 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairGFL: Privacy-Preserving Fairness-Aware Federated Learning with Overlapping Subgraphs
Dec 29, 2025Graph federated learning enables the collaborative extraction of high-order information from distributed subgraphs while preserving the privacy of raw data. However, graph data often exhibits overlap among different clients. Previous research has demonstrated certain benefits of overlapping data in mitigating data heterogeneity. However, the negative effects have not been explored, particularly in cases where the overlaps are imbalanced across clients. In this paper, we uncover the unfairness issue arising from imbalanced overlapping subgraphs through both empirical observations and theoretical reasoning. To address this issue, we propose FairGFL (FAIRness-aware subGraph Federated Learning), a novel algorithm that enhances cross-client fairness while maintaining model utility in a privacy-preserving manner. Specifically, FairGFL incorporates an interpretable weighted aggregation approach to enhance fairness across clients, leveraging privacy-preserving estimation of their overlapping ratios. Furthermore, FairGFL improves the tradeoff between model utility and fairness by integrating a carefully crafted regularizer into the federated composite loss function. Through extensive experiments on four benchmark graph datasets, we demonstrate that FairGFL outperforms four representative baseline algorithms in terms of both model utility and fairness.
Rethinking Layer-wise Gaussian Noise Injection: Bridging Implicit Objectives and Privacy Budget Allocation
Sep 04, 2025
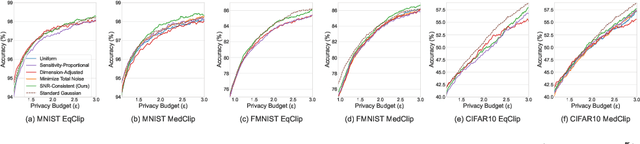
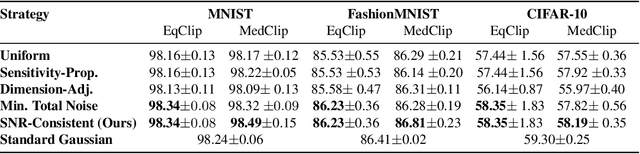
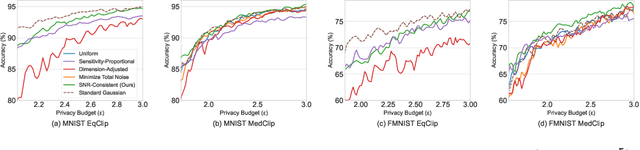
Layer-wise Gaussian mechanisms (LGM) enhance flexibility in differentially private deep learning by injecting noise into partitioned gradient vectors. However, existing methods often rely on heuristic noise allocation strategies, lacking a rigorous understanding of their theoretical grounding in connecting noise allocation to formal privacy-utility tradeoffs. In this paper, we present a unified analytical framework that systematically connects layer-wise noise injection strategies with their implicit optimization objectives and associated privacy budget allocations. Our analysis reveals that several existing approaches optimize ill-posed objectives -- either ignoring inter-layer signal-to-noise ratio (SNR) consistency or leading to inefficient use of the privacy budget. In response, we propose a SNR-Consistent noise allocation strategy that unifies both aspects, yielding a noise allocation scheme that achieves better signal preservation and more efficient privacy budget utilization. Extensive experiments in both centralized and federated learning settings demonstrate that our method consistently outperforms existing allocation strategies, achieving better privacy-utility tradeoffs. Our framework not only offers diagnostic insights into prior methods but also provides theoretical guidance for designing adaptive and effective noise injection schemes in deep models.
TelOps: AI-driven Operations and Maintenance for Telecommunication Networks
Dec 06, 2024Telecommunication Networks (TNs) have become the most important infrastructure for data communications over the last century. Operations and maintenance (O&M) is extremely important to ensure the availability, effectiveness, and efficiency of TN communications. Different from the popular O&M technique for IT systems (e.g., the cloud), artificial intelligence for IT Operations (AIOps), O&M for TNs meets the following three fundamental challenges: topological dependence of network components, highly heterogeneous software, and restricted failure data. This article presents TelOps, the first AI-driven O&M framework for TNs, systematically enhanced with mechanism, data, and empirical knowledge. We provide a comprehensive comparison between TelOps and AIOps, and conduct a proof-of-concept case study on a typical O&M task (failure diagnosis) for a real industrial TN. As the first systematic AI-driven O&M framework for TNs, TelOps opens a new door to applying AI techniques to TN automation.
* 7 pages, 4 figures, magazine
Review of Mathematical Optimization in Federated Learning
Dec 02, 2024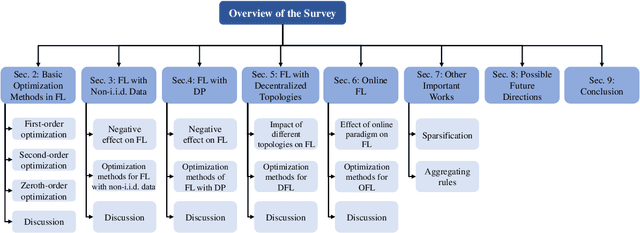
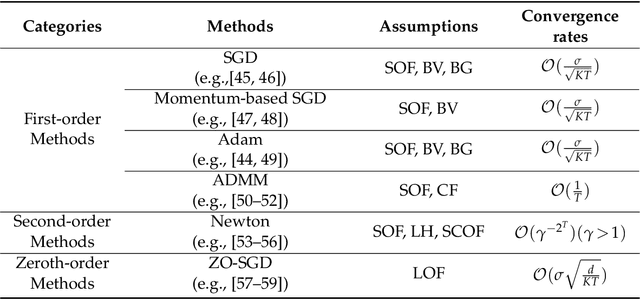
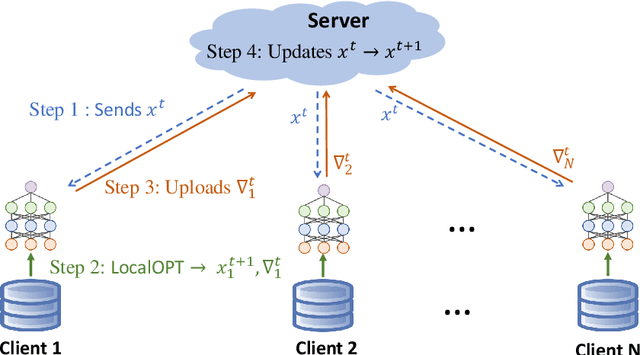

Federated Learning (FL) has been becoming a popular interdisciplinary research area in both applied mathematics and information sciences. Mathematically, FL aims to collaboratively optimize aggregate objective functions over distributed datasets while satisfying a variety of privacy and system constraints.Different from conventional distributed optimization methods, FL needs to address several specific issues (e.g., non-i.i.d. data distributions and differential private noises), which pose a set of new challenges in the problem formulation, algorithm design, and convergence analysis. In this paper, we will systematically review existing FL optimization research including their assumptions, formulations, methods, and theoretical results. Potential future directions are also discussed.
LibEER: A Comprehensive Benchmark and Algorithm Library for EEG-based Emotion Recognition
Oct 13, 2024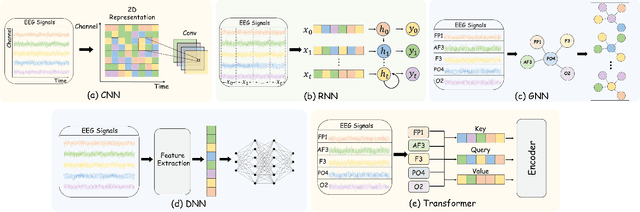
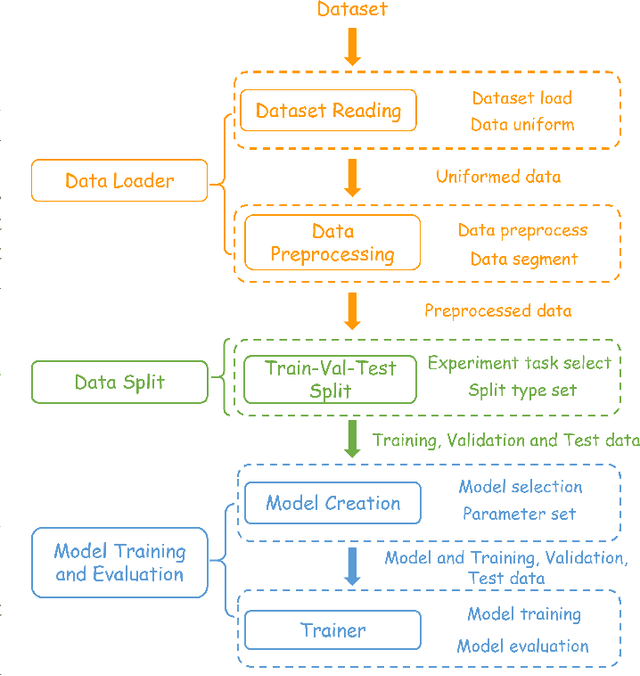
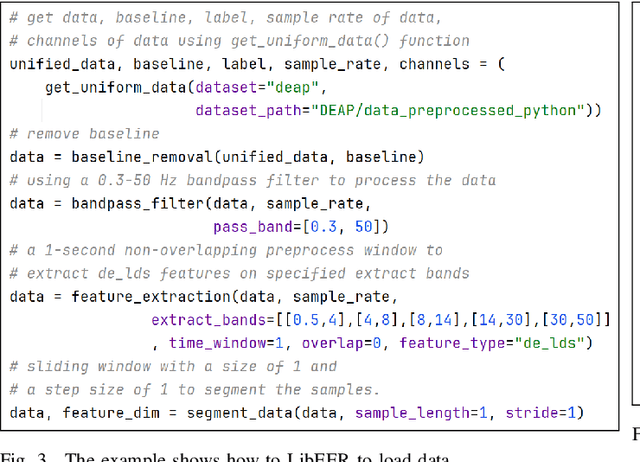
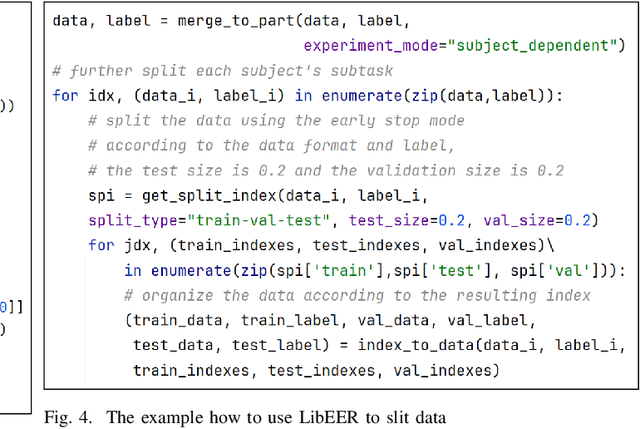
EEG-based emotion recognition (EER) is garnering increasing attention due to its potential in understanding and analyzing human emotions. Recently, significant advancements have been achieved using various deep learning-based techniques to address the EER problem. However, the absence of a convincing benchmark and open-source codebase complicates fair comparisons between different models and poses reproducibility challenges for practitioners. These issues considerably impede progress in this field. In light of this, we propose a comprehensive benchmark and algorithm library (LibEER) for fair comparisons in EER by making most of the implementation details of different methods consistent and using the same single codebase in PyTorch. In response to these challenges, we propose LibEER, a comprehensive benchmark and algorithm library for fair comparisons in EER, by ensuring consistency in the implementation details of various methods and utilizing a single codebase in PyTorch. LibEER establishes a unified evaluation framework with standardized experimental settings, enabling unbiased evaluations of over ten representative deep learning-based EER models across the four most commonly used datasets. Additionally, we conduct an exhaustive and reproducible comparison of the performance and efficiency of popular models, providing valuable insights for researchers in selecting and designing EER models. We aspire for our work to not only lower the barriers for beginners entering the field of EEG-based emotion recognition but also promote the standardization of research in this domain, thereby fostering steady development. The source code is available at \url{https://github.com/ButterSen/LibEER}.
Understanding Byzantine Robustness in Federated Learning with A Black-box Server
Aug 12, 2024Federated learning (FL) becomes vulnerable to Byzantine attacks where some of participators tend to damage the utility or discourage the convergence of the learned model via sending their malicious model updates. Previous works propose to apply robust rules to aggregate updates from participators against different types of Byzantine attacks, while at the same time, attackers can further design advanced Byzantine attack algorithms targeting specific aggregation rule when it is known. In practice, FL systems can involve a black-box server that makes the adopted aggregation rule inaccessible to participants, which can naturally defend or weaken some Byzantine attacks. In this paper, we provide an in-depth understanding on the Byzantine robustness of the FL system with a black-box server. Our investigation demonstrates the improved Byzantine robustness of a black-box server employing a dynamic defense strategy. We provide both empirical evidence and theoretical analysis to reveal that the black-box server can mitigate the worst-case attack impact from a maximum level to an expectation level, which is attributed to the inherent inaccessibility and randomness offered by a black-box server.The source code is available at https://github.com/alibaba/FederatedScope/tree/Byzantine_attack_defense to promote further research in the community.
FedLED: Label-Free Equipment Fault Diagnosis with Vertical Federated Transfer Learning
Dec 29, 2023



Intelligent equipment fault diagnosis based on Federated Transfer Learning (FTL) attracts considerable attention from both academia and industry. It allows real-world industrial agents with limited samples to construct a fault diagnosis model without jeopardizing their raw data privacy. Existing approaches, however, can neither address the intense sample heterogeneity caused by different working conditions of practical agents, nor the extreme fault label scarcity, even zero, of newly deployed equipment. To address these issues, we present FedLED, the first unsupervised vertical FTL equipment fault diagnosis method, where knowledge of the unlabeled target domain is further exploited for effective unsupervised model transfer. Results of extensive experiments using data of real equipment monitoring demonstrate that FedLED obviously outperforms SOTA approaches in terms of both diagnosis accuracy (up to 4.13 times) and generality. We expect our work to inspire further study on label-free equipment fault diagnosis systematically enhanced by target domain knowledge.
Generative Model-based Feature Knowledge Distillation for Action Recognition
Dec 14, 2023Knowledge distillation (KD), a technique widely employed in computer vision, has emerged as a de facto standard for improving the performance of small neural networks. However, prevailing KD-based approaches in video tasks primarily focus on designing loss functions and fusing cross-modal information. This overlooks the spatial-temporal feature semantics, resulting in limited advancements in model compression. Addressing this gap, our paper introduces an innovative knowledge distillation framework, with the generative model for training a lightweight student model. In particular, the framework is organized into two steps: the initial phase is Feature Representation, wherein a generative model-based attention module is trained to represent feature semantics; Subsequently, the Generative-based Feature Distillation phase encompasses both Generative Distillation and Attention Distillation, with the objective of transferring attention-based feature semantics with the generative model. The efficacy of our approach is demonstrated through comprehensive experiments on diverse popular datasets, proving considerable enhancements in video action recognition task. Moreover, the effectiveness of our proposed framework is validated in the context of more intricate video action detection task. Our code is available at https://github.com/aaai-24/Generative-based-KD.
Weakly-Supervised Action Localization by Hierarchically-structured Latent Attention Modeling
Aug 19, 2023Weakly-supervised action localization aims to recognize and localize action instancese in untrimmed videos with only video-level labels. Most existing models rely on multiple instance learning(MIL), where the predictions of unlabeled instances are supervised by classifying labeled bags. The MIL-based methods are relatively well studied with cogent performance achieved on classification but not on localization. Generally, they locate temporal regions by the video-level classification but overlook the temporal variations of feature semantics. To address this problem, we propose a novel attention-based hierarchically-structured latent model to learn the temporal variations of feature semantics. Specifically, our model entails two components, the first is an unsupervised change-points detection module that detects change-points by learning the latent representations of video features in a temporal hierarchy based on their rates of change, and the second is an attention-based classification model that selects the change-points of the foreground as the boundaries. To evaluate the effectiveness of our model, we conduct extensive experiments on two benchmark datasets, THUMOS-14 and ActivityNet-v1.3. The experiments show that our method outperforms current state-of-the-art methods, and even achieves comparable performance with fully-supervised methods.
HiFlash: Communication-Efficient Hierarchical Federated Learning with Adaptive Staleness Control and Heterogeneity-aware Client-Edge Association
Jan 16, 2023



Federated learning (FL) is a promising paradigm that enables collaboratively learning a shared model across massive clients while keeping the training data locally. However, for many existing FL systems, clients need to frequently exchange model parameters of large data size with the remote cloud server directly via wide-area networks (WAN), leading to significant communication overhead and long transmission time. To mitigate the communication bottleneck, we resort to the hierarchical federated learning paradigm of HiFL, which reaps the benefits of mobile edge computing and combines synchronous client-edge model aggregation and asynchronous edge-cloud model aggregation together to greatly reduce the traffic volumes of WAN transmissions. Specifically, we first analyze the convergence bound of HiFL theoretically and identify the key controllable factors for model performance improvement. We then advocate an enhanced design of HiFlash by innovatively integrating deep reinforcement learning based adaptive staleness control and heterogeneity-aware client-edge association strategy to boost the system efficiency and mitigate the staleness effect without compromising model accuracy. Extensive experiments corroborate the superior performance of HiFlash in model accuracy, communication reduction, and system efficiency.