 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParagraph-to-Image Generation with Information-Enriched Diffusion Model
Nov 29, 2023Text-to-image (T2I) models have recently experienced rapid development, achieving astonishing performance in terms of fidelity and textual alignment capabilities. However, given a long paragraph (up to 512 words), these generation models still struggle to achieve strong alignment and are unable to generate images depicting complex scenes. In this paper, we introduce an information-enriched diffusion model for paragraph-to-image generation task, termed ParaDiffusion, which delves into the transference of the extensive semantic comprehension capabilities of large language models to the task of image generation. At its core is using a large language model (e.g., Llama V2) to encode long-form text, followed by fine-tuning with LORA to alignthe text-image feature spaces in the generation task. To facilitate the training of long-text semantic alignment, we also curated a high-quality paragraph-image pair dataset, namely ParaImage. This dataset contains a small amount of high-quality, meticulously annotated data, and a large-scale synthetic dataset with long text descriptions being generated using a vision-language model. Experiments demonstrate that ParaDiffusion outperforms state-of-the-art models (SD XL, DeepFloyd IF) on ViLG-300 and ParaPrompts, achieving up to 15% and 45% human voting rate improvements for visual appeal and text faithfulness, respectively. The code and dataset will be released to foster community research on long-text alignment.
Decouple Content and Motion for Conditional Image-to-Video Generation
Nov 24, 2023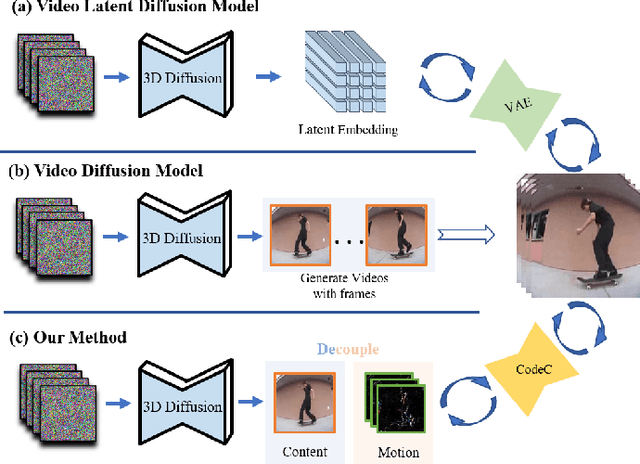

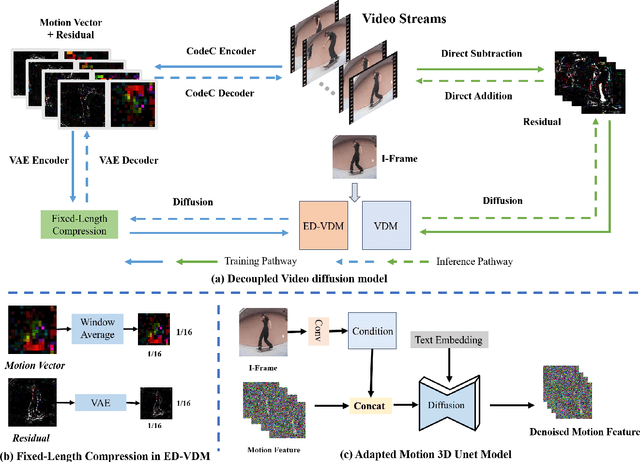

The goal of conditional image-to-video (cI2V) generation is to create a believable new video by beginning with the condition, i.e., one image and text.The previous cI2V generation methods conventionally perform in RGB pixel space, with limitations in modeling motion consistency and visual continuity. Additionally, the efficiency of generating videos in pixel space is quite low.In this paper, we propose a novel approach to address these challenges by disentangling the target RGB pixels into two distinct components: spatial content and temporal motions. Specifically, we predict temporal motions which include motion vector and residual based on a 3D-UNet diffusion model. By explicitly modeling temporal motions and warping them to the starting image, we improve the temporal consistency of generated videos. This results in a reduction of spatial redundancy, emphasizing temporal details. Our proposed method achieves performance improvements by disentangling content and motion, all without introducing new structural complexities to the model. Extensive experiments on various datasets confirm our approach's superior performance over the majority of state-of-the-art methods in both effectiveness and efficiency.
TokenFlow: Rethinking Fine-grained Cross-modal Alignment in Vision-Language Retrieval
Oct 03, 2022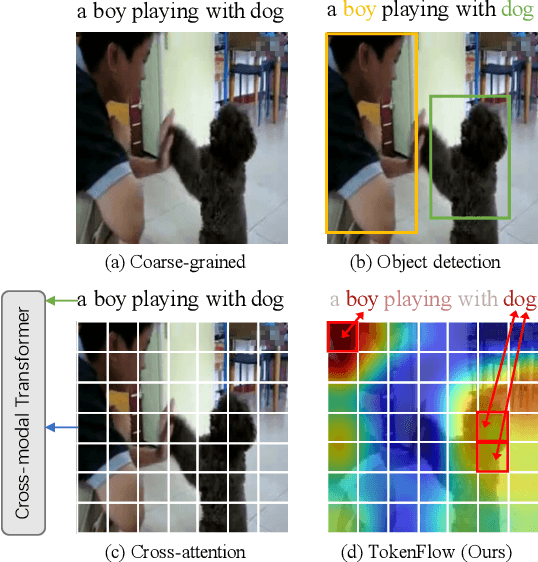
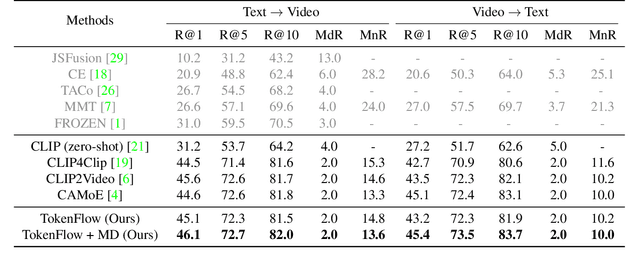
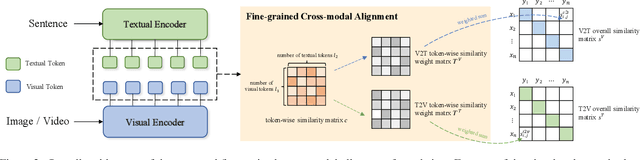
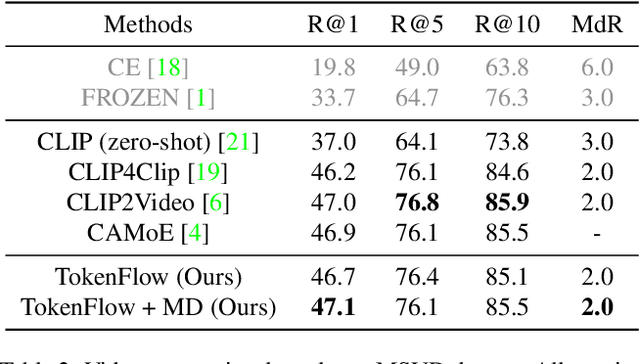
Most existing methods in vision-language retrieval match two modalities by either comparing their global feature vectors which misses sufficient information and lacks interpretability, detecting objects in images or videos and aligning the text with fine-grained features which relies on complicated model designs, or modeling fine-grained interaction via cross-attention upon visual and textual tokens which suffers from inferior efficiency. To address these limitations, some recent works simply aggregate the token-wise similarities to achieve fine-grained alignment, but they lack intuitive explanations as well as neglect the relationships between token-level features and global representations with high-level semantics. In this work, we rethink fine-grained cross-modal alignment and devise a new model-agnostic formulation for it. We additionally demystify the recent popular works and subsume them into our scheme. Furthermore, inspired by optimal transport theory, we introduce TokenFlow, an instantiation of the proposed scheme. By modifying only the similarity function, the performance of our method is comparable to the SoTA algorithms with heavy model designs on major video-text retrieval benchmarks. The visualization further indicates that TokenFlow successfully leverages the fine-grained information and achieves better interpretability.
LaT: Latent Translation with Cycle-Consistency for Video-Text Retrieval
Jul 11, 2022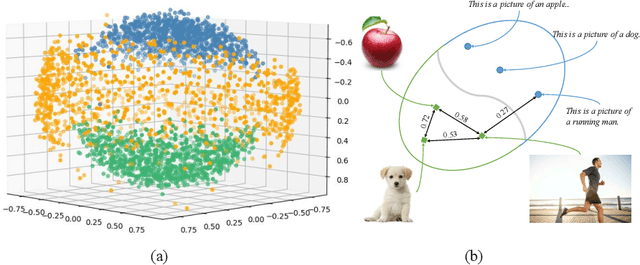
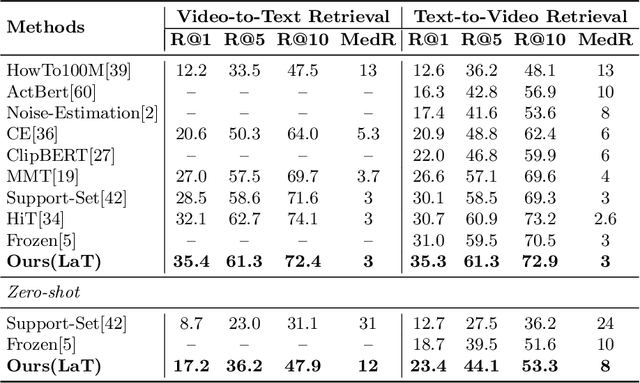
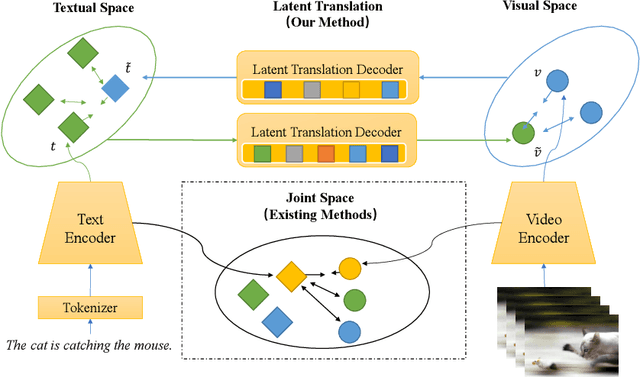
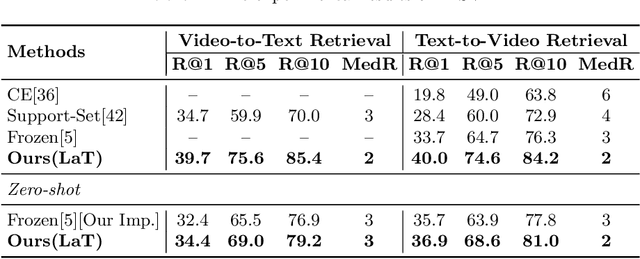
Video-text retrieval is a class of cross-modal representation learning problems, where the goal is to select the video which corresponds to the text query between a given text query and a pool of candidate videos. The contrastive paradigm of vision-language pretraining has shown promising success with large-scale datasets and unified transformer architecture, and demonstrated the power of a joint latent space. Despite this, the intrinsic divergence between the visual domain and textual domain is still far from being eliminated, and projecting different modalities into a joint latent space might result in the distorting of the information inside the single modality. To overcome the above issue, we present a novel mechanism for learning the translation relationship from a source modality space $\mathcal{S}$ to a target modality space $\mathcal{T}$ without the need for a joint latent space, which bridges the gap between visual and textual domains. Furthermore, to keep cycle consistency between translations, we adopt a cycle loss involving both forward translations from $\mathcal{S}$ to the predicted target space $\mathcal{T'}$, and backward translations from $\mathcal{T'}$ back to $\mathcal{S}$. Extensive experiments conducted on MSR-VTT, MSVD, and DiDeMo datasets demonstrate the superiority and effectiveness of our LaT approach compared with vanilla state-of-the-art methods.
Weakly Supervised Learning with Side Information for Noisy Labeled Images
Sep 04, 2020
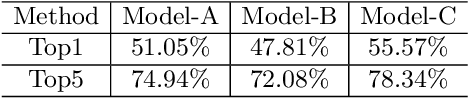
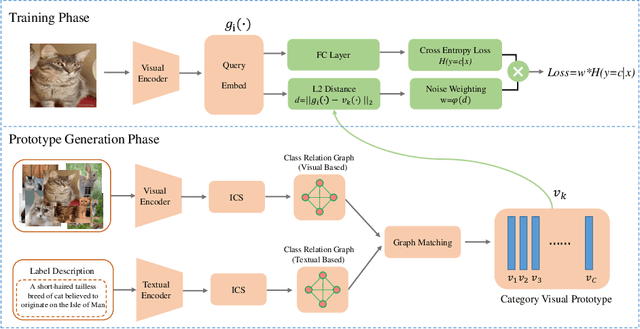

In many real-world datasets, like WebVision, the performance of DNN based classifier is often limited by the noisy labeled data. To tackle this problem, some image related side information, such as captions and tags, often reveal underlying relationships across images. In this paper, we present an efficient weakly supervised learning by using a Side Information Network (SINet), which aims to effectively carry out a large scale classification with severely noisy labels. The proposed SINet consists of a visual prototype module and a noise weighting module. The visual prototype module is designed to generate a compact representation for each category by introducing the side information. The noise weighting module aims to estimate the correctness of each noisy image and produce a confidence score for image ranking during the training procedure. The propsed SINet can largely alleviate the negative impact of noisy image labels, and is beneficial to train a high performance CNN based classifier. Besides, we released a fine-grained product dataset called AliProducts, which contains more than 2.5 million noisy web images crawled from the internet by using queries generated from 50,000 fine-grained semantic classes. Extensive experiments on several popular benchmarks (i.e. Webvision, ImageNet and Clothing-1M) and our proposed AliProducts achieve state-of-the-art performance. The SINet has won the first place in the classification task on WebVision Challenge 2019, and outperformed other competitors by a large margin.
Learning from Large-scale Noisy Web Data with Ubiquitous Reweighting for Image Classification
Nov 02, 2018
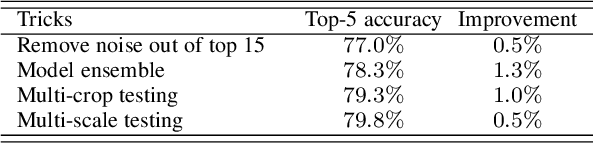


Many advances of deep learning techniques originate from the efforts of addressing the image classification task on large-scale datasets. However, the construction of such clean datasets is costly and time-consuming since the Internet is overwhelmed by noisy images with inadequate and inaccurate tags. In this paper, we propose a Ubiquitous Reweighting Network (URNet) that learns an image classification model from large-scale noisy data. By observing the web data, we find that there are five key challenges, \ie, imbalanced class sizes, high intra-classes diversity and inter-class similarity, imprecise instances, insufficient representative instances, and ambiguous class labels. To alleviate these challenges, we assume that every training instance has the potential to contribute positively by alleviating the data bias and noise via reweighting the influence of each instance according to different class sizes, large instance clusters, its confidence, small instance bags and the labels. In this manner, the influence of bias and noise in the web data can be gradually alleviated, leading to the steadily improving performance of URNet. Experimental results in the WebVision 2018 challenge with 16 million noisy training images from 5000 classes show that our approach outperforms state-of-the-art models and ranks the first place in the image classification task.