 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating Text Synopses to Video Storyboards
Dec 31, 2022

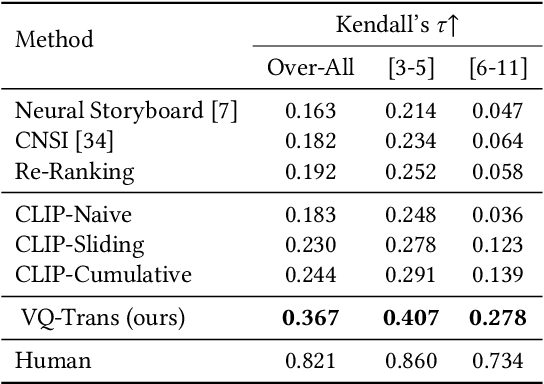

A storyboard is a roadmap for video creation which consists of shot-by-shot images to visualize key plots in a text synopsis. Creating video storyboards however remains challenging which not only requires association between high-level texts and images, but also demands for long-term reasoning to make transitions smooth across shots. In this paper, we propose a new task called Text synopsis to Video Storyboard (TeViS) which aims to retrieve an ordered sequence of images to visualize the text synopsis. We construct a MovieNet-TeViS benchmark based on the public MovieNet dataset. It contains 10K text synopses each paired with keyframes that are manually selected from corresponding movies by considering both relevance and cinematic coherence. We also present an encoder-decoder baseline for the task. The model uses a pretrained vision-and-language model to improve high-level text-image matching. To improve coherence in long-term shots, we further propose to pre-train the decoder on large-scale movie frames without text. Experimental results demonstrate that our proposed model significantly outperforms other models to create text-relevant and coherent storyboards. Nevertheless, there is still a large gap compared to human performance suggesting room for promising future work.
LaT: Latent Translation with Cycle-Consistency for Video-Text Retrieval
Jul 11, 2022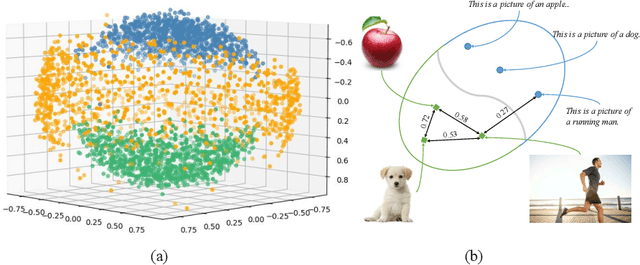
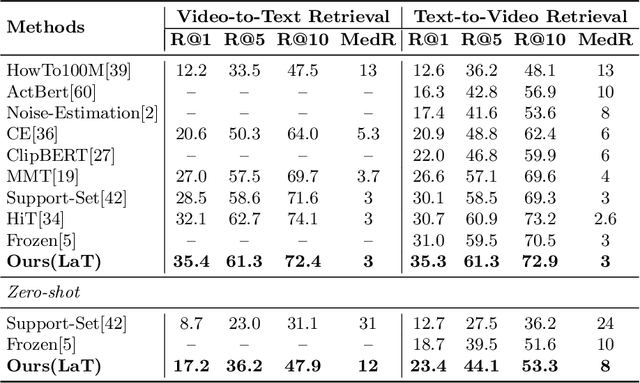
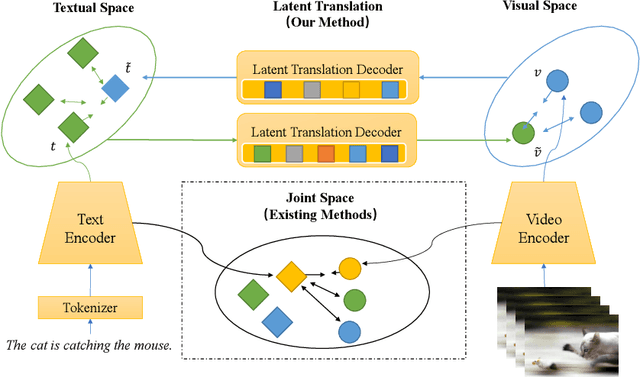
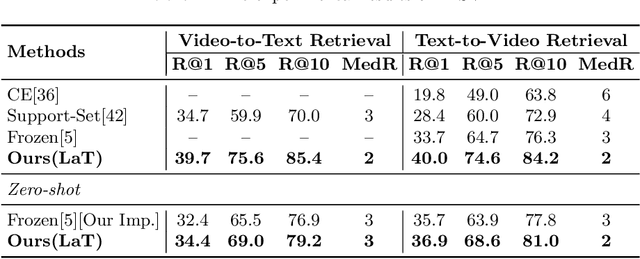
Video-text retrieval is a class of cross-modal representation learning problems, where the goal is to select the video which corresponds to the text query between a given text query and a pool of candidate videos. The contrastive paradigm of vision-language pretraining has shown promising success with large-scale datasets and unified transformer architecture, and demonstrated the power of a joint latent space. Despite this, the intrinsic divergence between the visual domain and textual domain is still far from being eliminated, and projecting different modalities into a joint latent space might result in the distorting of the information inside the single modality. To overcome the above issue, we present a novel mechanism for learning the translation relationship from a source modality space $\mathcal{S}$ to a target modality space $\mathcal{T}$ without the need for a joint latent space, which bridges the gap between visual and textual domains. Furthermore, to keep cycle consistency between translations, we adopt a cycle loss involving both forward translations from $\mathcal{S}$ to the predicted target space $\mathcal{T'}$, and backward translations from $\mathcal{T'}$ back to $\mathcal{S}$. Extensive experiments conducted on MSR-VTT, MSVD, and DiDeMo datasets demonstrate the superiority and effectiveness of our LaT approach compared with vanilla state-of-the-art methods.