 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtomic Trajectory Modeling with State Space Models for Biomolecular Dynamics
Mar 18, 2026Understanding the dynamic behavior of biomolecules is fundamental to elucidating biological function and facilitating drug discovery. While Molecular Dynamics (MD) simulations provide a rigorous physical basis for studying these dynamics, they remain computationally expensive for long timescales. Conversely, recent deep generative models accelerate conformation generation but are typically either failing to model temporal relationship or built only for monomeric proteins. To bridge this gap, we introduce ATMOS, a novel generative framework based on State Space Models (SSM) designed to generate atom-level MD trajectories for biomolecular systems. ATMOS integrates a Pairformer-based state transition mechanism to capture long-range temporal dependencies, with a diffusion-based module to decode trajectory frames in an autoregressive manner. ATMOS is trained across crystal structures from PDB and conformation trajectory from large-scale MD simulation datasets including mdCATH and MISATO. We demonstrate that ATMOS achieves state-of-the-art performance in generating conformation trajectories for both protein monomers and complex protein-ligand systems. By enabling efficient inference of atomic trajectory of motions, this work establishes a promising foundation for modeling biomolecular dynamics.
HalluGuard: Demystifying Data-Driven and Reasoning-Driven Hallucinations in LLMs
Jan 26, 2026The reliability of Large Language Models (LLMs) in high-stakes domains such as healthcare, law, and scientific discovery is often compromised by hallucinations. These failures typically stem from two sources: data-driven hallucinations and reasoning-driven hallucinations. However, existing detection methods usually address only one source and rely on task-specific heuristics, limiting their generalization to complex scenarios. To overcome these limitations, we introduce the Hallucination Risk Bound, a unified theoretical framework that formally decomposes hallucination risk into data-driven and reasoning-driven components, linked respectively to training-time mismatches and inference-time instabilities. This provides a principled foundation for analyzing how hallucinations emerge and evolve. Building on this foundation, we introduce HalluGuard, an NTK-based score that leverages the induced geometry and captured representations of the NTK to jointly identify data-driven and reasoning-driven hallucinations. We evaluate HalluGuard on 10 diverse benchmarks, 11 competitive baselines, and 9 popular LLM backbones, consistently achieving state-of-the-art performance in detecting diverse forms of LLM hallucinations.
IIR-VLM: In-Context Instance-level Recognition for Large Vision-Language Models
Jan 20, 2026Instance-level recognition (ILR) concerns distinguishing individual instances from one another, with person re-identification as a prominent example. Despite the impressive visual perception capabilities of modern VLMs, we find their performance on ILR unsatisfactory, often dramatically underperforming domain-specific ILR models. This limitation hinders many practical application of VLMs, e.g. where recognizing familiar people and objects is crucial for effective visual understanding. Existing solutions typically learn to recognize instances one at a time using instance-specific datasets, which not only incur substantial data collection and training costs but also struggle with fine-grained discrimination. In this work, we propose IIR-VLM, a VLM enhanced for In-context Instance-level Recognition. We integrate pre-trained ILR expert models as auxiliary visual encoders to provide specialized features for learning diverse instances, which enables VLMs to learn new instances in-context in a one-shot manner. Further, IIR-VLM leverages this knowledge for instance-aware visual understanding. We validate IIR-VLM's efficacy on existing instance personalization benchmarks. Finally, we demonstrate its superior ILR performance on a challenging new benchmark, which assesses ILR capabilities across varying difficulty and diverse categories, with person, face, pet and general objects as the instances at task.
Perception Characteristics Distance: Measuring Stability and Robustness of Perception System in Dynamic Conditions under a Certain Decision Rule
Jun 10, 2025



The performance of perception systems in autonomous driving systems (ADS) is strongly influenced by object distance, scene dynamics, and environmental conditions such as weather. AI-based perception outputs are inherently stochastic, with variability driven by these external factors, while traditional evaluation metrics remain static and event-independent, failing to capture fluctuations in confidence over time. In this work, we introduce the Perception Characteristics Distance (PCD) -- a novel evaluation metric that quantifies the farthest distance at which an object can be reliably detected, incorporating uncertainty in model outputs. To support this, we present the SensorRainFall dataset, collected on the Virginia Smart Road using a sensor-equipped vehicle (cameras, radar, LiDAR) under controlled daylight-clear and daylight-rain scenarios, with precise ground-truth distances to the target objects. Statistical analysis reveals the presence of change points in the variance of detection confidence score with distance. By averaging the PCD values across a range of detection quality thresholds and probabilistic thresholds, we compute the mean PCD (mPCD), which captures the overall perception characteristics of a system with respect to detection distance. Applying state-of-the-art perception models shows that mPCD captures meaningful reliability differences under varying weather conditions -- differences that static metrics overlook. PCD provides a principled, distribution-aware measure of perception performance, supporting safer and more robust ADS operation, while the SensorRainFall dataset offers a valuable benchmark for evaluation. The SensorRainFall dataset is publicly available at https://www.kaggle.com/datasets/datadrivenwheels/sensorrainfall, and the evaluation code is open-sourced at https://github.com/datadrivenwheels/PCD_Python.
Restereo: Diffusion stereo video generation and restoration
Jun 06, 2025Stereo video generation has been gaining increasing attention with recent advancements in video diffusion models. However, most existing methods focus on generating 3D stereoscopic videos from monocular 2D videos. These approaches typically assume that the input monocular video is of high quality, making the task primarily about inpainting occluded regions in the warped video while preserving disoccluded areas. In this paper, we introduce a new pipeline that not only generates stereo videos but also enhances both left-view and right-view videos consistently with a single model. Our approach achieves this by fine-tuning the model on degraded data for restoration, as well as conditioning the model on warped masks for consistent stereo generation. As a result, our method can be fine-tuned on a relatively small synthetic stereo video datasets and applied to low-quality real-world videos, performing both stereo video generation and restoration. Experiments demonstrate that our method outperforms existing approaches both qualitatively and quantitatively in stereo video generation from low-resolution inputs.
ExpertGen: Training-Free Expert Guidance for Controllable Text-to-Face Generation
May 22, 2025Recent advances in diffusion models have significantly improved text-to-face generation, but achieving fine-grained control over facial features remains a challenge. Existing methods often require training additional modules to handle specific controls such as identity, attributes, or age, making them inflexible and resource-intensive. We propose ExpertGen, a training-free framework that leverages pre-trained expert models such as face recognition, facial attribute recognition, and age estimation networks to guide generation with fine control. Our approach uses a latent consistency model to ensure realistic and in-distribution predictions at each diffusion step, enabling accurate guidance signals to effectively steer the diffusion process. We show qualitatively and quantitatively that expert models can guide the generation process with high precision, and multiple experts can collaborate to enable simultaneous control over diverse facial aspects. By allowing direct integration of off-the-shelf expert models, our method transforms any such model into a plug-and-play component for controllable face generation.
SynSHRP2: A Synthetic Multimodal Benchmark for Driving Safety-critical Events Derived from Real-world Driving Data
May 06, 2025Driving-related safety-critical events (SCEs), including crashes and near-crashes, provide essential insights for the development and safety evaluation of automated driving systems. However, two major challenges limit their accessibility: the rarity of SCEs and the presence of sensitive privacy information in the data. The Second Strategic Highway Research Program (SHRP 2) Naturalistic Driving Study (NDS), the largest NDS to date, collected millions of hours of multimodal, high-resolution, high-frequency driving data from thousands of participants, capturing thousands of SCEs. While this dataset is invaluable for safety research, privacy concerns and data use restrictions significantly limit public access to the raw data. To address these challenges, we introduce SynSHRP2, a publicly available, synthetic, multimodal driving dataset containing over 1874 crashes and 6924 near-crashes derived from the SHRP 2 NDS. The dataset features de-identified keyframes generated using Stable Diffusion and ControlNet, ensuring the preservation of critical safety-related information while eliminating personally identifiable data. Additionally, SynSHRP2 includes detailed annotations on SCE type, environmental and traffic conditions, and time-series kinematic data spanning 5 seconds before and during each event. Synchronized keyframes and narrative descriptions further enhance its usability. This paper presents two benchmarks for event attribute classification and scene understanding, demonstrating the potential applications of SynSHRP2 in advancing safety research and automated driving system development.
Are Vision LLMs Road-Ready? A Comprehensive Benchmark for Safety-Critical Driving Video Understanding
Apr 20, 2025Vision Large Language Models (VLLMs) have demonstrated impressive capabilities in general visual tasks such as image captioning and visual question answering. However, their effectiveness in specialized, safety-critical domains like autonomous driving remains largely unexplored. Autonomous driving systems require sophisticated scene understanding in complex environments, yet existing multimodal benchmarks primarily focus on normal driving conditions, failing to adequately assess VLLMs' performance in safety-critical scenarios. To address this, we introduce DVBench, a pioneering benchmark designed to evaluate the performance of VLLMs in understanding safety-critical driving videos. Built around a hierarchical ability taxonomy that aligns with widely adopted frameworks for describing driving scenarios used in assessing highly automated driving systems, DVBench features 10,000 multiple-choice questions with human-annotated ground-truth answers, enabling a comprehensive evaluation of VLLMs' capabilities in perception and reasoning. Experiments on 14 SOTA VLLMs, ranging from 0.5B to 72B parameters, reveal significant performance gaps, with no model achieving over 40% accuracy, highlighting critical limitations in understanding complex driving scenarios. To probe adaptability, we fine-tuned selected models using domain-specific data from DVBench, achieving accuracy gains ranging from 5.24 to 10.94 percentage points, with relative improvements of up to 43.59%. This improvement underscores the necessity of targeted adaptation to bridge the gap between general-purpose VLLMs and mission-critical driving applications. DVBench establishes an essential evaluation framework and research roadmap for developing VLLMs that meet the safety and robustness requirements for real-world autonomous systems. We released the benchmark toolbox and the fine-tuned model at: https://github.com/tong-zeng/DVBench.git.
Review of Mathematical Optimization in Federated Learning
Dec 02, 2024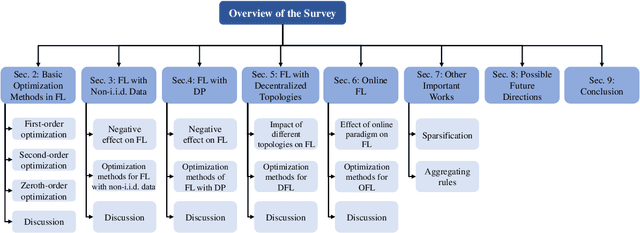
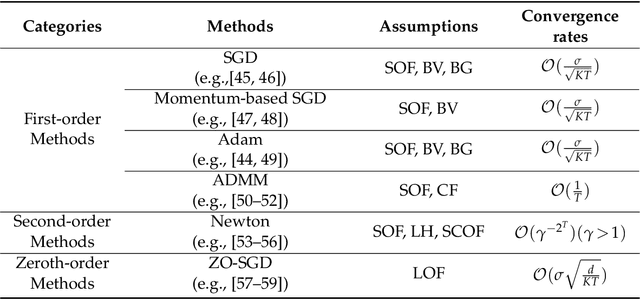
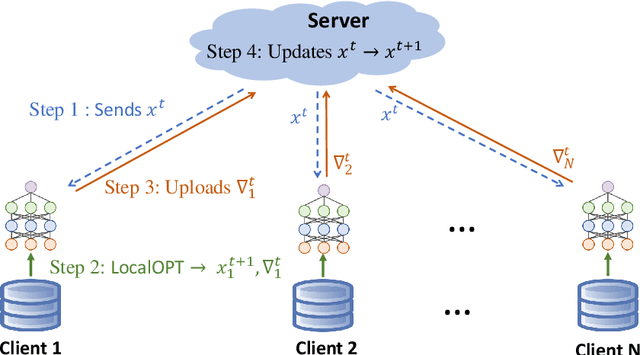

Federated Learning (FL) has been becoming a popular interdisciplinary research area in both applied mathematics and information sciences. Mathematically, FL aims to collaboratively optimize aggregate objective functions over distributed datasets while satisfying a variety of privacy and system constraints.Different from conventional distributed optimization methods, FL needs to address several specific issues (e.g., non-i.i.d. data distributions and differential private noises), which pose a set of new challenges in the problem formulation, algorithm design, and convergence analysis. In this paper, we will systematically review existing FL optimization research including their assumptions, formulations, methods, and theoretical results. Potential future directions are also discussed.
ScVLM: a Vision-Language Model for Driving Safety Critical Event Understanding
Oct 01, 2024Accurately identifying, understanding, and describing driving safety-critical events (SCEs), including crashes and near-crashes, is crucial for traffic safety, automated driving systems, and advanced driver assistance systems research and application. As SCEs are rare events, most general Vision-Language Models (VLMs) have not been trained sufficiently to link SCE videos and narratives, which could lead to hallucination and missing key safety characteristics. To tackle these challenges, we propose ScVLM, a hybrid approach that combines supervised learning and contrastive learning to improve driving video understanding and event description rationality for VLMs. The proposed approach is trained on and evaluated by more than 8,600 SCEs from the Second Strategic Highway Research Program Naturalistic Driving Study dataset, the largest publicly accessible driving dataset with videos and SCE annotations. The results demonstrate the superiority of the proposed approach in generating contextually accurate event descriptions and mitigate hallucinations from VLMs.