 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoVAD: Resource-Efficient Video Anomaly Detection via Dynamic Semantic Memory in Edge Computing Scenarios
Jun 04, 2026Deploying Video Anomaly Detection (VAD) in real-world surveillance faces a fundamental tension between the demand for high-level semantics to ensure effectiveness and the limited computational resources of edge devices. Vision-Language Models (VLMs) provide rich open-vocabulary semantics, but their latency and computational cost preclude on-device deployment. To address the challenge, we propose MemoVAD, an edge-cloud collaborative framework that selectively incorporates VLM semantics into streaming VAD. MemoVAD runs most inference on the edge with a lightweight detector and a causal Temporal Context Encoder (TCE) to model temporal dependencies. Specifically, we introduce an Uncertainty-Aware Gating (UAG) policy grounded in Subjective Logic to model perceived uncertainty and query the cloud-based VLM only for high-uncertainty and semantically novel clips. Besides, a Dynamic Semantic Memory (DSM) is designed to cache VLM-verified prototypes for efficient retrieval, enabling the edge model to progressively incorporate VLM-level semantics via a semantic adapter. Experiments on UCF-Crime and XD-Violence datasets via a real edge device show that MemoVAD substantially reduces communication overhead while surpassing state-of-the-art performance.
WAM-Nav: Asymmetric Latent World-Action Modeling for Unified Visual Navigation
Jun 03, 2026Visual navigation requires generating smooth and collision-free trajectories under complex geometric and physical constraints. Existing reactive policies that directly map observations to actions lack anticipatory reasoning, limiting their ability to proactively avoid obstacles. While visual imagination offers predictive foresight, conventional modular approaches separate scene prediction from policy learning, often leading to error accumulation and inefficient inference. To address these limitations, we propose WAM-Nav, a Latent World-Action Model for embodied visual navigation that jointly learns action generation and latent visual foresight, enabling more robust and foresighted navigation decisions without compromising inference efficiency. Specifically, WAM-Nav utilizes a shared Diffusion Transformer for asymmetric joint diffusion to concurrently generate long-horizon actions and short-horizon visual foresight, reducing the inference latency and visual error accumulation inherent in multi-step autoregressive rollouts. To further encourage smooth and consistent trajectory generation, we introduce a dual-stream contextual conditioning mechanism that integrates episode-level ego-motion history with sequential visual observations. Combined with a unified goal alignment module that preserves balanced representations across goal types, WAM-Nav naturally supports Image-Goal, Point-Goal, and No-Goal exploration within a single policy. Extensive experiments on the challenging ClutterScenes and InternScenes benchmarks demonstrate strong generalization of WAM-Nav, particularly on Image-Goal and Point-Goal navigation, where it improves success rates by 15.7% and 3.3%, respectively. Real-world deployment further validates effective zero-shot sim-to-real transfer, achieving an average 85% task success rate across diverse indoor and outdoor environments.
Scepsy: Serving Agentic Workflows Using Aggregate LLM Pipelines
Apr 16, 2026Agentic workflows carry out complex tasks by orchestrating multiple large language models (LLMs) and tools. Serving such workflows at a target throughput with low latency is challenging because they can be defined using arbitrary agentic frameworks and exhibit unpredictable execution times: execution may branch, fan-out, or recur in data-dependent ways. Since LLMs in workflows often outnumber available GPUs, their execution also leads to GPU oversubscription. We describe Scepsy, a new agentic serving system that efficiently schedules arbitrary multi-LLM agentic workflows onto a GPU cluster. Scepsy exploits the insight that, while agentic workflows have unpredictable end-to-end latencies, the shares of each LLM's total execution times are comparatively stable across executions. Scepsy decides on GPU allocations based on these aggregate shares: first, it profiles the LLMs under different parallelism degrees. It then uses these statistics to construct an Aggregate LLM Pipeline, which is a lightweight latency/throughput predictor for allocations. To find a GPU allocation that minimizes latency while achieving a target throughput, Scepsy uses the Aggregate LLM Pipeline to explore a search space over fractional GPU shares, tensor parallelism degrees, and replica counts. It uses a hierarchical heuristic to place the best allocation onto the GPU cluster, minimizing fragmentation, while respecting network topology constraints. Our evaluation on realistic agentic workflows shows that Scepsy achieves up to 2.4x higher throughput and 27x lower latency compared to systems that optimize LLMs independently or rely on user-specified allocations.
HiLoRA: Hierarchical Low-Rank Adaptation for Personalized Federated Learning
Mar 03, 2026Vision Transformers (ViTs) have been widely adopted in vision tasks due to their strong transferability. In Federated Learning (FL), where full fine-tuning is communication heavy, Low-Rank Adaptation (LoRA) provides an efficient and communication-friendly way to adapt ViTs. However, existing LoRA-based federated tuning methods overlook latent client structures in real-world settings, limiting shared representation learning and hindering effective adaptation to unseen clients. To address this, we propose HiLoRA, a hierarchical LoRA framework that places adapters at three levels: root, cluster, and leaf, each designed to capture global, subgroup, and client-specific knowledge, respectively. Through cross-tier orthogonality and cascaded optimization, HiLoRA separates update subspaces and aligns each tier with its residual personalized objective. In particular, we develop a LoRA-Subspace Adaptive Clustering mechanism that infers latent client groups via subspace similarity analysis, thereby facilitating knowledge sharing across structurally aligned clients. Theoretically, we establish a tier-wise generalization analysis that supports HiLoRA's design. Experiments on ViT backbones with CIFAR-100 and DomainNet demonstrate consistent improvements in both personalization and generalization.
MATRIX AS PLAN: Structured Logical Reasoning with Feedback-Driven Replanning
Jan 15, 2026As knowledge and semantics on the web grow increasingly complex, enhancing Large Language Models (LLMs) comprehension and reasoning capabilities has become particularly important. Chain-of-Thought (CoT) prompting has been shown to enhance the reasoning capabilities of LLMs. However, it still falls short on logical reasoning tasks that rely on symbolic expressions and strict deductive rules. Neuro-symbolic methods address this gap by enforcing formal correctness through external solvers. Yet these solvers are highly format-sensitive, and small instabilities in model outputs can lead to frequent processing failures. LLM-driven approaches avoid parsing brittleness, but they lack structured representations and process-level error-correction mechanisms. To further enhance the logical reasoning capabilities of LLMs, we propose MatrixCoT, a structured CoT framework with a matrix-based plan. Specifically, we normalize and type natural language expressions, attach explicit citation fields, and introduce a matrix-based planning method to preserve global relations among steps. The plan becomes a verifiable artifact, making execution more stable. For verification, we also add a feedback-driven replanning mechanism. Under semantic-equivalence constraints, it identifies omissions and defects, rewrites and compresses the dependency matrix, and produces a more trustworthy final answer. Experiments on five logical-reasoning benchmarks and five LLMs show that, without relying on external solvers, MatrixCoT enhances both robustness and interpretability when tackling complex symbolic reasoning tasks, while maintaining competitive performance.
Temporal-IRL: Modeling Port Congestion and Berth Scheduling with Inverse Reinforcement Learning
Jun 24, 2025Predicting port congestion is crucial for maintaining reliable global supply chains. Accurate forecasts enableimprovedshipment planning, reducedelaysand costs, and optimizeinventoryanddistributionstrategies, thereby ensuring timely deliveries and enhancing supply chain resilience. To achieve accurate predictions, analyzing vessel behavior and their stay times at specific port terminals is essential, focusing particularly on berth scheduling under various conditions. Crucially, the model must capture and learn the underlying priorities and patterns of berth scheduling. Berth scheduling and planning are influenced by a range of factors, including incoming vessel size, waiting times, and the status of vessels within the port terminal. By observing historical Automatic Identification System (AIS) positions of vessels, we reconstruct berth schedules, which are subsequently utilized to determine the reward function via Inverse Reinforcement Learning (IRL). For this purpose, we modeled a specific terminal at the Port of New York/New Jersey and developed Temporal-IRL. This Temporal-IRL model learns berth scheduling to predict vessel sequencing at the terminal and estimate vessel port stay, encompassing both waiting and berthing times, to forecast port congestion. Utilizing data from Maher Terminal spanning January 2015 to September 2023, we trained and tested the model, achieving demonstrably excellent results.
FedHL: Federated Learning for Heterogeneous Low-Rank Adaptation via Unbiased Aggregation
May 24, 2025



Federated Learning (FL) facilitates the fine-tuning of Foundation Models (FMs) using distributed data sources, with Low-Rank Adaptation (LoRA) gaining popularity due to its low communication costs and strong performance. While recent work acknowledges the benefits of heterogeneous LoRA in FL and introduces flexible algorithms to support its implementation, our theoretical analysis reveals a critical gap: existing methods lack formal convergence guarantees due to parameter truncation and biased gradient updates. Specifically, adapting client-specific LoRA ranks necessitates truncating global parameters, which introduces inherent truncation errors and leads to subsequent inaccurate gradient updates that accumulate over training rounds, ultimately degrading performance. To address the above issues, we propose \textbf{FedHL}, a simple yet effective \textbf{Fed}erated Learning framework tailored for \textbf{H}eterogeneous \textbf{L}oRA. By leveraging the full-rank global model as a calibrated aggregation basis, FedHL eliminates the direct truncation bias from initial alignment with client-specific ranks. Furthermore, we derive the theoretically optimal aggregation weights by minimizing the gradient drift term in the convergence upper bound. Our analysis shows that FedHL guarantees $\mathcal{O}(1/\sqrt{T})$ convergence rate, and experiments on multiple real-world datasets demonstrate a 1-3\% improvement over several state-of-the-art methods.
Unlocking Multimodal Integration in EHRs: A Prompt Learning Framework for Language and Time Series Fusion
Feb 19, 2025Large language models (LLMs) have shown remarkable performance in vision-language tasks, but their application in the medical field remains underexplored, particularly for integrating structured time series data with unstructured clinical notes. In clinical practice, dynamic time series data such as lab test results capture critical temporal patterns, while clinical notes provide rich semantic context. Merging these modalities is challenging due to the inherent differences between continuous signals and discrete text. To bridge this gap, we introduce ProMedTS, a novel self-supervised multimodal framework that employs prompt-guided learning to unify these heterogeneous data types. Our approach leverages lightweight anomaly detection to generate anomaly captions that serve as prompts, guiding the encoding of raw time series data into informative embeddings. These embeddings are aligned with textual representations in a shared latent space, preserving fine-grained temporal nuances alongside semantic insights. Furthermore, our framework incorporates tailored self-supervised objectives to enhance both intra- and inter-modal alignment. We evaluate ProMedTS on disease diagnosis tasks using real-world datasets, and the results demonstrate that our method consistently outperforms state-of-the-art approaches.
TENPLEX: Changing Resources of Deep Learning Jobs using Parallelizable Tensor Collections
Dec 08, 2023Deep learning (DL) jobs use multi-dimensional parallelism, i.e they combine data, model, and pipeline parallelism, to use large GPU clusters efficiently. This couples jobs tightly to a set of GPU devices, but jobs may experience changes to the device allocation: (i) resource elasticity during training adds or removes devices; (ii) hardware maintenance may require redeployment on different devices; and (iii) device failures force jobs to run with fewer devices. Current DL frameworks lack support for these scenarios, as they cannot change the multi-dimensional parallelism of an already-running job in an efficient and model-independent way. We describe Tenplex, a state management library for DL frameworks that enables jobs to change the GPU allocation and job parallelism at runtime. Tenplex achieves this by externalizing the DL job state during training as a parallelizable tensor collection (PTC). When the GPU allocation for the DL job changes, Tenplex uses the PTC to transform the DL job state: for the dataset state, Tenplex repartitions it under data parallelism and exposes it to workers through a virtual file system; for the model state, Tenplex obtains it as partitioned checkpoints and transforms them to reflect the new parallelization configuration. For efficiency, these PTC transformations are executed in parallel with a minimum amount of data movement between devices and workers. Our experiments show that Tenplex enables DL jobs to support dynamic parallelization with low overhead.
Quiver: Supporting GPUs for Low-Latency, High-Throughput GNN Serving with Workload Awareness
May 18, 2023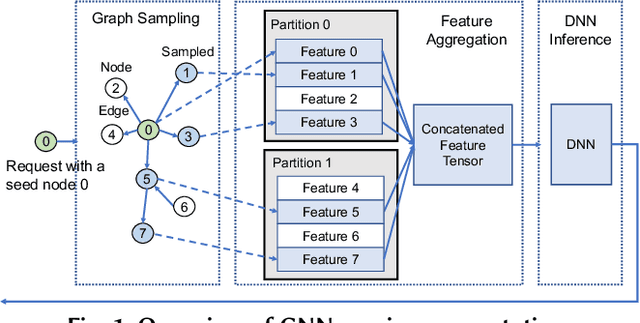
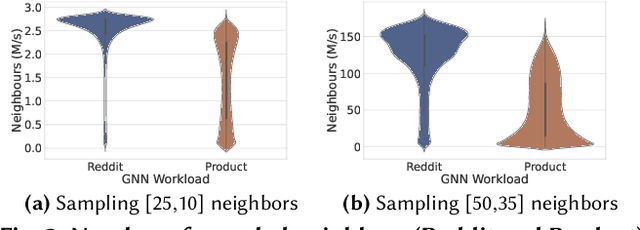
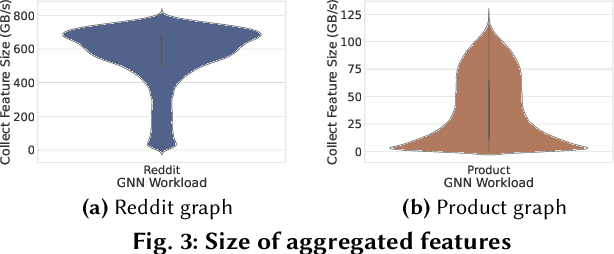
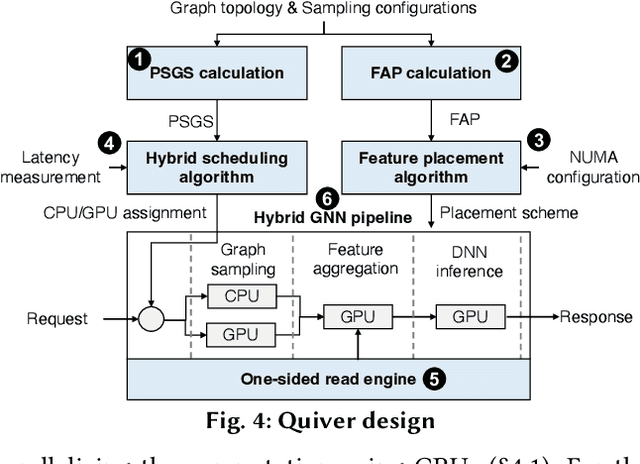
Systems for serving inference requests on graph neural networks (GNN) must combine low latency with high throughout, but they face irregular computation due to skew in the number of sampled graph nodes and aggregated GNN features. This makes it challenging to exploit GPUs effectively: using GPUs to sample only a few graph nodes yields lower performance than CPU-based sampling; and aggregating many features exhibits high data movement costs between GPUs and CPUs. Therefore, current GNN serving systems use CPUs for graph sampling and feature aggregation, limiting throughput. We describe Quiver, a distributed GPU-based GNN serving system with low-latency and high-throughput. Quiver's key idea is to exploit workload metrics for predicting the irregular computation of GNN requests, and governing the use of GPUs for graph sampling and feature aggregation: (1) for graph sampling, Quiver calculates the probabilistic sampled graph size, a metric that predicts the degree of parallelism in graph sampling. Quiver uses this metric to assign sampling tasks to GPUs only when the performance gains surpass CPU-based sampling; and (2) for feature aggregation, Quiver relies on the feature access probability to decide which features to partition and replicate across a distributed GPU NUMA topology. We show that Quiver achieves up to 35 times lower latency with an 8 times higher throughput compared to state-of-the-art GNN approaches (DGL and PyG).