 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Shape-Aware Foundation Model for Time Series Classification
Jan 10, 2026Foundation models pre-trained on large-scale source datasets are reshaping the traditional training paradigm for time series classification. However, existing time series foundation models primarily focus on forecasting tasks and often overlook classification-specific challenges, such as modeling interpretable shapelets that capture class-discriminative temporal features. To bridge this gap, we propose UniShape, a unified shape-aware foundation model designed for time series classification. UniShape incorporates a shape-aware adapter that adaptively aggregates multiscale discriminative subsequences (shapes) into class tokens, effectively selecting the most relevant subsequence scales to enhance model interpretability. Meanwhile, a prototype-based pretraining module is introduced to jointly learn instance- and shape-level representations, enabling the capture of transferable shape patterns. Pre-trained on a large-scale multi-domain time series dataset comprising 1.89 million samples, UniShape exhibits superior generalization across diverse target domains. Experiments on 128 UCR datasets and 30 additional time series datasets demonstrate that UniShape achieves state-of-the-art classification performance, with interpretability and ablation analyses further validating its effectiveness.
Robust Motion Generation using Part-level Reliable Data from Videos
Dec 14, 2025Extracting human motion from large-scale web videos offers a scalable solution to the data scarcity issue in character animation. However, some human parts in many video frames cannot be seen due to off-screen captures or occlusions. It brings a dilemma: discarding the data missing any part limits scale and diversity, while retaining it compromises data quality and model performance. To address this problem, we propose leveraging credible part-level data extracted from videos to enhance motion generation via a robust part-aware masked autoregression model. First, we decompose a human body into five parts and detect the parts clearly seen in a video frame as "credible". Second, the credible parts are encoded into latent tokens by our proposed part-aware variational autoencoder. Third, we propose a robust part-level masked generation model to predict masked credible parts, while ignoring those noisy parts. In addition, we contribute K700-M, a challenging new benchmark comprising approximately 200k real-world motion sequences, for evaluation. Experimental results indicate that our method successfully outperforms baselines on both clean and noisy datasets in terms of motion quality, semantic consistency and diversity. Project page: https://boyuaner.github.io/ropar-main/
FedHL: Federated Learning for Heterogeneous Low-Rank Adaptation via Unbiased Aggregation
May 24, 2025



Federated Learning (FL) facilitates the fine-tuning of Foundation Models (FMs) using distributed data sources, with Low-Rank Adaptation (LoRA) gaining popularity due to its low communication costs and strong performance. While recent work acknowledges the benefits of heterogeneous LoRA in FL and introduces flexible algorithms to support its implementation, our theoretical analysis reveals a critical gap: existing methods lack formal convergence guarantees due to parameter truncation and biased gradient updates. Specifically, adapting client-specific LoRA ranks necessitates truncating global parameters, which introduces inherent truncation errors and leads to subsequent inaccurate gradient updates that accumulate over training rounds, ultimately degrading performance. To address the above issues, we propose \textbf{FedHL}, a simple yet effective \textbf{Fed}erated Learning framework tailored for \textbf{H}eterogeneous \textbf{L}oRA. By leveraging the full-rank global model as a calibrated aggregation basis, FedHL eliminates the direct truncation bias from initial alignment with client-specific ranks. Furthermore, we derive the theoretically optimal aggregation weights by minimizing the gradient drift term in the convergence upper bound. Our analysis shows that FedHL guarantees $\mathcal{O}(1/\sqrt{T})$ convergence rate, and experiments on multiple real-world datasets demonstrate a 1-3\% improvement over several state-of-the-art methods.
HyperIMTS: Hypergraph Neural Network for Irregular Multivariate Time Series Forecasting
May 23, 2025Irregular multivariate time series (IMTS) are characterized by irregular time intervals within variables and unaligned observations across variables, posing challenges in learning temporal and variable dependencies. Many existing IMTS models either require padded samples to learn separately from temporal and variable dimensions, or represent original samples via bipartite graphs or sets. However, the former approaches often need to handle extra padding values affecting efficiency and disrupting original sampling patterns, while the latter ones have limitations in capturing dependencies among unaligned observations. To represent and learn both dependencies from original observations in a unified form, we propose HyperIMTS, a Hypergraph neural network for Irregular Multivariate Time Series forecasting. Observed values are converted as nodes in the hypergraph, interconnected by temporal and variable hyperedges to enable message passing among all observations. Through irregularity-aware message passing, HyperIMTS captures variable dependencies in a time-adaptive way to achieve accurate forecasting. Experiments demonstrate HyperIMTS's competitive performance among state-of-the-art models in IMTS forecasting with low computational cost.
Learning Soft Sparse Shapes for Efficient Time-Series Classification
May 11, 2025Shapelets are discriminative subsequences (or shapes) with high interpretability in time series classification. Due to the time-intensive nature of shapelet discovery, existing shapelet-based methods mainly focus on selecting discriminative shapes while discarding others to achieve candidate subsequence sparsification. However, this approach may exclude beneficial shapes and overlook the varying contributions of shapelets to classification performance. To this end, we propose a \textbf{Soft} sparse \textbf{Shape}s (\textbf{SoftShape}) model for efficient time series classification. Our approach mainly introduces soft shape sparsification and soft shape learning blocks. The former transforms shapes into soft representations based on classification contribution scores, merging lower-scored ones into a single shape to retain and differentiate all subsequence information. The latter facilitates intra- and inter-shape temporal pattern learning, improving model efficiency by using sparsified soft shapes as inputs. Specifically, we employ a learnable router to activate a subset of class-specific expert networks for intra-shape pattern learning. Meanwhile, a shared expert network learns inter-shape patterns by converting sparsified shapes into sequences. Extensive experiments show that SoftShape outperforms state-of-the-art methods and produces interpretable results.
Two-in-One: Unified Multi-Person Interactive Motion Generation by Latent Diffusion Transformer
Dec 21, 2024



Multi-person interactive motion generation, a critical yet under-explored domain in computer character animation, poses significant challenges such as intricate modeling of inter-human interactions beyond individual motions and generating two motions with huge differences from one text condition. Current research often employs separate module branches for individual motions, leading to a loss of interaction information and increased computational demands. To address these challenges, we propose a novel, unified approach that models multi-person motions and their interactions within a single latent space. Our approach streamlines the process by treating interactive motions as an integrated data point, utilizing a Variational AutoEncoder (VAE) for compression into a unified latent space, and performing a diffusion process within this space, guided by the natural language conditions. Experimental results demonstrate our method's superiority over existing approaches in generation quality, performing text condition in particular when motions have significant asymmetry, and accelerating the generation efficiency while preserving high quality.
Neighborhood and Global Perturbations Supported SAM in Federated Learning: From Local Tweaks To Global Awareness
Aug 26, 2024Federated Learning (FL) can be coordinated under the orchestration of a central server to collaboratively build a privacy-preserving model without the need for data exchange. However, participant data heterogeneity leads to local optima divergence, subsequently affecting convergence outcomes. Recent research has focused on global sharpness-aware minimization (SAM) and dynamic regularization techniques to enhance consistency between global and local generalization and optimization objectives. Nonetheless, the estimation of global SAM introduces additional computational and memory overhead, while dynamic regularization suffers from bias in the local and global dual variables due to training isolation. In this paper, we propose a novel FL algorithm, FedTOGA, designed to consider optimization and generalization objectives while maintaining minimal uplink communication overhead. By linking local perturbations to global updates, global generalization consistency is improved. Additionally, global updates are used to correct local dynamic regularizers, reducing dual variables bias and enhancing optimization consistency. Global updates are passively received by clients, reducing overhead. We also propose neighborhood perturbation to approximate local perturbation, analyzing its strengths and limitations. Theoretical analysis shows FedTOGA achieves faster convergence $O(1/T)$ under non-convex functions. Empirical studies demonstrate that FedTOGA outperforms state-of-the-art algorithms, with a 1\% accuracy increase and 30\% faster convergence, achieving state-of-the-art.
Translating Text Synopses to Video Storyboards
Dec 31, 2022

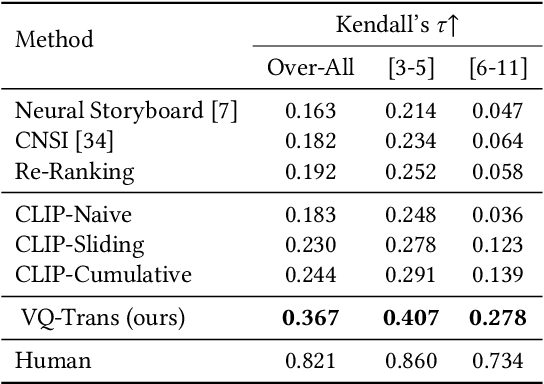

A storyboard is a roadmap for video creation which consists of shot-by-shot images to visualize key plots in a text synopsis. Creating video storyboards however remains challenging which not only requires association between high-level texts and images, but also demands for long-term reasoning to make transitions smooth across shots. In this paper, we propose a new task called Text synopsis to Video Storyboard (TeViS) which aims to retrieve an ordered sequence of images to visualize the text synopsis. We construct a MovieNet-TeViS benchmark based on the public MovieNet dataset. It contains 10K text synopses each paired with keyframes that are manually selected from corresponding movies by considering both relevance and cinematic coherence. We also present an encoder-decoder baseline for the task. The model uses a pretrained vision-and-language model to improve high-level text-image matching. To improve coherence in long-term shots, we further propose to pre-train the decoder on large-scale movie frames without text. Experimental results demonstrate that our proposed model significantly outperforms other models to create text-relevant and coherent storyboards. Nevertheless, there is still a large gap compared to human performance suggesting room for promising future work.
Model predictive approach to integrated path planning and tracking for autonomous vehicles
May 09, 2019
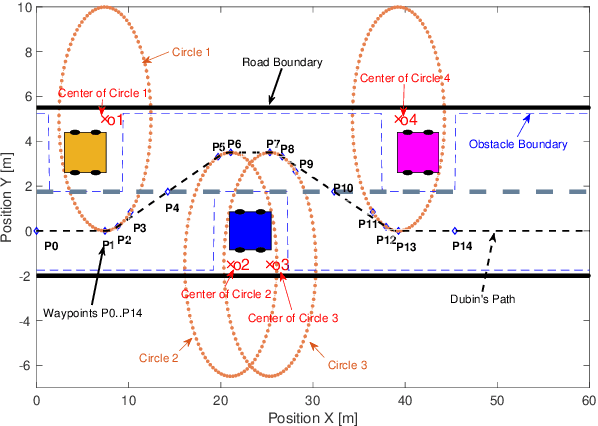
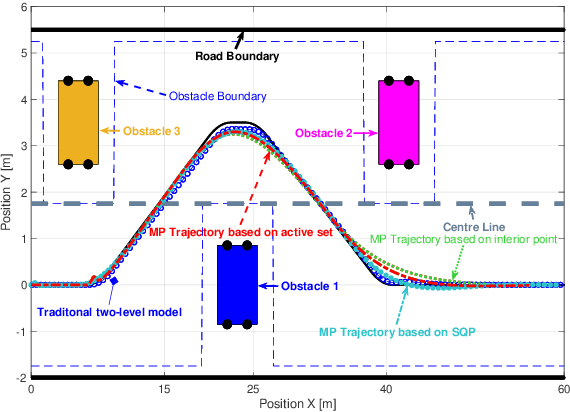
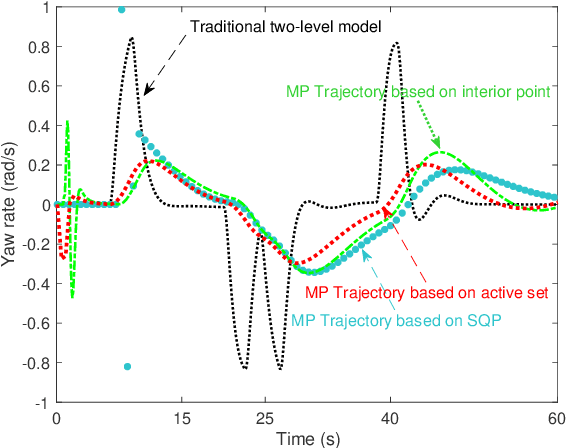
In the path planning problem of autonomous application, the existing studies separately consider the path planning and trajectory tracking control of the autonomous vehicle and few of them have integrated the trajectory planning and trajectory control together. To fill in this research gap, this study proposes an integrated trajectory planning and trajectory control method. This paper also studies the collision avoidance problem of autonomous by considering static and dynamic obstacles. Simulation results have been presented to show the effectiveness of the proposed control method.