 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrackSQL: A Hybrid SQL Dialect Translation System Powered by Large Language Models
Apr 01, 2025Dialect translation plays a key role in enabling seamless interaction across heterogeneous database systems. However, translating SQL queries between different dialects (e.g., from PostgreSQL to MySQL) remains a challenging task due to syntactic discrepancies and subtle semantic variations. Existing approaches including manual rewriting, rule-based systems, and large language model (LLM)-based techniques often involve high maintenance effort (e.g., crafting custom translation rules) or produce unreliable results (e.g., LLM generates non-existent functions), especially when handling complex queries. In this demonstration, we present CrackSQL, the first hybrid SQL dialect translation system that combines rule and LLM-based methods to overcome these limitations. CrackSQL leverages the adaptability of LLMs to minimize manual intervention, while enhancing translation accuracy by segmenting lengthy complex SQL via functionality-based query processing. To further improve robustness, it incorporates a novel cross-dialect syntax embedding model for precise syntax alignment, as well as an adaptive local-to-global translation strategy that effectively resolves interdependent query operations. CrackSQL supports three translation modes and offers multiple deployment and access options including a web console interface, a PyPI package, and a command-line prompt, facilitating adoption across a variety of real-world use cases
DUE: Dynamic Uncertainty-Aware Explanation Supervision via 3D Imputation
Mar 16, 2024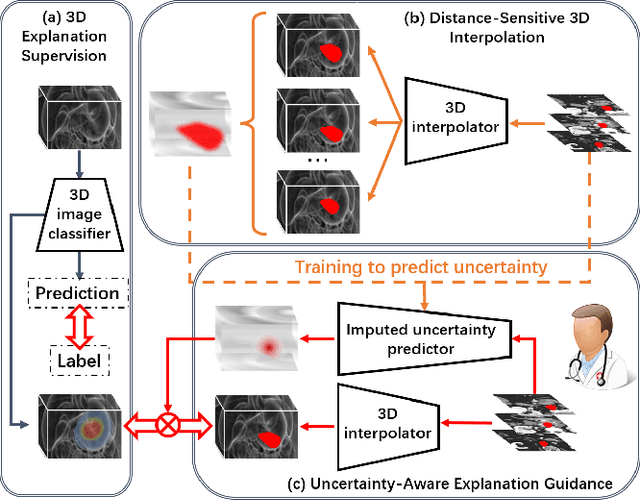
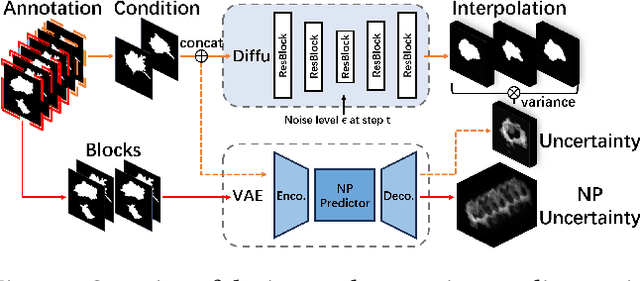
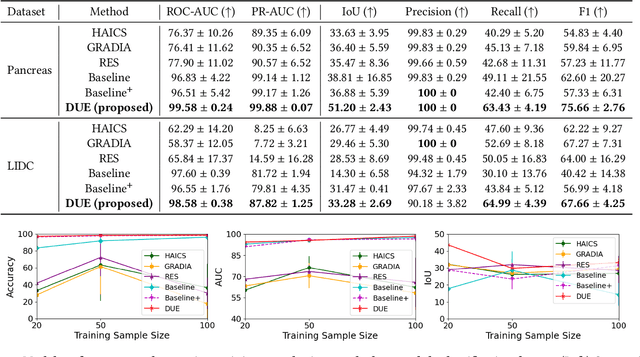
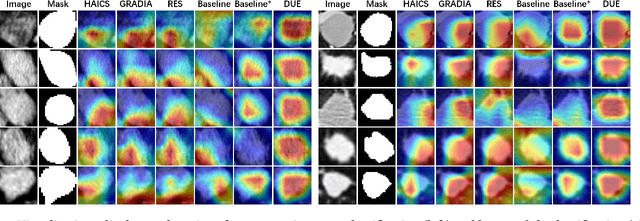
Explanation supervision aims to enhance deep learning models by integrating additional signals to guide the generation of model explanations, showcasing notable improvements in both the predictability and explainability of the model. However, the application of explanation supervision to higher-dimensional data, such as 3D medical images, remains an under-explored domain. Challenges associated with supervising visual explanations in the presence of an additional dimension include: 1) spatial correlation changed, 2) lack of direct 3D annotations, and 3) uncertainty varies across different parts of the explanation. To address these challenges, we propose a Dynamic Uncertainty-aware Explanation supervision (DUE) framework for 3D explanation supervision that ensures uncertainty-aware explanation guidance when dealing with sparsely annotated 3D data with diffusion-based 3D interpolation. Our proposed framework is validated through comprehensive experiments on diverse real-world medical imaging datasets. The results demonstrate the effectiveness of our framework in enhancing the predictability and explainability of deep learning models in the context of medical imaging diagnosis applications.
3DPFIX: Improving Remote Novices' 3D Printing Troubleshooting through Human-AI Collaboration
Feb 02, 2024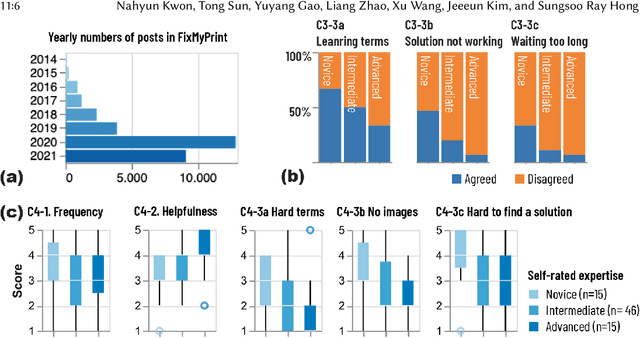
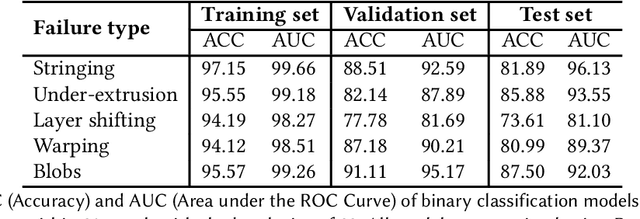
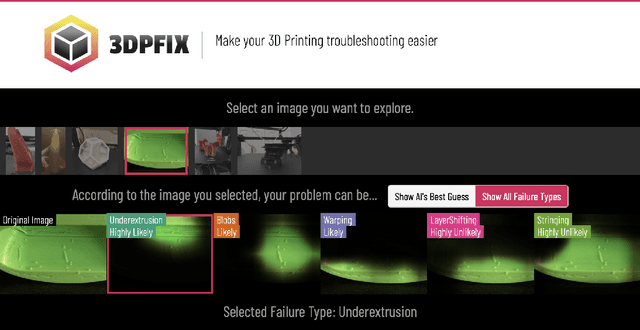

The widespread consumer-grade 3D printers and learning resources online enable novices to self-train in remote settings. While troubleshooting plays an essential part of 3D printing, the process remains challenging for many remote novices even with the help of well-developed online sources, such as online troubleshooting archives and online community help. We conducted a formative study with 76 active 3D printing users to learn how remote novices leverage online resources in troubleshooting and their challenges. We found that remote novices cannot fully utilize online resources. For example, the online archives statically provide general information, making it hard to search and relate their unique cases with existing descriptions. Online communities can potentially ease their struggles by providing more targeted suggestions, but a helper who can provide custom help is rather scarce, making it hard to obtain timely assistance. We propose 3DPFIX, an interactive 3D troubleshooting system powered by the pipeline to facilitate Human-AI Collaboration, designed to improve novices' 3D printing experiences and thus help them easily accumulate their domain knowledge. We built 3DPFIX that supports automated diagnosis and solution-seeking. 3DPFIX was built upon shared dialogues about failure cases from Q&A discourses accumulated in online communities. We leverage social annotations (i.e., comments) to build an annotated failure image dataset for AI classifiers and extract a solution pool. Our summative study revealed that using 3DPFIX helped participants spend significantly less effort in diagnosing failures and finding a more accurate solution than relying on their common practice. We also found that 3DPFIX users learn about 3D printing domain-specific knowledge. We discuss the implications of leveraging community-driven data in developing future Human-AI Collaboration designs.
An Empirical Study of Bugs in Open-Source Federated Learning Framework
Aug 09, 2023



Federated learning (FL), as a decentralized machine learning solution to the protection of users' private data, has become an important learning paradigm in recent years, especially since the enforcement of stricter laws and regulations in most countries. Therefore, a variety of FL frameworks are released to facilitate the development and application of federated learning. Despite the considerable amount of research on the security and privacy of FL models and systems, the security issues in FL frameworks have not been systematically studied yet. In this paper, we conduct the first empirical study on 1,112 FL framework bugs to investigate their characteristics. These bugs are manually collected, classified, and labeled from 12 open-source FL frameworks on GitHub. In detail, we construct taxonomies of 15 symptoms, 12 root causes, and 20 fix patterns of these bugs and investigate their correlations and distributions on 23 logical components and two main application scenarios. From the results of our study, we present nine findings, discuss their implications, and propound several suggestions to FL framework developers and security researchers on the FL frameworks.
Designing a Direct Feedback Loop between Humans and Convolutional Neural Networks through Local Explanations
Jul 08, 2023
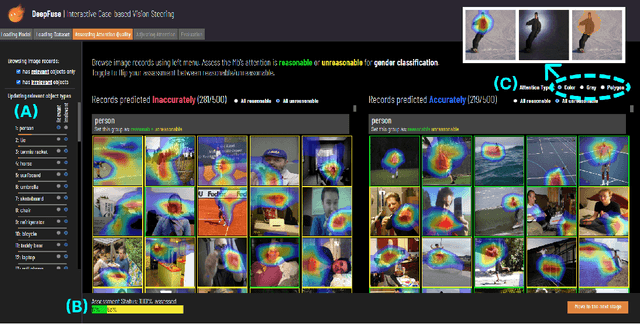

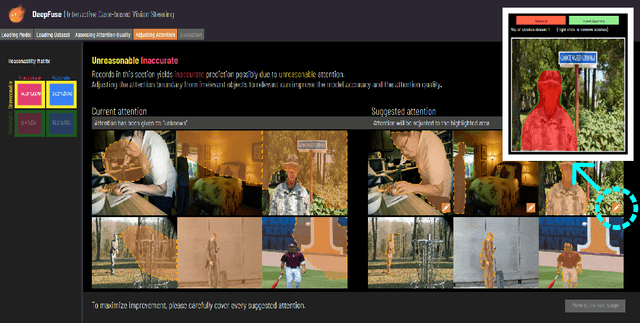
The local explanation provides heatmaps on images to explain how Convolutional Neural Networks (CNNs) derive their output. Due to its visual straightforwardness, the method has been one of the most popular explainable AI (XAI) methods for diagnosing CNNs. Through our formative study (S1), however, we captured ML engineers' ambivalent perspective about the local explanation as a valuable and indispensable envision in building CNNs versus the process that exhausts them due to the heuristic nature of detecting vulnerability. Moreover, steering the CNNs based on the vulnerability learned from the diagnosis seemed highly challenging. To mitigate the gap, we designed DeepFuse, the first interactive design that realizes the direct feedback loop between a user and CNNs in diagnosing and revising CNN's vulnerability using local explanations. DeepFuse helps CNN engineers to systemically search "unreasonable" local explanations and annotate the new boundaries for those identified as unreasonable in a labor-efficient manner. Next, it steers the model based on the given annotation such that the model doesn't introduce similar mistakes. We conducted a two-day study (S2) with 12 experienced CNN engineers. Using DeepFuse, participants made a more accurate and "reasonable" model than the current state-of-the-art. Also, participants found the way DeepFuse guides case-based reasoning can practically improve their current practice. We provide implications for design that explain how future HCI-driven design can move our practice forward to make XAI-driven insights more actionable.
Saliency-Augmented Memory Completion for Continual Learning
Dec 26, 2022Continual Learning is considered a key step toward next-generation Artificial Intelligence. Among various methods, replay-based approaches that maintain and replay a small episodic memory of previous samples are one of the most successful strategies against catastrophic forgetting. However, since forgetting is inevitable given bounded memory and unbounded tasks, how to forget is a problem continual learning must address. Therefore, beyond simply avoiding catastrophic forgetting, an under-explored issue is how to reasonably forget while ensuring the merits of human memory, including 1. storage efficiency, 2. generalizability, and 3. some interpretability. To achieve these simultaneously, our paper proposes a new saliency-augmented memory completion framework for continual learning, inspired by recent discoveries in memory completion separation in cognitive neuroscience. Specifically, we innovatively propose to store the part of the image most important to the tasks in episodic memory by saliency map extraction and memory encoding. When learning new tasks, previous data from memory are inpainted by an adaptive data generation module, which is inspired by how humans complete episodic memory. The module's parameters are shared across all tasks and it can be jointly trained with a continual learning classifier as bilevel optimization. Extensive experiments on several continual learning and image classification benchmarks demonstrate the proposed method's effectiveness and efficiency.
Going Beyond XAI: A Systematic Survey for Explanation-Guided Learning
Dec 07, 2022



As the societal impact of Deep Neural Networks (DNNs) grows, the goals for advancing DNNs become more complex and diverse, ranging from improving a conventional model accuracy metric to infusing advanced human virtues such as fairness, accountability, transparency (FaccT), and unbiasedness. Recently, techniques in Explainable Artificial Intelligence (XAI) are attracting considerable attention, and have tremendously helped Machine Learning (ML) engineers in understanding AI models. However, at the same time, we started to witness the emerging need beyond XAI among AI communities; based on the insights learned from XAI, how can we better empower ML engineers in steering their DNNs so that the model's reasonableness and performance can be improved as intended? This article provides a timely and extensive literature overview of the field Explanation-Guided Learning (EGL), a domain of techniques that steer the DNNs' reasoning process by adding regularization, supervision, or intervention on model explanations. In doing so, we first provide a formal definition of EGL and its general learning paradigm. Secondly, an overview of the key factors for EGL evaluation, as well as summarization and categorization of existing evaluation procedures and metrics for EGL are provided. Finally, the current and potential future application areas and directions of EGL are discussed, and an extensive experimental study is presented aiming at providing comprehensive comparative studies among existing EGL models in various popular application domains, such as Computer Vision (CV) and Natural Language Processing (NLP) domains.
RES: A Robust Framework for Guiding Visual Explanation
Jun 27, 2022
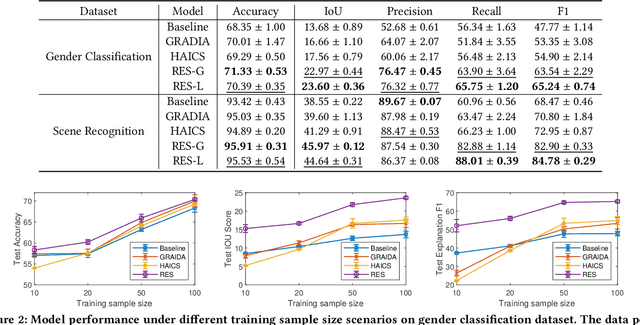
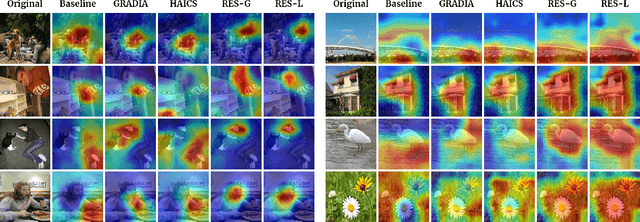
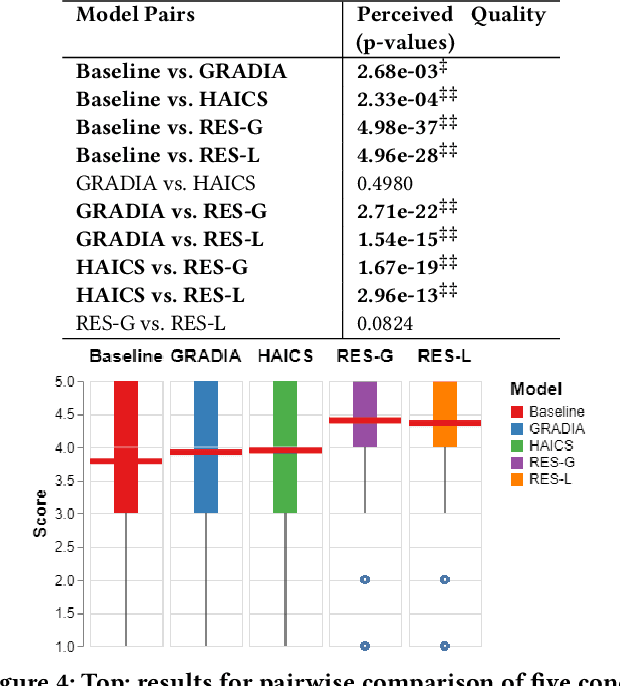
Despite the fast progress of explanation techniques in modern Deep Neural Networks (DNNs) where the main focus is handling "how to generate the explanations", advanced research questions that examine the quality of the explanation itself (e.g., "whether the explanations are accurate") and improve the explanation quality (e.g., "how to adjust the model to generate more accurate explanations when explanations are inaccurate") are still relatively under-explored. To guide the model toward better explanations, techniques in explanation supervision - which add supervision signals on the model explanation - have started to show promising effects on improving both the generalizability as and intrinsic interpretability of Deep Neural Networks. However, the research on supervising explanations, especially in vision-based applications represented through saliency maps, is in its early stage due to several inherent challenges: 1) inaccuracy of the human explanation annotation boundary, 2) incompleteness of the human explanation annotation region, and 3) inconsistency of the data distribution between human annotation and model explanation maps. To address the challenges, we propose a generic RES framework for guiding visual explanation by developing a novel objective that handles inaccurate boundary, incomplete region, and inconsistent distribution of human annotations, with a theoretical justification on model generalizability. Extensive experiments on two real-world image datasets demonstrate the effectiveness of the proposed framework on enhancing both the reasonability of the explanation and the performance of the backbone DNNs model.
* Published in KDD 2022
Aligning Eyes between Humans and Deep Neural Network through Interactive Attention Alignment
Feb 06, 2022


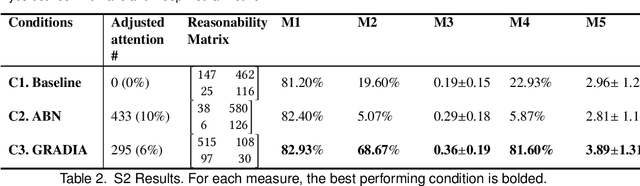
While Deep Neural Networks (DNNs) are deriving the major innovations in nearly every field through their powerful automation, we are also witnessing the peril behind automation as a form of bias, such as automated racism, gender bias, and adversarial bias. As the societal impact of DNNs grows, finding an effective way to steer DNNs to align their behavior with the human mental model has become indispensable in realizing fair and accountable models. We propose a novel framework of Interactive Attention Alignment (IAA) that aims at realizing human-steerable Deep Neural Networks (DNNs). IAA leverages DNN model explanation method as an interactive medium that humans can use to unveil the cases of biased model attention and directly adjust the attention. In improving the DNN using human-generated adjusted attention, we introduce GRADIA, a novel computational pipeline that jointly maximizes attention quality and prediction accuracy. We evaluated IAA framework in Study 1 and GRADIA in Study 2 in a gender classification problem. Study 1 found applying IAA can significantly improve the perceived quality of model attention from human eyes. In Study 2, we found using GRADIA can (1) significantly improve the perceived quality of model attention and (2) significantly improve model performance in scenarios where the training samples are limited. We present implications for future interactive user interfaces design towards human-alignable AI.
Schematic Memory Persistence and Transience for Efficient and Robust Continual Learning
May 05, 2021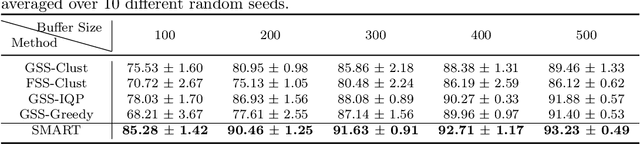
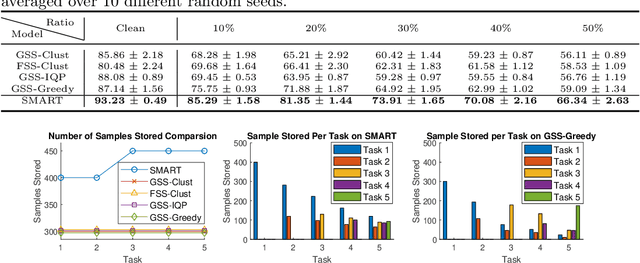
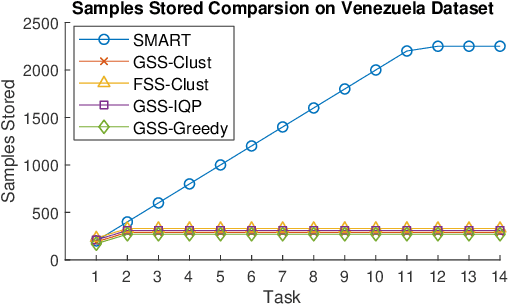
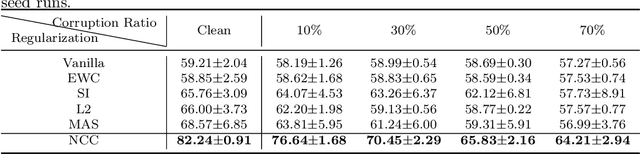
Continual learning is considered a promising step towards next-generation Artificial Intelligence (AI), where deep neural networks (DNNs) make decisions by continuously learning a sequence of different tasks akin to human learning processes. It is still quite primitive, with existing works focusing primarily on avoiding (catastrophic) forgetting. However, since forgetting is inevitable given bounded memory and unbounded task loads, 'how to reasonably forget' is a problem continual learning must address in order to reduce the performance gap between AIs and humans, in terms of 1) memory efficiency, 2) generalizability, and 3) robustness when dealing with noisy data. To address this, we propose a novel ScheMAtic memory peRsistence and Transience (SMART) framework for continual learning with external memory that builds on recent advances in neuroscience. The efficiency and generalizability are enhanced by a novel long-term forgetting mechanism and schematic memory, using sparsity and 'backward positive transfer' constraints with theoretical guarantees on the error bound. Robust enhancement is achieved using a novel short-term forgetting mechanism inspired by background information-gated learning. Finally, an extensive experimental analysis on both benchmark and real-world datasets demonstrates the effectiveness and efficiency of our model.