 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoVAD: Resource-Efficient Video Anomaly Detection via Dynamic Semantic Memory in Edge Computing Scenarios
Jun 04, 2026Deploying Video Anomaly Detection (VAD) in real-world surveillance faces a fundamental tension between the demand for high-level semantics to ensure effectiveness and the limited computational resources of edge devices. Vision-Language Models (VLMs) provide rich open-vocabulary semantics, but their latency and computational cost preclude on-device deployment. To address the challenge, we propose MemoVAD, an edge-cloud collaborative framework that selectively incorporates VLM semantics into streaming VAD. MemoVAD runs most inference on the edge with a lightweight detector and a causal Temporal Context Encoder (TCE) to model temporal dependencies. Specifically, we introduce an Uncertainty-Aware Gating (UAG) policy grounded in Subjective Logic to model perceived uncertainty and query the cloud-based VLM only for high-uncertainty and semantically novel clips. Besides, a Dynamic Semantic Memory (DSM) is designed to cache VLM-verified prototypes for efficient retrieval, enabling the edge model to progressively incorporate VLM-level semantics via a semantic adapter. Experiments on UCF-Crime and XD-Violence datasets via a real edge device show that MemoVAD substantially reduces communication overhead while surpassing state-of-the-art performance.
HiLoRA: Hierarchical Low-Rank Adaptation for Personalized Federated Learning
Mar 03, 2026Vision Transformers (ViTs) have been widely adopted in vision tasks due to their strong transferability. In Federated Learning (FL), where full fine-tuning is communication heavy, Low-Rank Adaptation (LoRA) provides an efficient and communication-friendly way to adapt ViTs. However, existing LoRA-based federated tuning methods overlook latent client structures in real-world settings, limiting shared representation learning and hindering effective adaptation to unseen clients. To address this, we propose HiLoRA, a hierarchical LoRA framework that places adapters at three levels: root, cluster, and leaf, each designed to capture global, subgroup, and client-specific knowledge, respectively. Through cross-tier orthogonality and cascaded optimization, HiLoRA separates update subspaces and aligns each tier with its residual personalized objective. In particular, we develop a LoRA-Subspace Adaptive Clustering mechanism that infers latent client groups via subspace similarity analysis, thereby facilitating knowledge sharing across structurally aligned clients. Theoretically, we establish a tier-wise generalization analysis that supports HiLoRA's design. Experiments on ViT backbones with CIFAR-100 and DomainNet demonstrate consistent improvements in both personalization and generalization.
MATRIX AS PLAN: Structured Logical Reasoning with Feedback-Driven Replanning
Jan 15, 2026As knowledge and semantics on the web grow increasingly complex, enhancing Large Language Models (LLMs) comprehension and reasoning capabilities has become particularly important. Chain-of-Thought (CoT) prompting has been shown to enhance the reasoning capabilities of LLMs. However, it still falls short on logical reasoning tasks that rely on symbolic expressions and strict deductive rules. Neuro-symbolic methods address this gap by enforcing formal correctness through external solvers. Yet these solvers are highly format-sensitive, and small instabilities in model outputs can lead to frequent processing failures. LLM-driven approaches avoid parsing brittleness, but they lack structured representations and process-level error-correction mechanisms. To further enhance the logical reasoning capabilities of LLMs, we propose MatrixCoT, a structured CoT framework with a matrix-based plan. Specifically, we normalize and type natural language expressions, attach explicit citation fields, and introduce a matrix-based planning method to preserve global relations among steps. The plan becomes a verifiable artifact, making execution more stable. For verification, we also add a feedback-driven replanning mechanism. Under semantic-equivalence constraints, it identifies omissions and defects, rewrites and compresses the dependency matrix, and produces a more trustworthy final answer. Experiments on five logical-reasoning benchmarks and five LLMs show that, without relying on external solvers, MatrixCoT enhances both robustness and interpretability when tackling complex symbolic reasoning tasks, while maintaining competitive performance.
FedHL: Federated Learning for Heterogeneous Low-Rank Adaptation via Unbiased Aggregation
May 24, 2025



Federated Learning (FL) facilitates the fine-tuning of Foundation Models (FMs) using distributed data sources, with Low-Rank Adaptation (LoRA) gaining popularity due to its low communication costs and strong performance. While recent work acknowledges the benefits of heterogeneous LoRA in FL and introduces flexible algorithms to support its implementation, our theoretical analysis reveals a critical gap: existing methods lack formal convergence guarantees due to parameter truncation and biased gradient updates. Specifically, adapting client-specific LoRA ranks necessitates truncating global parameters, which introduces inherent truncation errors and leads to subsequent inaccurate gradient updates that accumulate over training rounds, ultimately degrading performance. To address the above issues, we propose \textbf{FedHL}, a simple yet effective \textbf{Fed}erated Learning framework tailored for \textbf{H}eterogeneous \textbf{L}oRA. By leveraging the full-rank global model as a calibrated aggregation basis, FedHL eliminates the direct truncation bias from initial alignment with client-specific ranks. Furthermore, we derive the theoretically optimal aggregation weights by minimizing the gradient drift term in the convergence upper bound. Our analysis shows that FedHL guarantees $\mathcal{O}(1/\sqrt{T})$ convergence rate, and experiments on multiple real-world datasets demonstrate a 1-3\% improvement over several state-of-the-art methods.
DifAttack++: Query-Efficient Black-Box Adversarial Attack via Hierarchical Disentangled Feature Space in Cross Domain
Jun 05, 2024
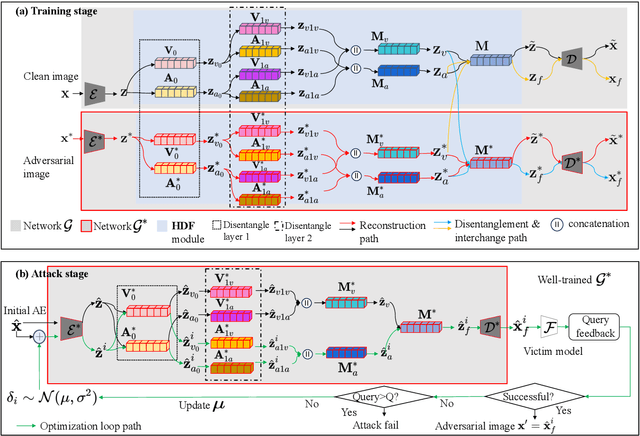


This work investigates efficient score-based black-box adversarial attacks with a high Attack Success Rate (ASR) and good generalizability. We design a novel attack method based on a \textit{Hierarchical} \textbf{Di}sentangled \textbf{F}eature space and \textit{cross domain}, called \textbf{DifAttack++}, which differs significantly from the existing ones operating over the entire feature space. Specifically, DifAttack++ firstly disentangles an image's latent feature into an \textit{adversarial feature} (AF) and a \textit{visual feature} (VF) via an autoencoder equipped with our specially designed \textbf{H}ierarchical \textbf{D}ecouple-\textbf{F}usion (HDF) module, where the AF dominates the adversarial capability of an image, while the VF largely determines its visual appearance. We train such autoencoders for the clean and adversarial image domains respectively, meanwhile realizing feature disentanglement, by using pairs of clean images and their Adversarial Examples (AEs) generated from available surrogate models via white-box attack methods. Eventually, in the black-box attack stage, DifAttack++ iteratively optimizes the AF according to the query feedback from the victim model until a successful AE is generated, while keeping the VF unaltered. Extensive experimental results demonstrate that our method achieves superior ASR and query efficiency than SOTA methods, meanwhile exhibiting much better visual quality of AEs. The code is available at https://github.com/csjunjun/DifAttack.git.
Tag-assisted Multimodal Sentiment Analysis under Uncertain Missing Modalities
Apr 28, 2022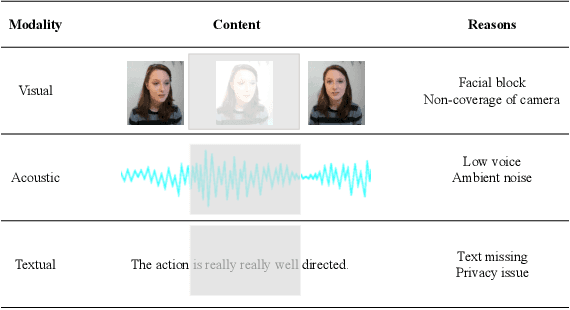


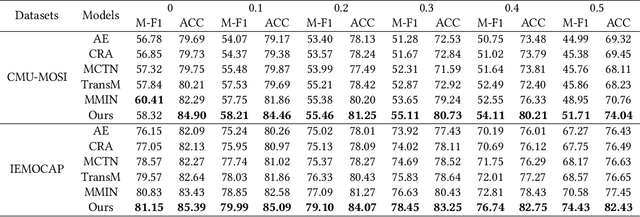
Multimodal sentiment analysis has been studied under the assumption that all modalities are available. However, such a strong assumption does not always hold in practice, and most of multimodal fusion models may fail when partial modalities are missing. Several works have addressed the missing modality problem; but most of them only considered the single modality missing case, and ignored the practically more general cases of multiple modalities missing. To this end, in this paper, we propose a Tag-Assisted Transformer Encoder (TATE) network to handle the problem of missing uncertain modalities. Specifically, we design a tag encoding module to cover both the single modality and multiple modalities missing cases, so as to guide the network's attention to those missing modalities. Besides, we adopt a new space projection pattern to align common vectors. Then, a Transformer encoder-decoder network is utilized to learn the missing modality features. At last, the outputs of the Transformer encoder are used for the final sentiment classification. Extensive experiments are conducted on CMU-MOSI and IEMOCAP datasets, showing that our method can achieve significant improvements compared with several baselines.