 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Provably Secure Image Steganography via Latent Iterative Optimization
Mar 10, 2026We propose a robust and provably secure image steganography framework based on latent-space iterative optimization. Within this framework, the receiver treats the transmitted image as a fixed reference and iteratively refines a latent variable to minimize the reconstruction error, thereby improving message extraction accuracy. Unlike prior methods, our approach preserves the provable security of the embedding while markedly enhancing robustness under various compression and image processing scenarios. On benchmark datasets, the experimental results demonstrate that the proposed iterative optimization not only improves robustness against image compression while preserving provable security, but can also be applied as an independent module to further reinforce robustness in other provably secure steganographic schemes. This highlights the practicality and promise of latent-space optimization for building reliable, robust, and secure steganographic systems.
DepthCropSeg++: Scaling a Crop Segmentation Foundation Model With Depth-Labeled Data
Jan 18, 2026DepthCropSeg++: a foundation model for crop segmentation, capable of segmenting different crop species under open in-field environment. Crop segmentation is a fundamental task for modern agriculture, which closely relates to many downstream tasks such as plant phenotyping, density estimation, and weed control. In the era of foundation models, a number of generic large language and vision models have been developed. These models have demonstrated remarkable real world generalization due to significant model capacity and largescale datasets. However, current crop segmentation models mostly learn from limited data due to expensive pixel-level labelling cost, often performing well only under specific crop types or controlled environment. In this work, we follow the vein of our previous work DepthCropSeg, an almost unsupervised approach to crop segmentation, to scale up a cross-species and crossscene crop segmentation dataset, with 28,406 images across 30+ species and 15 environmental conditions. We also build upon a state-of-the-art semantic segmentation architecture ViT-Adapter architecture, enhance it with dynamic upsampling for improved detail awareness, and train the model with a two-stage selftraining pipeline. To systematically validate model performance, we conduct comprehensive experiments to justify the effectiveness and generalization capabilities across multiple crop datasets. Results demonstrate that DepthCropSeg++ achieves 93.11% mIoU on a comprehensive testing set, outperforming both supervised baselines and general-purpose vision foundation models like Segmentation Anything Model (SAM) by significant margins (+0.36% and +48.57% respectively). The model particularly excels in challenging scenarios including night-time environment (86.90% mIoU), high-density canopies (90.09% mIoU), and unseen crop varieties (90.09% mIoU), indicating a new state of the art for crop segmentation.
* 13 pages, 15 figures and 7 tables
Crowded Video Individual Counting Informed by Social Grouping and Spatial-Temporal Displacement Priors
Jan 03, 2026Video Individual Counting (VIC) is a recently introduced task aiming to estimate pedestrian flux from a video. It extends Video Crowd Counting (VCC) beyond the per-frame pedestrian count. In contrast to VCC that learns to count pedestrians across frames, VIC must identify co-existent pedestrians between frames, which turns out to be a correspondence problem. Existing VIC approaches, however, can underperform in congested scenes such as metro commuting. To address this, we build WuhanMetroCrowd, one of the first VIC datasets that characterize crowded, dynamic pedestrian flows. It features sparse-to-dense density levels, short-to-long video clips, slow-to-fast flow variations, front-to-back appearance changes, and light-to-heavy occlusions. To better adapt VIC approaches to crowds, we rethink the nature of VIC and recognize two informative priors: i) the social grouping prior that indicates pedestrians tend to gather in groups and ii) the spatial-temporal displacement prior that informs an individual cannot teleport physically. The former inspires us to relax the standard one-to-one (O2O) matching used by VIC to one-to-many (O2M) matching, implemented by an implicit context generator and a O2M matcher; the latter facilitates the design of a displacement prior injector, which strengthens not only O2M matching but also feature extraction and model training. These designs jointly form a novel and strong VIC baseline OMAN++. Extensive experiments show that OMAN++ not only outperforms state-of-the-art VIC baselines on the standard SenseCrowd, CroHD, and MovingDroneCrowd benchmarks, but also indicates a clear advantage in crowded scenes, with a 38.12% error reduction on our WuhanMetroCrowd dataset. Code, data, and pretrained models are available at https://github.com/tiny-smart/OMAN.
FitControler: Toward Fit-Aware Virtual Try-On
Dec 30, 2025Realistic virtual try-on (VTON) concerns not only faithful rendering of garment details but also coordination of the style. Prior art typically pursues the former, but neglects a key factor that shapes the holistic style -- garment fit. Garment fit delineates how a garment aligns with the body of a wearer and is a fundamental element in fashion design. In this work, we introduce fit-aware VTON and present FitControler, a learnable plug-in that can seamlessly integrate into modern VTON models to enable customized fit control. To achieve this, we highlight two challenges: i) how to delineate layouts of different fits and ii) how to render the garment that matches the layout. FitControler first features a fit-aware layout generator to redraw the body-garment layout conditioned on a set of delicately processed garment-agnostic representations, and a multi-scale fit injector is then used to deliver layout cues to enable layout-driven VTON. In particular, we build a fit-aware VTON dataset termed Fit4Men, including 13,000 body-garment pairs of different fits, covering both tops and bottoms, and featuring varying camera distances and body poses. Two fit consistency metrics are also introduced to assess the fitness of generations. Extensive experiments show that FitControler can work with various VTON models and achieve accurate fit control. Code and data will be released.
Confidence-based Intent Prediction for Teleoperation in Bimanual Robotic Suturing
Apr 29, 2025Robotic-assisted procedures offer enhanced precision, but while fully autonomous systems are limited in task knowledge, difficulties in modeling unstructured environments, and generalisation abilities, fully manual teleoperated systems also face challenges such as delay, stability, and reduced sensory information. To address these, we developed an interactive control strategy that assists the human operator by predicting their motion plan at both high and low levels. At the high level, a surgeme recognition system is employed through a Transformer-based real-time gesture classification model to dynamically adapt to the operator's actions, while at the low level, a Confidence-based Intention Assimilation Controller adjusts robot actions based on user intent and shared control paradigms. The system is built around a robotic suturing task, supported by sensors that capture the kinematics of the robot and task dynamics. Experiments across users with varying skill levels demonstrated the effectiveness of the proposed approach, showing statistically significant improvements in task completion time and user satisfaction compared to traditional teleoperation.
Roadside Monocular 3D Detection via 2D Detection Prompting
Apr 04, 2024



The problem of roadside monocular 3D detection requires detecting objects of interested classes in a 2D RGB frame and predicting their 3D information such as locations in bird's-eye-view (BEV). It has broad applications in traffic control, vehicle-vehicle communication, and vehicle-infrastructure cooperative perception. To approach this problem, we present a novel and simple method by prompting the 3D detector using 2D detections. Our method builds on a key insight that, compared with 3D detectors, a 2D detector is much easier to train and performs significantly better w.r.t detections on the 2D image plane. That said, one can exploit 2D detections of a well-trained 2D detector as prompts to a 3D detector, being trained in a way of inflating such 2D detections to 3D towards 3D detection. To construct better prompts using the 2D detector, we explore three techniques: (a) concatenating both 2D and 3D detectors' features, (b) attentively fusing 2D and 3D detectors' features, and (c) encoding predicted 2D boxes x, y, width, height, label and attentively fusing such with the 3D detector's features. Surprisingly, the third performs the best. Moreover, we present a yaw tuning tactic and a class-grouping strategy that merges classes based on their functionality; these techniques improve 3D detection performance further. Comprehensive ablation studies and extensive experiments demonstrate that our method resoundingly outperforms prior works, achieving the state-of-the-art on two large-scale roadside 3D detection benchmarks.
The Neglected Tails of Vision-Language Models
Feb 02, 2024
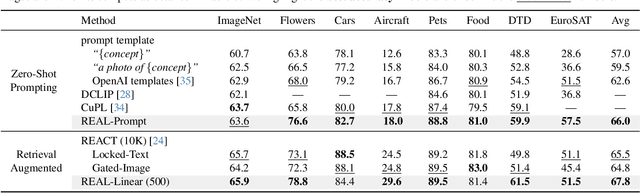

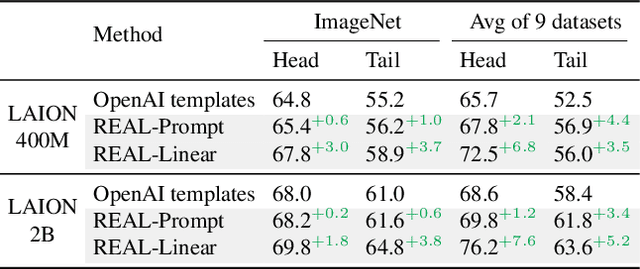
Vision-language models (VLMs) excel in zero-shot recognition but their performance varies greatly across different visual concepts. For example, although CLIP achieves impressive accuracy on ImageNet (60-80%), its performance drops below 10% for more than ten concepts like night snake, presumably due to their limited presence in the pretraining data. However, measuring the frequency of concepts in VLMs' large-scale datasets is challenging. We address this by using large language models (LLMs) to count the number of pretraining texts that contain synonyms of these concepts. Our analysis confirms that popular datasets, such as LAION, exhibit a long-tailed concept distribution, yielding biased performance in VLMs. We also find that downstream applications of VLMs, including visual chatbots (e.g., GPT-4V) and text-to-image models (e.g., Stable Diffusion), often fail to recognize or generate images of rare concepts identified by our method. To mitigate the imbalanced performance of zero-shot VLMs, we propose REtrieval-Augmented Learning (REAL). First, instead of prompting VLMs using the original class names, REAL uses their most frequent synonyms found in pretraining texts. This simple change already outperforms costly human-engineered and LLM-enriched prompts over nine benchmark datasets. Second, REAL trains a linear classifier on a small yet balanced set of pretraining data retrieved using concept synonyms. REAL surpasses the previous zero-shot SOTA, using 400x less storage and 10,000x less training time!
Long-Tailed 3D Detection via 2D Late Fusion
Dec 18, 2023Autonomous vehicles (AVs) must accurately detect objects from both common and rare classes for safe navigation, motivating the problem of Long-Tailed 3D Object Detection (LT3D). Contemporary LiDAR-based 3D detectors perform poorly on rare classes (e.g., CenterPoint only achieves 5.1 AP on stroller) as it is difficult to recognize objects from sparse LiDAR points alone. RGB images provide visual evidence to help resolve such ambiguities, motivating the study of RGB-LiDAR fusion. In this paper, we delve into a simple late-fusion framework that ensembles independently trained RGB and LiDAR detectors. Unlike recent end-to-end methods which require paired multi-modal training data, our late-fusion approach can easily leverage large-scale uni-modal datasets, significantly improving rare class detection.In particular, we examine three critical components in this late-fusion framework from first principles, including whether to train 2D or 3D RGB detectors, whether to match RGB and LiDAR detections in 3D or the projected 2D image plane, and how to fuse matched detections.Extensive experiments reveal that 2D RGB detectors achieve better recognition accuracy than 3D RGB detectors, matching on the 2D image plane mitigates depth estimation errors, and fusing scores probabilistically with calibration leads to state-of-the-art LT3D performance. Our late-fusion approach achieves 51.4 mAP on the established nuScenes LT3D benchmark, improving over prior work by 5.9 mAP.
A High-Resolution Dataset for Instance Detection with Multi-View Instance Capture
Oct 30, 2023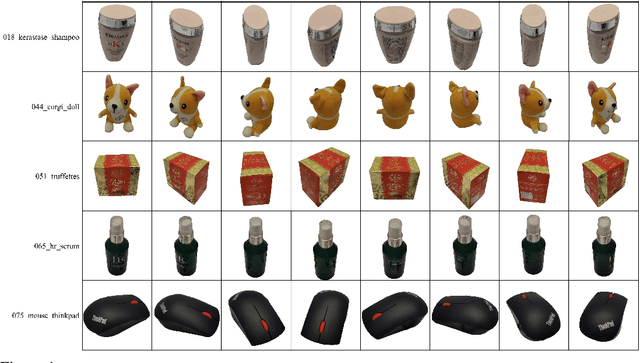
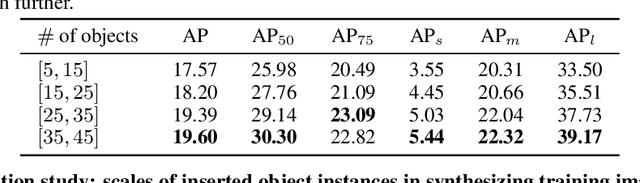
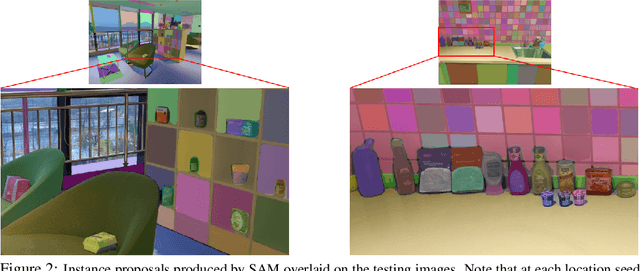
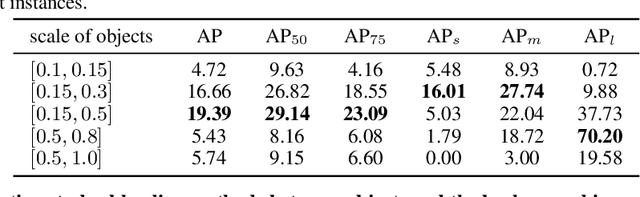
Instance detection (InsDet) is a long-lasting problem in robotics and computer vision, aiming to detect object instances (predefined by some visual examples) in a cluttered scene. Despite its practical significance, its advancement is overshadowed by Object Detection, which aims to detect objects belonging to some predefined classes. One major reason is that current InsDet datasets are too small in scale by today's standards. For example, the popular InsDet dataset GMU (published in 2016) has only 23 instances, far less than COCO (80 classes), a well-known object detection dataset published in 2014. We are motivated to introduce a new InsDet dataset and protocol. First, we define a realistic setup for InsDet: training data consists of multi-view instance captures, along with diverse scene images allowing synthesizing training images by pasting instance images on them with free box annotations. Second, we release a real-world database, which contains multi-view capture of 100 object instances, and high-resolution (6k x 8k) testing images. Third, we extensively study baseline methods for InsDet on our dataset, analyze their performance and suggest future work. Somewhat surprisingly, using the off-the-shelf class-agnostic segmentation model (Segment Anything Model, SAM) and the self-supervised feature representation DINOv2 performs the best, achieving >10 AP better than end-to-end trained InsDet models that repurpose object detectors (e.g., FasterRCNN and RetinaNet).
Prompting Scientific Names for Zero-Shot Species Recognition
Oct 15, 2023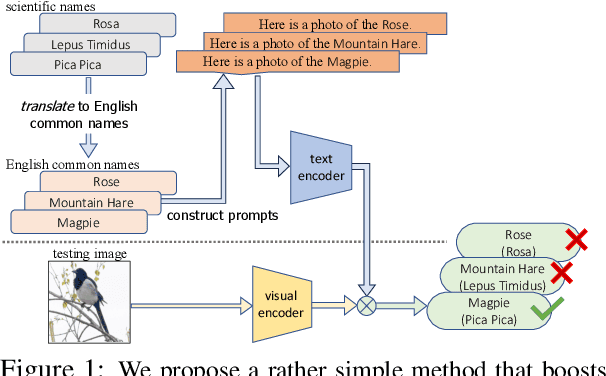
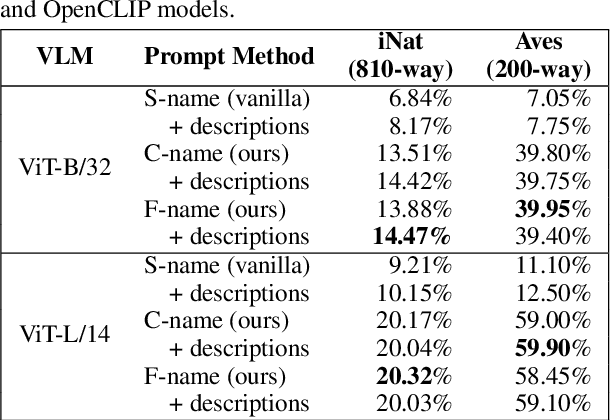

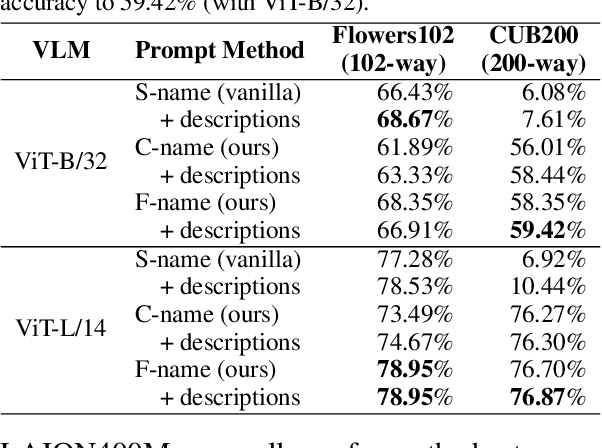
Trained on web-scale image-text pairs, Vision-Language Models (VLMs) such as CLIP can recognize images of common objects in a zero-shot fashion. However, it is underexplored how to use CLIP for zero-shot recognition of highly specialized concepts, e.g., species of birds, plants, and animals, for which their scientific names are written in Latin or Greek. Indeed, CLIP performs poorly for zero-shot species recognition with prompts that use scientific names, e.g., "a photo of Lepus Timidus" (which is a scientific name in Latin). Because these names are usually not included in CLIP's training set. To improve performance, prior works propose to use large-language models (LLMs) to generate descriptions (e.g., of species color and shape) and additionally use them in prompts. We find that they bring only marginal gains. Differently, we are motivated to translate scientific names (e.g., Lepus Timidus) to common English names (e.g., mountain hare) and use such in the prompts. We find that common names are more likely to be included in CLIP's training set, and prompting them achieves 2$\sim$5 times higher accuracy on benchmarking datasets of fine-grained species recognition.