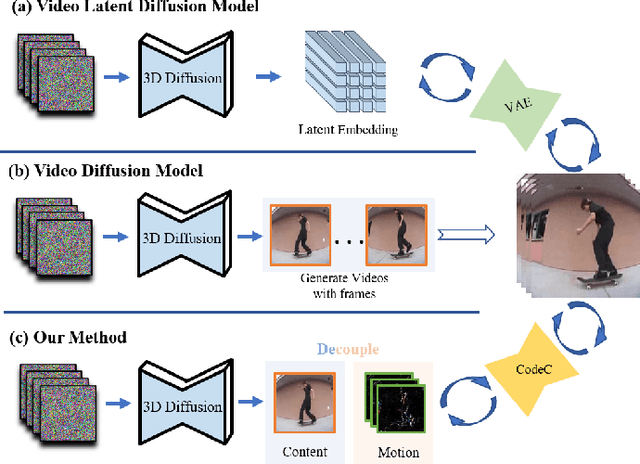

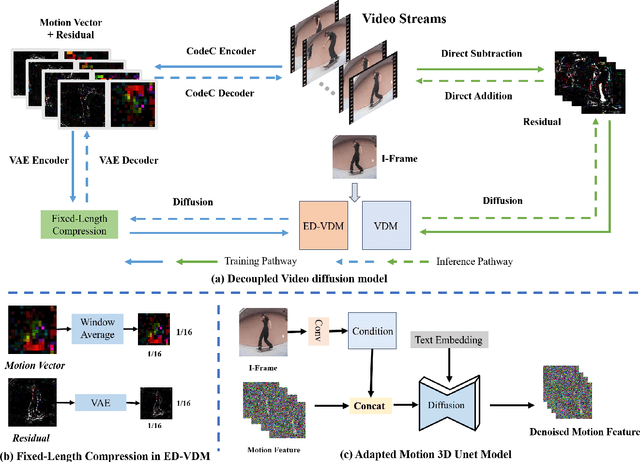

The goal of conditional image-to-video (cI2V) generation is to create a believable new video by beginning with the condition, i.e., one image and text.The previous cI2V generation methods conventionally perform in RGB pixel space, with limitations in modeling motion consistency and visual continuity. Additionally, the efficiency of generating videos in pixel space is quite low.In this paper, we propose a novel approach to address these challenges by disentangling the target RGB pixels into two distinct components: spatial content and temporal motions. Specifically, we predict temporal motions which include motion vector and residual based on a 3D-UNet diffusion model. By explicitly modeling temporal motions and warping them to the starting image, we improve the temporal consistency of generated videos. This results in a reduction of spatial redundancy, emphasizing temporal details. Our proposed method achieves performance improvements by disentangling content and motion, all without introducing new structural complexities to the model. Extensive experiments on various datasets confirm our approach's superior performance over the majority of state-of-the-art methods in both effectiveness and efficiency.
Injecting Image Details into CLIP's Feature Space
Aug 31, 2022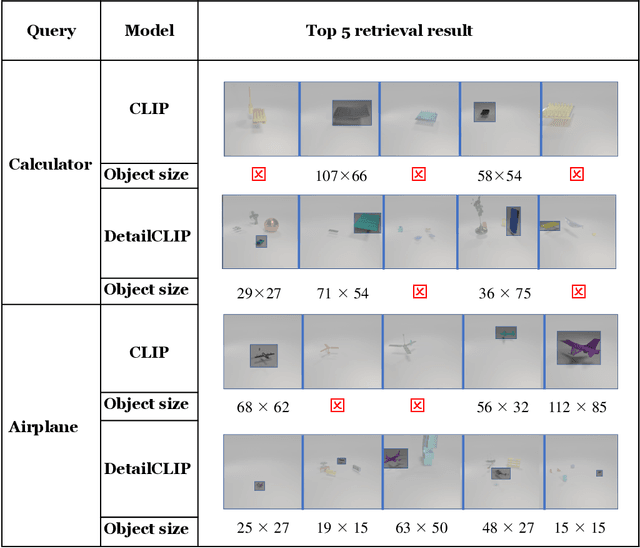
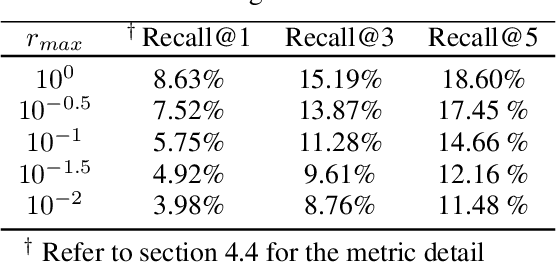

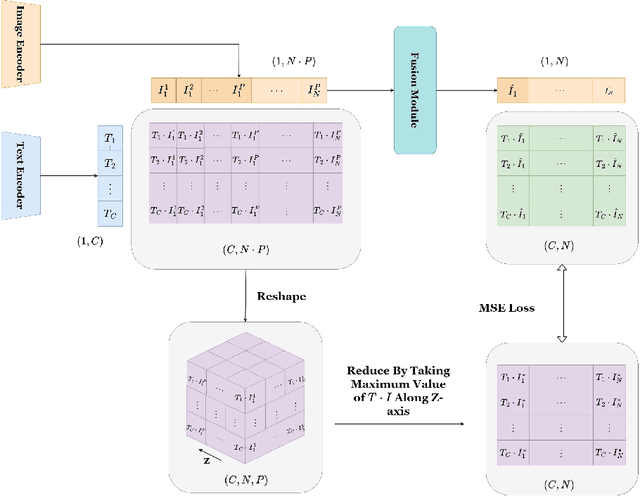
Although CLIP-like Visual Language Models provide a functional joint feature space for image and text, due to the limitation of the CILP-like model's image input size (e.g., 224), subtle details are lost in the feature representation if we input high-resolution images (e.g., 2240). In this work, we introduce an efficient framework that can produce a single feature representation for a high-resolution image that injects image details and shares the same semantic space as the original CLIP. In the framework, we train a feature fusing model based on CLIP features extracted from a carefully designed image patch method that can cover objects of any scale, weakly supervised by image-agnostic class prompted queries. We validate our framework by retrieving images from class prompted queries on the real world and synthetic datasets, showing significant performance improvement on these tasks. Furthermore, to fully demonstrate our framework's detail retrieval ability, we construct a CLEVR-like synthetic dataset called CLVER-DS, which is fully annotated and has a controllable object scale.