 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting Scientific Names for Zero-Shot Species Recognition
Paper and Code
Oct 15, 2023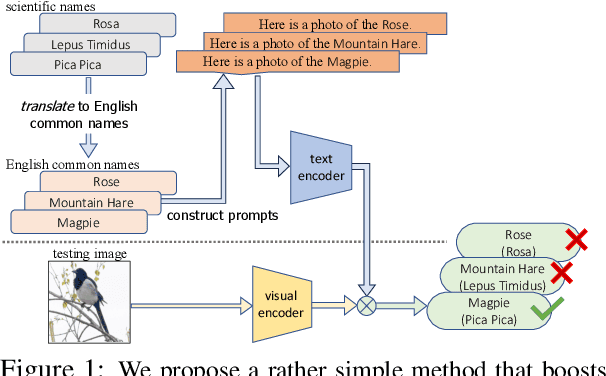
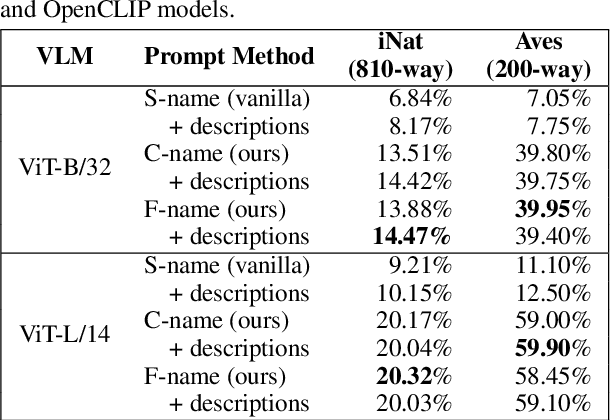

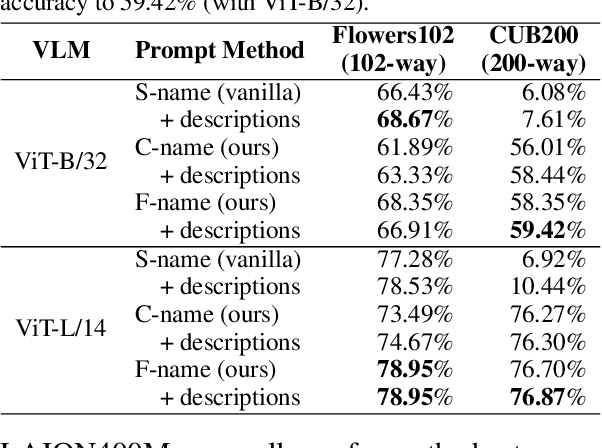
Trained on web-scale image-text pairs, Vision-Language Models (VLMs) such as CLIP can recognize images of common objects in a zero-shot fashion. However, it is underexplored how to use CLIP for zero-shot recognition of highly specialized concepts, e.g., species of birds, plants, and animals, for which their scientific names are written in Latin or Greek. Indeed, CLIP performs poorly for zero-shot species recognition with prompts that use scientific names, e.g., "a photo of Lepus Timidus" (which is a scientific name in Latin). Because these names are usually not included in CLIP's training set. To improve performance, prior works propose to use large-language models (LLMs) to generate descriptions (e.g., of species color and shape) and additionally use them in prompts. We find that they bring only marginal gains. Differently, we are motivated to translate scientific names (e.g., Lepus Timidus) to common English names (e.g., mountain hare) and use such in the prompts. We find that common names are more likely to be included in CLIP's training set, and prompting them achieves 2$\sim$5 times higher accuracy on benchmarking datasets of fine-grained species recognition.