 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEndoChat: Grounded Multimodal Large Language Model for Endoscopic Surgery
Jan 20, 2025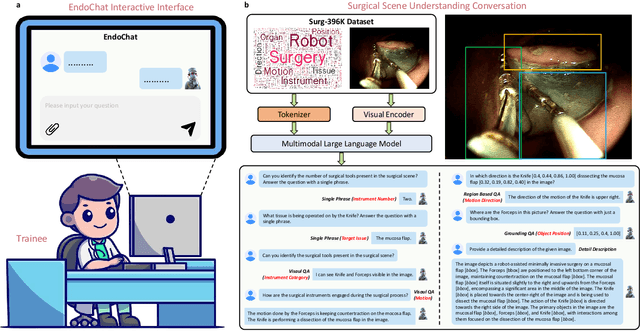
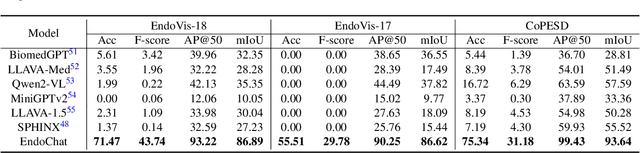
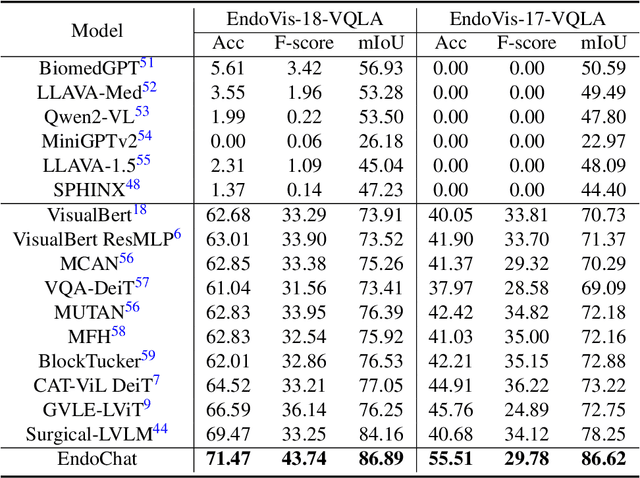
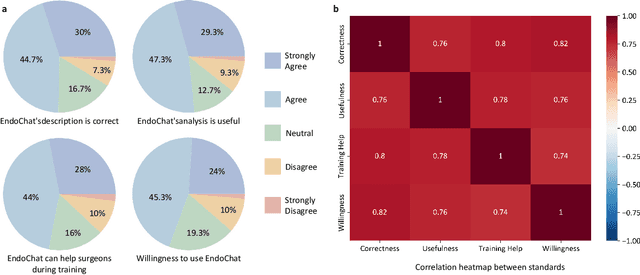
Recently, Multimodal Large Language Models (MLLMs) have demonstrated their immense potential in computer-aided diagnosis and decision-making. In the context of robotic-assisted surgery, MLLMs can serve as effective tools for surgical training and guidance. However, there is still a lack of MLLMs specialized for surgical scene understanding in clinical applications. In this work, we introduce EndoChat to address various dialogue paradigms and subtasks in surgical scene understanding that surgeons encounter. To train our EndoChat, we construct the Surg-396K dataset through a novel pipeline that systematically extracts surgical information and generates structured annotations based on collected large-scale endoscopic surgery datasets. Furthermore, we introduce a multi-scale visual token interaction mechanism and a visual contrast-based reasoning mechanism to enhance the model's representation learning and reasoning capabilities. Our model achieves state-of-the-art performance across five dialogue paradigms and eight surgical scene understanding tasks. Additionally, we conduct evaluations with professional surgeons, most of whom provide positive feedback on collaborating with EndoChat. Overall, these results demonstrate that our EndoChat has great potential to significantly advance training and automation in robotic-assisted surgery.
MEGL: Multimodal Explanation-Guided Learning
Nov 20, 2024



Explaining the decision-making processes of Artificial Intelligence (AI) models is crucial for addressing their "black box" nature, particularly in tasks like image classification. Traditional eXplainable AI (XAI) methods typically rely on unimodal explanations, either visual or textual, each with inherent limitations. Visual explanations highlight key regions but often lack rationale, while textual explanations provide context without spatial grounding. Further, both explanation types can be inconsistent or incomplete, limiting their reliability. To address these challenges, we propose a novel Multimodal Explanation-Guided Learning (MEGL) framework that leverages both visual and textual explanations to enhance model interpretability and improve classification performance. Our Saliency-Driven Textual Grounding (SDTG) approach integrates spatial information from visual explanations into textual rationales, providing spatially grounded and contextually rich explanations. Additionally, we introduce Textual Supervision on Visual Explanations to align visual explanations with textual rationales, even in cases where ground truth visual annotations are missing. A Visual Explanation Distribution Consistency loss further reinforces visual coherence by aligning the generated visual explanations with dataset-level patterns, enabling the model to effectively learn from incomplete multimodal supervision. We validate MEGL on two new datasets, Object-ME and Action-ME, for image classification with multimodal explanations. Experimental results demonstrate that MEGL outperforms previous approaches in prediction accuracy and explanation quality across both visual and textual domains. Our code will be made available upon the acceptance of the paper.