 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal RAG: Sub-dimensional Retrieval-Augmented Text-to-Image Generation
May 29, 2025Text-to-image generation increasingly demands access to domain-specific, fine-grained, and rapidly evolving knowledge that pretrained models cannot fully capture. Existing Retrieval-Augmented Generation (RAG) methods attempt to address this by retrieving globally relevant images, but they fail when no single image contains all desired elements from a complex user query. We propose Cross-modal RAG, a novel framework that decomposes both queries and images into sub-dimensional components, enabling subquery-aware retrieval and generation. Our method introduces a hybrid retrieval strategy - combining a sub-dimensional sparse retriever with a dense retriever - to identify a Pareto-optimal set of images, each contributing complementary aspects of the query. During generation, a multimodal large language model is guided to selectively condition on relevant visual features aligned to specific subqueries, ensuring subquery-aware image synthesis. Extensive experiments on MS-COCO, Flickr30K, WikiArt, CUB, and ImageNet-LT demonstrate that Cross-modal RAG significantly outperforms existing baselines in both retrieval and generation quality, while maintaining high efficiency.
MEGL: Multimodal Explanation-Guided Learning
Nov 20, 2024



Explaining the decision-making processes of Artificial Intelligence (AI) models is crucial for addressing their "black box" nature, particularly in tasks like image classification. Traditional eXplainable AI (XAI) methods typically rely on unimodal explanations, either visual or textual, each with inherent limitations. Visual explanations highlight key regions but often lack rationale, while textual explanations provide context without spatial grounding. Further, both explanation types can be inconsistent or incomplete, limiting their reliability. To address these challenges, we propose a novel Multimodal Explanation-Guided Learning (MEGL) framework that leverages both visual and textual explanations to enhance model interpretability and improve classification performance. Our Saliency-Driven Textual Grounding (SDTG) approach integrates spatial information from visual explanations into textual rationales, providing spatially grounded and contextually rich explanations. Additionally, we introduce Textual Supervision on Visual Explanations to align visual explanations with textual rationales, even in cases where ground truth visual annotations are missing. A Visual Explanation Distribution Consistency loss further reinforces visual coherence by aligning the generated visual explanations with dataset-level patterns, enabling the model to effectively learn from incomplete multimodal supervision. We validate MEGL on two new datasets, Object-ME and Action-ME, for image classification with multimodal explanations. Experimental results demonstrate that MEGL outperforms previous approaches in prediction accuracy and explanation quality across both visual and textual domains. Our code will be made available upon the acceptance of the paper.
FedSpaLLM: Federated Pruning of Large Language Models
Oct 18, 2024



Large Language Models (LLMs) achieve state-of-the-art performance but are challenging to deploy due to their high computational and storage demands. Pruning can reduce model size, yet existing methods assume public access to calibration data, which is impractical for privacy-sensitive applications. To address the challenge of pruning LLMs in privacy-preserving settings, we propose FedSpaLLM, the first federated learning framework designed specifically for pruning LLMs. FedSpaLLM enables clients to prune their models locally based on private data while accounting for system heterogeneity and maintaining communication efficiency. Our framework introduces several key innovations: (1) a novel $\ell_0$-norm aggregation function that ensures only non-zero weights are averaged across clients, preserving important model parameters; (2) an adaptive mask expansion technique that meets global sparsity targets while accommodating client-specific pruning decisions; and (3) a layer sampling strategy that reduces communication overhead and personalizes the pruning process based on client resources. Extensive experiments show that FedSpaLLM improves pruning performance in diverse federated settings. The source code will be released upon publication.
Deep Causal Generative Models with Property Control
May 25, 2024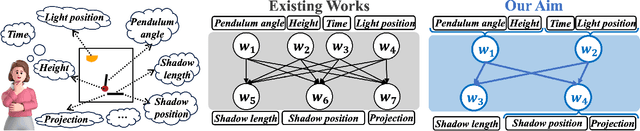
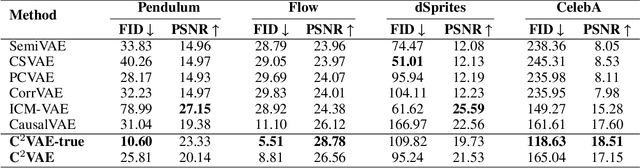
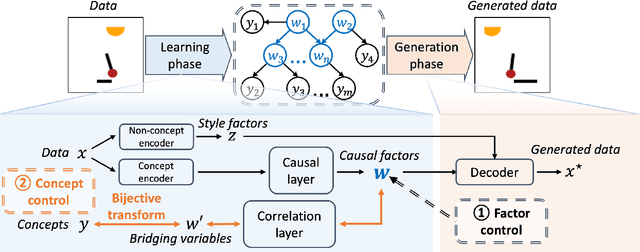
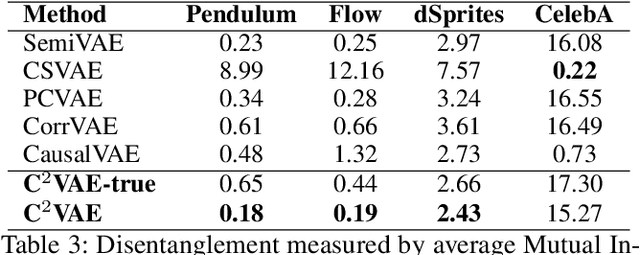
Generating data with properties of interest by external users while following the right causation among its intrinsic factors is important yet has not been well addressed jointly. This is due to the long-lasting challenge of jointly identifying key latent variables, their causal relations, and their correlation with properties of interest, as well as how to leverage their discoveries toward causally controlled data generation. To address these challenges, we propose a novel deep generative framework called the Correlation-aware Causal Variational Auto-encoder (C2VAE). This framework simultaneously recovers the correlation and causal relationships between properties using disentangled latent vectors. Specifically, causality is captured by learning the causal graph on latent variables through a structural causal model, while correlation is learned via a novel correlation pooling algorithm. Extensive experiments demonstrate C2VAE's ability to accurately recover true causality and correlation, as well as its superiority in controllable data generation compared to baseline models.
Continuous Temporal Domain Generalization
May 25, 2024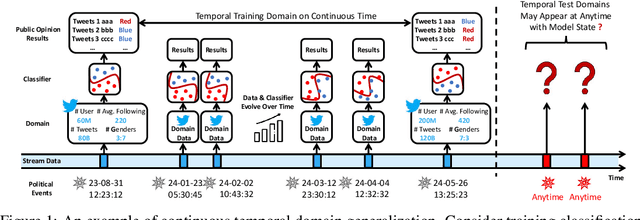
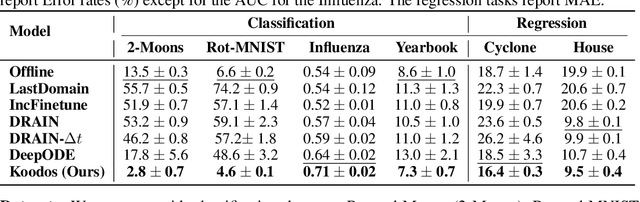

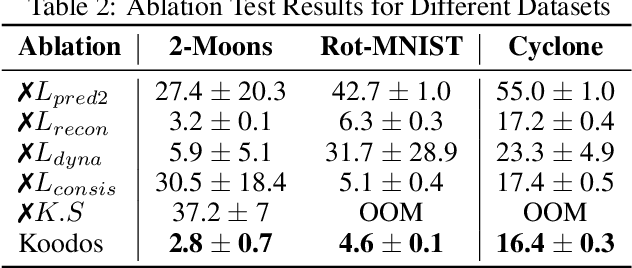
Temporal Domain Generalization (TDG) addresses the challenge of training predictive models under temporally varying data distributions. Traditional TDG approaches typically focus on domain data collected at fixed, discrete time intervals, which limits their capability to capture the inherent dynamics within continuous-evolving and irregularly-observed temporal domains. To overcome this, this work formalizes the concept of Continuous Temporal Domain Generalization (CTDG), where domain data are derived from continuous times and are collected at arbitrary times. CTDG tackles critical challenges including: 1) Characterizing the continuous dynamics of both data and models, 2) Learning complex high-dimensional nonlinear dynamics, and 3) Optimizing and controlling the generalization across continuous temporal domains. To address them, we propose a Koopman operator-driven continuous temporal domain generalization (Koodos) framework. We formulate the problem within a continuous dynamic system and leverage the Koopman theory to learn the underlying dynamics; the framework is further enhanced with a comprehensive optimization strategy equipped with analysis and control driven by prior knowledge of the dynamics patterns. Extensive experiments demonstrate the effectiveness and efficiency of our approach.
Gradient-Free Adaptive Global Pruning for Pre-trained Language Models
Feb 28, 2024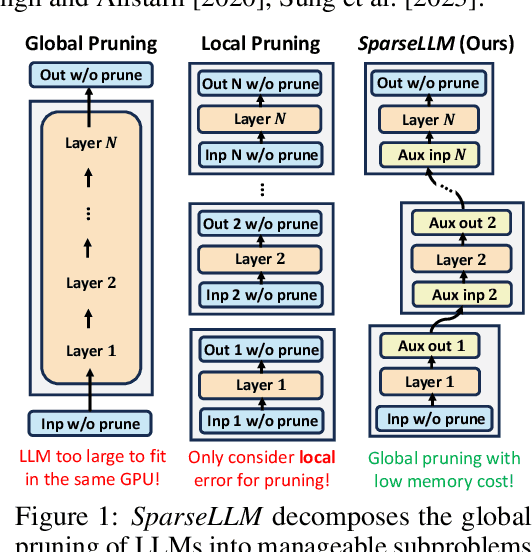
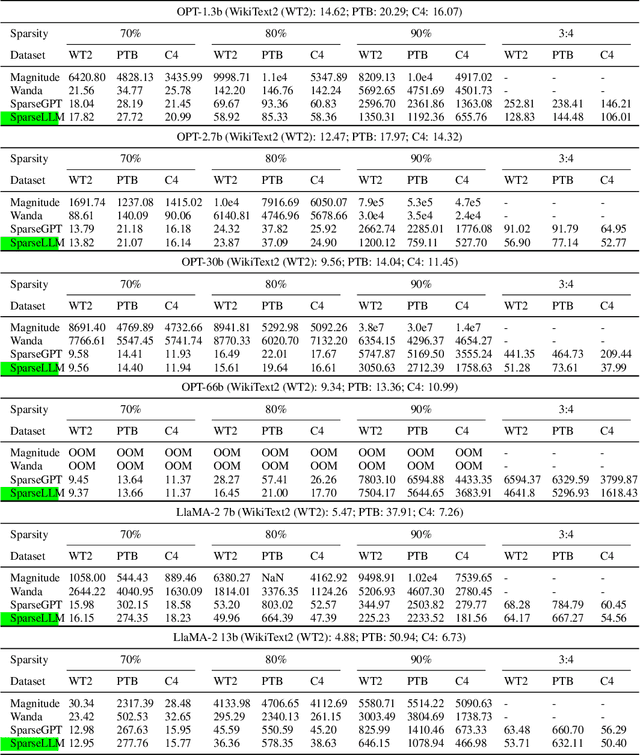
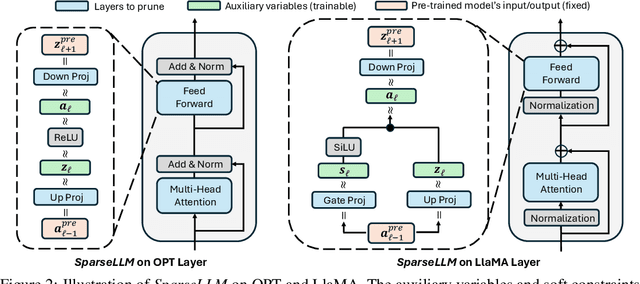
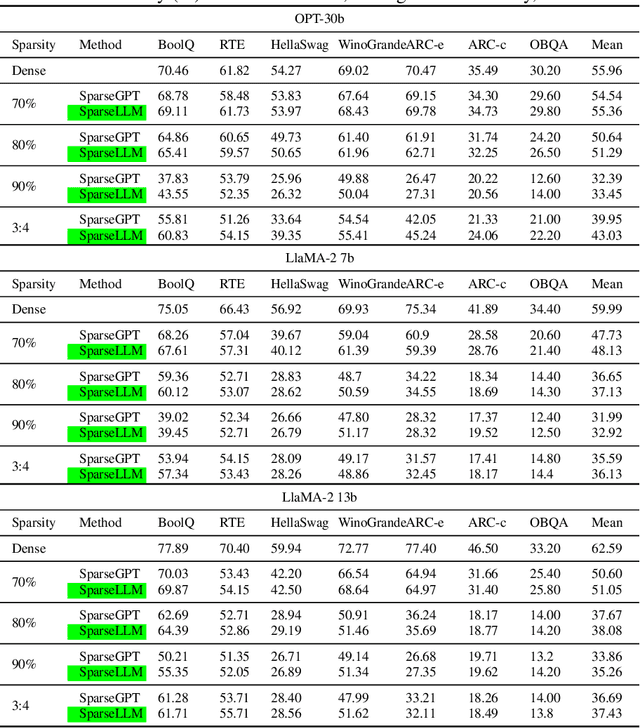
The transformative impact of large language models (LLMs) like LLaMA and GPT on natural language processing is countered by their prohibitive computational demands. Pruning has emerged as a pivotal compression strategy, introducing sparsity to enhance both memory and computational efficiency. Yet, traditional global pruning is impractical for LLMs due to scalability issues, while local pruning, despite its efficiency, leads to suboptimal solutions. Addressing these challenges, we propose Adaptive Global Pruning (AdaGP), a novel framework that redefines the global pruning process into manageable, coordinated subproblems, allowing for resource-efficient optimization with global optimality. AdaGP's approach, which conceptualizes LLMs as a chain of modular functions and leverages auxiliary variables for problem decomposition, not only facilitates a pragmatic application on LLMs but also demonstrates significant performance improvements, particularly in high-sparsity regimes where it surpasses current state-of-the-art methods.
Uncertainty Decomposition and Quantification for In-Context Learning of Large Language Models
Feb 15, 2024
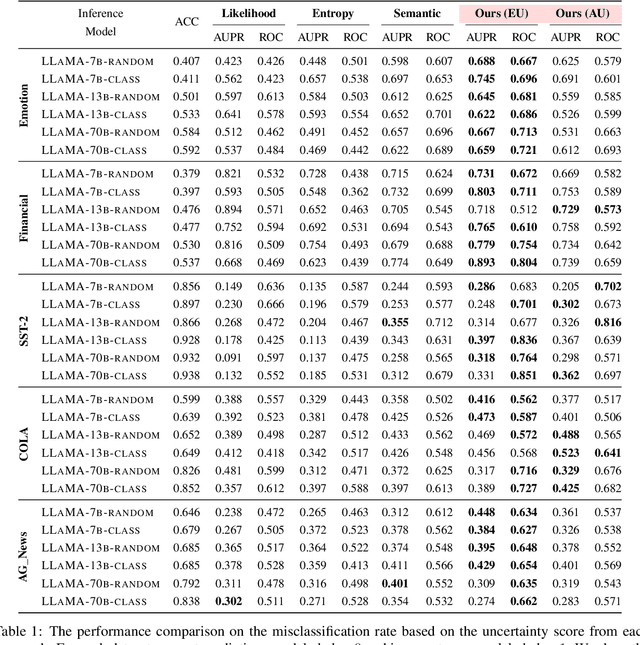
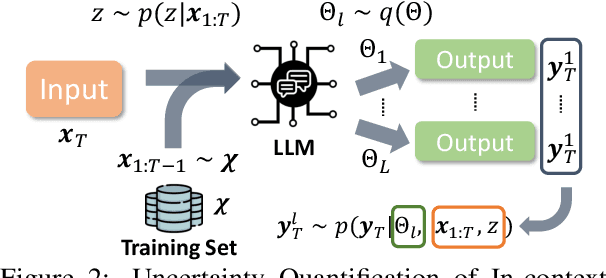
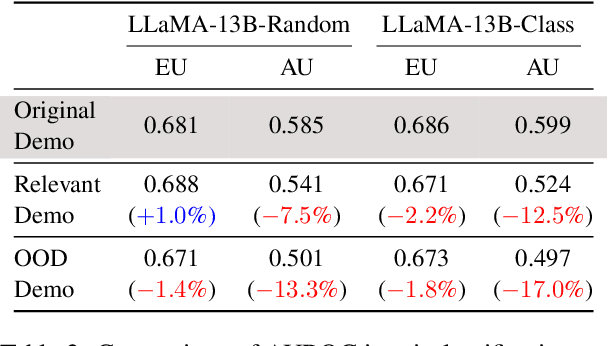
In-context learning has emerged as a groundbreaking ability of Large Language Models (LLMs) and revolutionized various fields by providing a few task-relevant demonstrations in the prompt. However, trustworthy issues with LLM's response, such as hallucination, have also been actively discussed. Existing works have been devoted to quantifying the uncertainty in LLM's response, but they often overlook the complex nature of LLMs and the uniqueness of in-context learning. In this work, we delve into the predictive uncertainty of LLMs associated with in-context learning, highlighting that such uncertainties may stem from both the provided demonstrations (aleatoric uncertainty) and ambiguities tied to the model's configurations (epistemic uncertainty). We propose a novel formulation and corresponding estimation method to quantify both types of uncertainties. The proposed method offers an unsupervised way to understand the prediction of in-context learning in a plug-and-play fashion. Extensive experiments are conducted to demonstrate the effectiveness of the decomposition. The code and data are available at: \url{https://github.com/lingchen0331/UQ_ICL}.
Beyond Efficiency: A Systematic Survey of Resource-Efficient Large Language Models
Jan 04, 2024The burgeoning field of Large Language Models (LLMs), exemplified by sophisticated models like OpenAI's ChatGPT, represents a significant advancement in artificial intelligence. These models, however, bring forth substantial challenges in the high consumption of computational, memory, energy, and financial resources, especially in environments with limited resource capabilities. This survey aims to systematically address these challenges by reviewing a broad spectrum of techniques designed to enhance the resource efficiency of LLMs. We categorize methods based on their optimization focus: computational, memory, energy, financial, and network resources and their applicability across various stages of an LLM's lifecycle, including architecture design, pretraining, finetuning, and system design. Additionally, the survey introduces a nuanced categorization of resource efficiency techniques by their specific resource types, which uncovers the intricate relationships and mappings between various resources and corresponding optimization techniques. A standardized set of evaluation metrics and datasets is also presented to facilitate consistent and fair comparisons across different models and techniques. By offering a comprehensive overview of the current sota and identifying open research avenues, this survey serves as a foundational reference for researchers and practitioners, aiding them in developing more sustainable and efficient LLMs in a rapidly evolving landscape.
Prompt-based Domain Discrimination for Multi-source Time Series Domain Adaptation
Dec 19, 2023



Time series domain adaptation stands as a pivotal and intricate challenge with diverse applications, including but not limited to human activity recognition, sleep stage classification, and machine fault diagnosis. Despite the numerous domain adaptation techniques proposed to tackle this complex problem, their primary focus has been on the common representations of time series data. This concentration might inadvertently lead to the oversight of valuable domain-specific information originating from different source domains. To bridge this gap, we introduce POND, a novel prompt-based deep learning model designed explicitly for multi-source time series domain adaptation. POND is tailored to address significant challenges, notably: 1) The unavailability of a quantitative relationship between meta-data information and time series distributions, and 2) The dearth of exploration into extracting domain-specific meta-data information. In this paper, we present an instance-level prompt generator and a fidelity loss mechanism to facilitate the faithful learning of meta-data information. Additionally, we propose a domain discrimination technique to discern domain-specific meta-data information from multiple source domains. Our approach involves a simple yet effective meta-learning algorithm to optimize the objective efficiently. Furthermore, we augment the model's performance by incorporating the Mixture of Expert (MoE) technique. The efficacy and robustness of our proposed POND model are extensively validated through experiments across 50 scenarios encompassing five datasets, which demonstrates that our proposed POND model outperforms the state-of-the-art methods by up to $66\%$ on the F1-score.
Visual Attention-Prompted Prediction and Learning
Oct 12, 2023



Explanation(attention)-guided learning is a method that enhances a model's predictive power by incorporating human understanding during the training phase. While attention-guided learning has shown promising results, it often involves time-consuming and computationally expensive model retraining. To address this issue, we introduce the attention-prompted prediction technique, which enables direct prediction guided by the attention prompt without the need for model retraining. However, this approach presents several challenges, including: 1) How to incorporate the visual attention prompt into the model's decision-making process and leverage it for future predictions even in the absence of a prompt? and 2) How to handle the incomplete information from the visual attention prompt? To tackle these challenges, we propose a novel framework called Visual Attention-Prompted Prediction and Learning, which seamlessly integrates visual attention prompts into the model's decision-making process and adapts to images both with and without attention prompts for prediction. To address the incomplete information of the visual attention prompt, we introduce a perturbation-based attention map modification method. Additionally, we propose an optimization-based mask aggregation method with a new weight learning function for adaptive perturbed annotation aggregation in the attention map modification process. Our overall framework is designed to learn in an attention-prompt guided multi-task manner to enhance future predictions even for samples without attention prompts and trained in an alternating manner for better convergence. Extensive experiments conducted on two datasets demonstrate the effectiveness of our proposed framework in enhancing predictions for samples, both with and without provided prompts.