 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScepsy: Serving Agentic Workflows Using Aggregate LLM Pipelines
Apr 16, 2026Agentic workflows carry out complex tasks by orchestrating multiple large language models (LLMs) and tools. Serving such workflows at a target throughput with low latency is challenging because they can be defined using arbitrary agentic frameworks and exhibit unpredictable execution times: execution may branch, fan-out, or recur in data-dependent ways. Since LLMs in workflows often outnumber available GPUs, their execution also leads to GPU oversubscription. We describe Scepsy, a new agentic serving system that efficiently schedules arbitrary multi-LLM agentic workflows onto a GPU cluster. Scepsy exploits the insight that, while agentic workflows have unpredictable end-to-end latencies, the shares of each LLM's total execution times are comparatively stable across executions. Scepsy decides on GPU allocations based on these aggregate shares: first, it profiles the LLMs under different parallelism degrees. It then uses these statistics to construct an Aggregate LLM Pipeline, which is a lightweight latency/throughput predictor for allocations. To find a GPU allocation that minimizes latency while achieving a target throughput, Scepsy uses the Aggregate LLM Pipeline to explore a search space over fractional GPU shares, tensor parallelism degrees, and replica counts. It uses a hierarchical heuristic to place the best allocation onto the GPU cluster, minimizing fragmentation, while respecting network topology constraints. Our evaluation on realistic agentic workflows shows that Scepsy achieves up to 2.4x higher throughput and 27x lower latency compared to systems that optimize LLMs independently or rely on user-specified allocations.
TimeRL: Efficient Deep Reinforcement Learning with Polyhedral Dependence Graphs
Jan 09, 2025



Modern deep learning (DL) workloads increasingly use complex deep reinforcement learning (DRL) algorithms that generate training data within the learning loop. This results in programs with several nested loops and dynamic data dependencies between tensors. While DL systems with eager execution support such dynamism, they lack the optimizations and smart scheduling of graph-based execution. Graph-based execution, however, cannot express dynamic tensor shapes, instead requiring the use of multiple static subgraphs. Either execution model for DRL thus leads to redundant computation, reduced parallelism, and less efficient memory management. We describe TimeRL, a system for executing dynamic DRL programs that combines the dynamism of eager execution with the whole-program optimizations and scheduling of graph-based execution. TimeRL achieves this by introducing the declarative programming model of recurrent tensors, which allows users to define dynamic dependencies as intuitive recurrence equations. TimeRL translates recurrent tensors into a polyhedral dependence graph (PDG) with dynamic dependencies as symbolic expressions. Through simple PDG transformations, TimeRL applies whole-program optimizations, such as automatic vectorization, incrementalization, and operator fusion. The PDG also allows for the computation of an efficient program-wide execution schedule, which decides on buffer deallocations, buffer donations, and GPU/CPU memory swapping. We show that TimeRL executes current DRL algorithms up to 47$\times$ faster than existing DRL systems, while using 16$\times$ less GPU peak memory.
ExclaveFL: Providing Transparency to Federated Learning using Exclaves
Dec 13, 2024
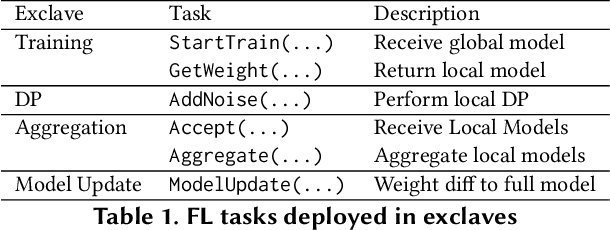


In federated learning (FL), data providers jointly train a model without disclosing their training data. Despite its privacy benefits, a malicious data provider can simply deviate from the correct training protocol without being detected, thus attacking the trained model. While current solutions have explored the use of trusted execution environment (TEEs) to combat such attacks, there is a mismatch with the security needs of FL: TEEs offer confidentiality guarantees, which are unnecessary for FL and make them vulnerable to side-channel attacks, and focus on coarse-grained attestation, which does not capture the execution of FL training. We describe ExclaveFL, an FL platform that achieves end-to-end transparency and integrity for detecting attacks. ExclaveFL achieves this by employing a new hardware security abstraction, exclaves, which focus on integrity-only guarantees. ExclaveFL uses exclaves to protect the execution of FL tasks, while generating signed statements containing fine-grained, hardware-based attestation reports of task execution at runtime. ExclaveFL then enables auditing using these statements to construct an attested dataflow graph and then check that the FL training jobs satisfies claims, such as the absence of attacks. Our experiments show that ExclaveFL introduces a less than 9% overhead while detecting a wide-range of attacks.
TENPLEX: Changing Resources of Deep Learning Jobs using Parallelizable Tensor Collections
Dec 08, 2023Deep learning (DL) jobs use multi-dimensional parallelism, i.e they combine data, model, and pipeline parallelism, to use large GPU clusters efficiently. This couples jobs tightly to a set of GPU devices, but jobs may experience changes to the device allocation: (i) resource elasticity during training adds or removes devices; (ii) hardware maintenance may require redeployment on different devices; and (iii) device failures force jobs to run with fewer devices. Current DL frameworks lack support for these scenarios, as they cannot change the multi-dimensional parallelism of an already-running job in an efficient and model-independent way. We describe Tenplex, a state management library for DL frameworks that enables jobs to change the GPU allocation and job parallelism at runtime. Tenplex achieves this by externalizing the DL job state during training as a parallelizable tensor collection (PTC). When the GPU allocation for the DL job changes, Tenplex uses the PTC to transform the DL job state: for the dataset state, Tenplex repartitions it under data parallelism and exposes it to workers through a virtual file system; for the model state, Tenplex obtains it as partitioned checkpoints and transforms them to reflect the new parallelization configuration. For efficiency, these PTC transformations are executed in parallel with a minimum amount of data movement between devices and workers. Our experiments show that Tenplex enables DL jobs to support dynamic parallelization with low overhead.
Quiver: Supporting GPUs for Low-Latency, High-Throughput GNN Serving with Workload Awareness
May 18, 2023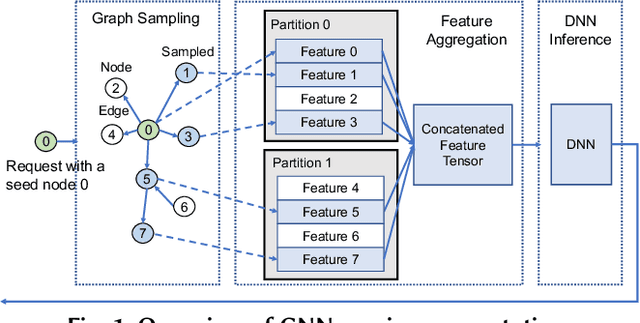
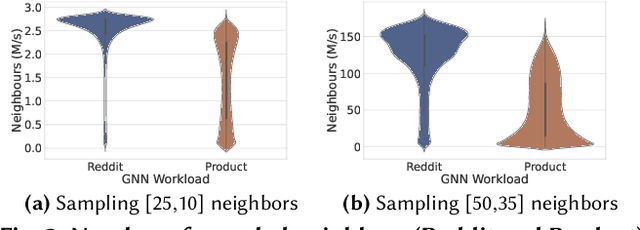
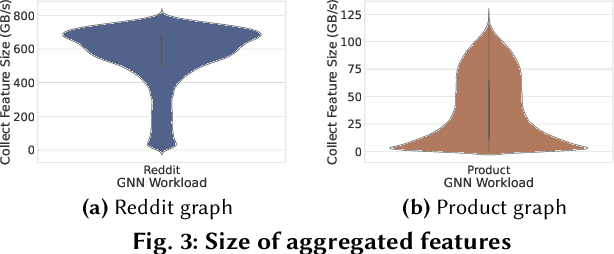
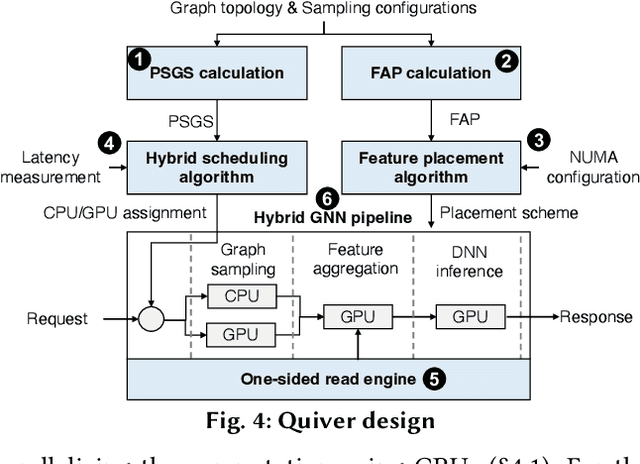
Systems for serving inference requests on graph neural networks (GNN) must combine low latency with high throughout, but they face irregular computation due to skew in the number of sampled graph nodes and aggregated GNN features. This makes it challenging to exploit GPUs effectively: using GPUs to sample only a few graph nodes yields lower performance than CPU-based sampling; and aggregating many features exhibits high data movement costs between GPUs and CPUs. Therefore, current GNN serving systems use CPUs for graph sampling and feature aggregation, limiting throughput. We describe Quiver, a distributed GPU-based GNN serving system with low-latency and high-throughput. Quiver's key idea is to exploit workload metrics for predicting the irregular computation of GNN requests, and governing the use of GPUs for graph sampling and feature aggregation: (1) for graph sampling, Quiver calculates the probabilistic sampled graph size, a metric that predicts the degree of parallelism in graph sampling. Quiver uses this metric to assign sampling tasks to GPUs only when the performance gains surpass CPU-based sampling; and (2) for feature aggregation, Quiver relies on the feature access probability to decide which features to partition and replicate across a distributed GPU NUMA topology. We show that Quiver achieves up to 35 times lower latency with an 8 times higher throughput compared to state-of-the-art GNN approaches (DGL and PyG).
MSRL: Distributed Reinforcement Learning with Dataflow Fragments
Oct 03, 2022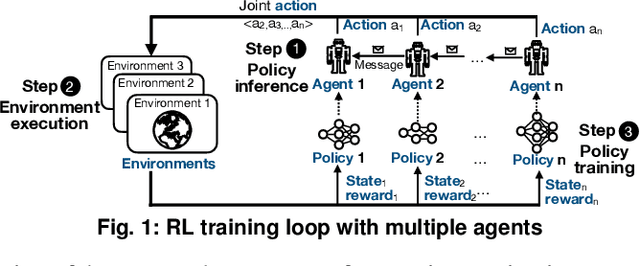
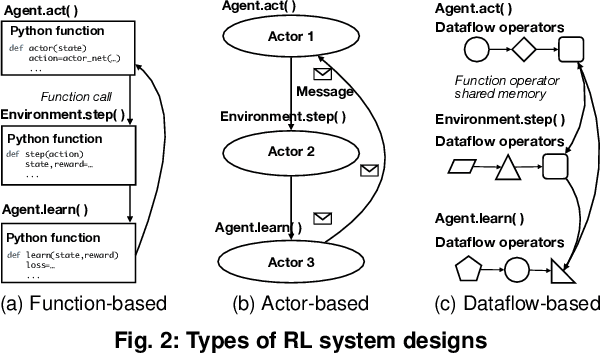
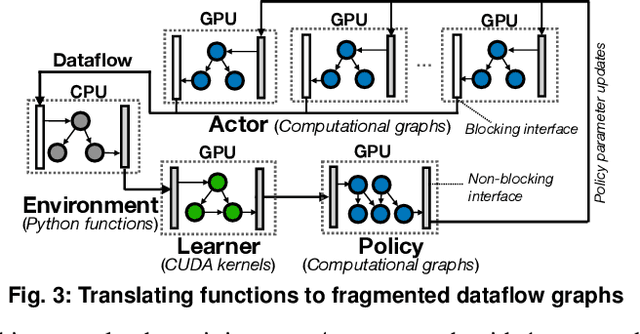
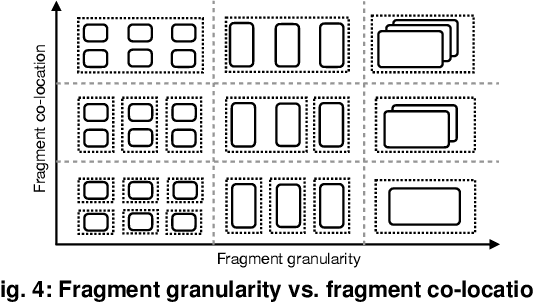
Reinforcement learning~(RL) trains many agents, which is resource-intensive and must scale to large GPU clusters. Different RL training algorithms offer different opportunities for distributing and parallelising the computation. Yet, current distributed RL systems tie the definition of RL algorithms to their distributed execution: they hard-code particular distribution strategies and only accelerate specific parts of the computation (e.g. policy network updates) on GPU workers. Fundamentally, current systems lack abstractions that decouple RL algorithms from their execution. We describe MindSpore Reinforcement Learning (MSRL), a distributed RL training system that supports distribution policies that govern how RL training computation is parallelised and distributed on cluster resources, without requiring changes to the algorithm implementation. MSRL introduces the new abstraction of a fragmented dataflow graph, which maps Python functions from an RL algorithm's training loop to parallel computational fragments. Fragments are executed on different devices by translating them to low-level dataflow representations, e.g. computational graphs as supported by deep learning engines, CUDA implementations or multi-threaded CPU processes. We show that MSRL subsumes the distribution strategies of existing systems, while scaling RL training to 64 GPUs.
CROSSBOW: Scaling Deep Learning with Small Batch Sizes on Multi-GPU Servers
Jan 08, 2019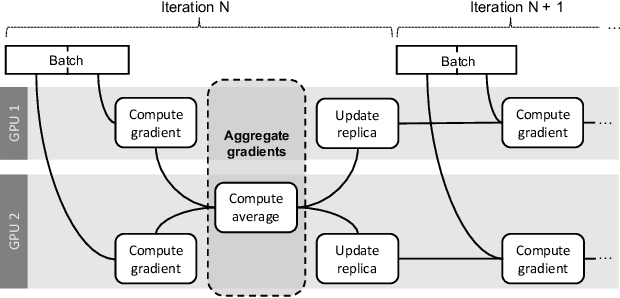

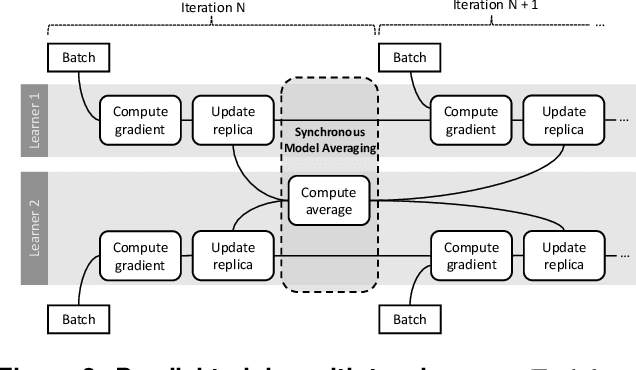
Deep learning models are trained on servers with many GPUs, and training must scale with the number of GPUs. Systems such as TensorFlow and Caffe2 train models with parallel synchronous stochastic gradient descent: they process a batch of training data at a time, partitioned across GPUs, and average the resulting partial gradients to obtain an updated global model. To fully utilise all GPUs, systems must increase the batch size, which hinders statistical efficiency. Users tune hyper-parameters such as the learning rate to compensate for this, which is complex and model-specific. We describe CROSSBOW, a new single-server multi-GPU system for training deep learning models that enables users to freely choose their preferred batch size - however small - while scaling to multiple GPUs. CROSSBOW uses many parallel model replicas and avoids reduced statistical efficiency through a new synchronous training method. We introduce SMA, a synchronous variant of model averaging in which replicas independently explore the solution space with gradient descent, but adjust their search synchronously based on the trajectory of a globally-consistent average model. CROSSBOW achieves high hardware efficiency with small batch sizes by potentially training multiple model replicas per GPU, automatically tuning the number of replicas to maximise throughput. Our experiments show that CROSSBOW improves the training time of deep learning models on an 8-GPU server by 1.3-4x compared to TensorFlow.