 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Mobile Video Analytics for Pre-arrival Emergency Medical Services
Nov 18, 2025Timely and accurate pre-arrival video streaming and analytics are critical for emergency medical services (EMS) to deliver life-saving interventions. Yet, current-generation EMS infrastructure remains constrained by one-to-one video streaming and limited analytics capabilities, leaving dispatchers and EMTs to manually interpret overwhelming, often noisy or redundant information in high-stress environments. We present TeleEMS, a mobile live video analytics system that enables pre-arrival multimodal inference by fusing audio and video into a unified decision-making pipeline before EMTs arrive on scene. TeleEMS comprises two key components: TeleEMS Client and TeleEMS Server. The TeleEMS Client runs across phones, smart glasses, and desktops to support bystanders, EMTs en route, and 911 dispatchers. The TeleEMS Server, deployed at the edge, integrates EMS-Stream, a communication backbone that enables smooth multi-party video streaming. On top of EMSStream, the server hosts three real-time analytics modules: (1) audio-to-symptom analytics via EMSLlama, a domain-specialized LLM for robust symptom extraction and normalization; (2) video-to-vital analytics using state-of-the-art rPPG methods for heart rate estimation; and (3) joint text-vital analytics via PreNet, a multimodal multitask model predicting EMS protocols, medication types, medication quantities, and procedures. Evaluation shows that EMSLlama outperforms GPT-4o (exact-match 0.89 vs. 0.57) and that text-vital fusion improves inference robustness, enabling reliable pre-arrival intervention recommendations. TeleEMS demonstrates the potential of mobile live video analytics to transform EMS operations, bridging the gap between bystanders, dispatchers, and EMTs, and paving the way for next-generation intelligent EMS infrastructure.
A Smart-Glasses for Emergency Medical Services via Multimodal Multitask Learning
Nov 17, 2025Emergency Medical Technicians (EMTs) operate in high-pressure environments, making rapid, life-critical decisions under heavy cognitive and operational loads. We present EMSGlass, a smart-glasses system powered by EMSNet, the first multimodal multitask model for Emergency Medical Services (EMS), and EMSServe, a low-latency multimodal serving framework tailored to EMS scenarios. EMSNet integrates text, vital signs, and scene images to construct a unified real-time understanding of EMS incidents. Trained on real-world multimodal EMS datasets, EMSNet simultaneously supports up to five critical EMS tasks with superior accuracy compared to state-of-the-art unimodal baselines. Built on top of PyTorch, EMSServe introduces a modality-aware model splitter and a feature caching mechanism, achieving adaptive and efficient inference across heterogeneous hardware while addressing the challenge of asynchronous modality arrival in the field. By optimizing multimodal inference execution in EMS scenarios, EMSServe achieves 1.9x -- 11.7x speedup over direct PyTorch multimodal inference. A user study evaluation with six professional EMTs demonstrates that EMSGlass enhances real-time situational awareness, decision-making speed, and operational efficiency through intuitive on-glass interaction. In addition, qualitative insights from the user study provide actionable directions for extending EMSGlass toward next-generation AI-enabled EMS systems, bridging multimodal intelligence with real-world emergency response workflows.
3DPFIX: Improving Remote Novices' 3D Printing Troubleshooting through Human-AI Collaboration
Feb 02, 2024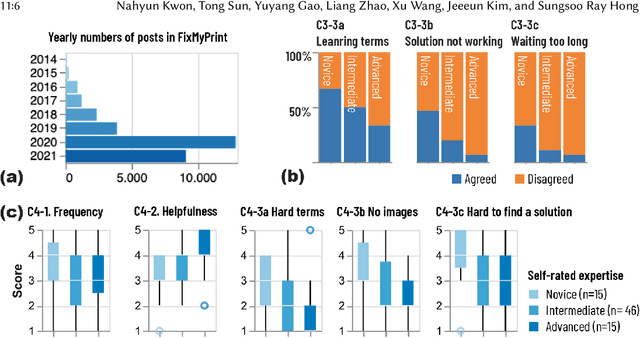
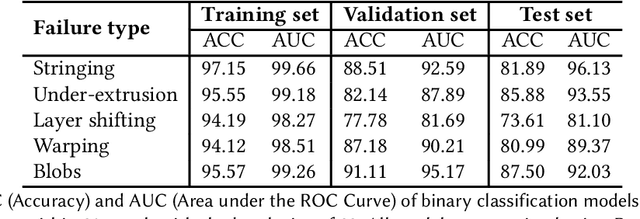
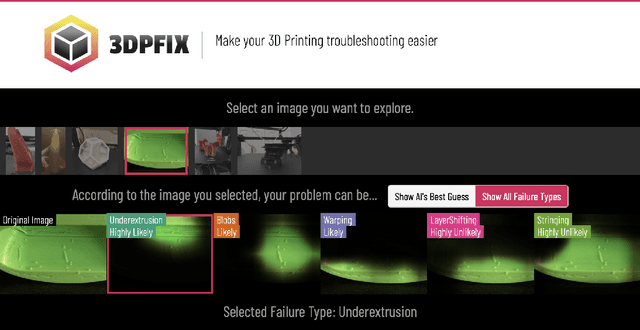

The widespread consumer-grade 3D printers and learning resources online enable novices to self-train in remote settings. While troubleshooting plays an essential part of 3D printing, the process remains challenging for many remote novices even with the help of well-developed online sources, such as online troubleshooting archives and online community help. We conducted a formative study with 76 active 3D printing users to learn how remote novices leverage online resources in troubleshooting and their challenges. We found that remote novices cannot fully utilize online resources. For example, the online archives statically provide general information, making it hard to search and relate their unique cases with existing descriptions. Online communities can potentially ease their struggles by providing more targeted suggestions, but a helper who can provide custom help is rather scarce, making it hard to obtain timely assistance. We propose 3DPFIX, an interactive 3D troubleshooting system powered by the pipeline to facilitate Human-AI Collaboration, designed to improve novices' 3D printing experiences and thus help them easily accumulate their domain knowledge. We built 3DPFIX that supports automated diagnosis and solution-seeking. 3DPFIX was built upon shared dialogues about failure cases from Q&A discourses accumulated in online communities. We leverage social annotations (i.e., comments) to build an annotated failure image dataset for AI classifiers and extract a solution pool. Our summative study revealed that using 3DPFIX helped participants spend significantly less effort in diagnosing failures and finding a more accurate solution than relying on their common practice. We also found that 3DPFIX users learn about 3D printing domain-specific knowledge. We discuss the implications of leveraging community-driven data in developing future Human-AI Collaboration designs.
AccessLens: Auto-detecting Inaccessibility of Everyday Objects
Jan 29, 2024


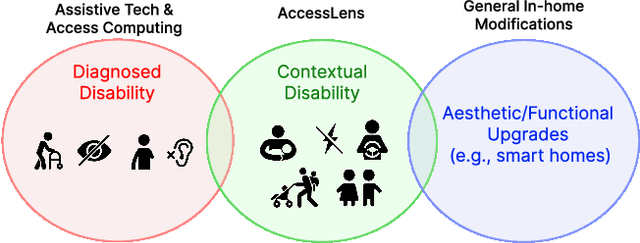
In our increasingly diverse society, everyday physical interfaces often present barriers, impacting individuals across various contexts. This oversight, from small cabinet knobs to identical wall switches that can pose different contextual challenges, highlights an imperative need for solutions. Leveraging low-cost 3D-printed augmentations such as knob magnifiers and tactile labels seems promising, yet the process of discovering unrecognized barriers remains challenging because disability is context-dependent. We introduce AccessLens, an end-to-end system designed to identify inaccessible interfaces in daily objects, and recommend 3D-printable augmentations for accessibility enhancement. Our approach involves training a detector using the novel AccessDB dataset designed to automatically recognize 21 distinct Inaccessibility Classes (e.g., bar-small and round-rotate) within 6 common object categories (e.g., handle and knob). AccessMeta serves as a robust way to build a comprehensive dictionary linking these accessibility classes to open-source 3D augmentation designs. Experiments demonstrate our detector's performance in detecting inaccessible objects.
A High-Resolution Dataset for Instance Detection with Multi-View Instance Capture
Oct 30, 2023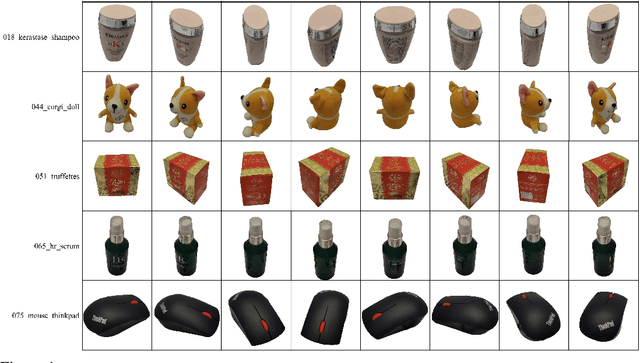
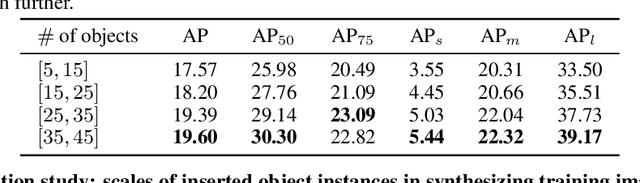
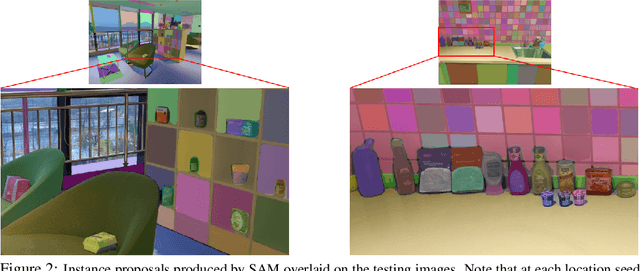
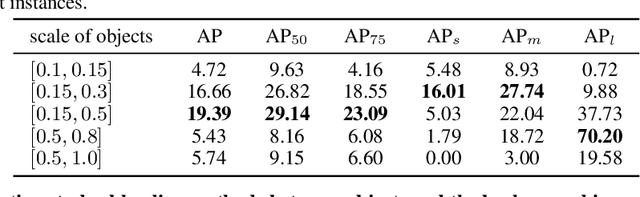
Instance detection (InsDet) is a long-lasting problem in robotics and computer vision, aiming to detect object instances (predefined by some visual examples) in a cluttered scene. Despite its practical significance, its advancement is overshadowed by Object Detection, which aims to detect objects belonging to some predefined classes. One major reason is that current InsDet datasets are too small in scale by today's standards. For example, the popular InsDet dataset GMU (published in 2016) has only 23 instances, far less than COCO (80 classes), a well-known object detection dataset published in 2014. We are motivated to introduce a new InsDet dataset and protocol. First, we define a realistic setup for InsDet: training data consists of multi-view instance captures, along with diverse scene images allowing synthesizing training images by pasting instance images on them with free box annotations. Second, we release a real-world database, which contains multi-view capture of 100 object instances, and high-resolution (6k x 8k) testing images. Third, we extensively study baseline methods for InsDet on our dataset, analyze their performance and suggest future work. Somewhat surprisingly, using the off-the-shelf class-agnostic segmentation model (Segment Anything Model, SAM) and the self-supervised feature representation DINOv2 performs the best, achieving >10 AP better than end-to-end trained InsDet models that repurpose object detectors (e.g., FasterRCNN and RetinaNet).
Elementwise Language Representation
Feb 27, 2023



We propose a new technique for computational language representation called elementwise embedding, in which a material (semantic unit) is abstracted into a horizontal concatenation of lower-dimensional element (character) embeddings. While elements are always characters, materials are arbitrary levels of semantic units so it generalizes to any type of tokenization. To focus only on the important letters, the $n^{th}$ spellings of each semantic unit are aligned in $n^{th}$ attention heads, then concatenated back into original forms creating unique embedding representations; they are jointly projected thereby determining own contextual importance. Technically, this framework is achieved by passing a sequence of materials, each consists of $v$ elements, to a transformer having $h=v$ attention heads. As a pure embedding technique, elementwise embedding replaces the $w$-dimensional embedding table of a transformer model with $256$ $c$-dimensional elements (each corresponding to one of UTF-8 bytes) where $c=w/v$. Using this novel approach, we show that the standard transformer architecture can be reused for all levels of language representations and be able to process much longer sequences at the same time-complexity without "any" architectural modification and additional overhead. BERT trained with elementwise embedding outperforms its subword equivalence (original implementation) in multilabel patent document classification exhibiting superior robustness to domain-specificity and data imbalance, despite using $0.005\%$ of embedding parameters. Experiments demonstrate the generalizability of the proposed method by successfully transferring these enhancements to differently architected transformers CANINE and ALBERT.
Roman: Making Everyday Objects Robotically Manipulable with 3D-Printable Add-on Mechanisms
May 16, 2022

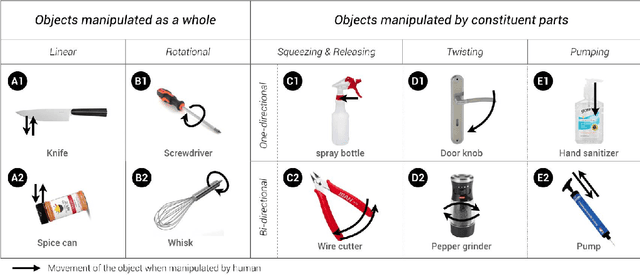

One important vision of robotics is to provide physical assistance by manipulating different everyday objects, e.g., hand tools, kitchen utensils. However, many objects designed for dexterous hand-control are not easily manipulable by a single robotic arm with a generic parallel gripper. Complementary to existing research on developing grippers and control algorithms, we present Roman, a suite of hardware design and software tool support for robotic engineers to create 3D printable mechanisms attached to everyday handheld objects, making them easier to be manipulated by conventional robotic arms. The Roman hardware comes with a versatile magnetic gripper that can snap on/off handheld objects and drive add-on mechanisms to perform tasks. Roman also provides software support to register and author control programs. To validate our approach, we designed and fabricated Roman mechanisms for 14 everyday objects/tasks presented within a design space and conducted expert interviews with robotic engineers indicating that Roman serves as a practical alternative for enabling robotic manipulation of everyday objects.