 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTMR-VLA:Vision-Language-Action Model for Magnetic Motion Control of Tri-leg Silicone-based Soft Robot
Feb 28, 2026In-vivo environments, magnetically actuated soft robots offer advantages such as wireless operation and precise control, showing promising potential for painless detection and therapeutic procedures. We developed a trileg magnetically driven soft robot (TMR) whose multi-legged design enables more flexible gaits and diverse motion patterns. For the silicone made of reconfigurable soft robots, its navigation ability can be separated into sequential motions, namely squatting, rotation, lifting a leg, walking and so on. Its motion and behavior depend on its bending shapes. To bridge motion type description and specific low-level voltage control, we introduced TMR-VLA, an end-to-end multi-modal system for a trileg magnetic soft robot capable of performing hybrid motion types, which is promising for developing a navigation ability by adapting its shape to language-constrained motion types. The TMR-VLA deploys embodied endoluminal localization ability from EndoVLA, and fuses sequential frames and natural language commands as input. Low-level voltage output is generated based on the current observation state and specific motion type description. The result shows the TMR-VLA can predict how the voltage applied to TMR will change the dynamics of a silicon-made soft robot. The TMR-VLA reached a 74% average success rate.
SurgAtt-Tracker: Online Surgical Attention Tracking via Temporal Proposal Reranking and Motion-Aware Refinement
Feb 24, 2026Accurate and stable field-of-view (FoV) guidance is critical for safe and efficient minimally invasive surgery, yet existing approaches often conflate visual attention estimation with downstream camera control or rely on direct object-centric assumptions. In this work, we formulate surgical attention tracking as a spatio-temporal learning problem and model surgeon focus as a dense attention heatmap, enabling continuous and interpretable frame-wise FoV guidance. We propose SurgAtt-Tracker, a holistic framework that robustly tracks surgical attention by exploiting temporal coherence through proposal-level reranking and motion-aware refinement, rather than direct regression. To support systematic training and evaluation, we introduce SurgAtt-1.16M, a large-scale benchmark with a clinically grounded annotation protocol that enables comprehensive heatmap-based attention analysis across procedures and institutions. Extensive experiments on multiple surgical datasets demonstrate that SurgAtt-Tracker consistently achieves state-of-the-art performance and strong robustness under occlusion, multi-instrument interference, and cross-domain settings. Beyond attention tracking, our approach provides a frame-wise FoV guidance signal that can directly support downstream robotic FoV planning and automatic camera control.
MedScope: Incentivizing "Think with Videos" for Clinical Reasoning via Coarse-to-Fine Tool Calling
Feb 11, 2026Long-form clinical videos are central to visual evidence-based decision-making, with growing importance for applications such as surgical robotics and related settings. However, current multimodal large language models typically process videos with passive sampling or weakly grounded inspection, which limits their ability to iteratively locate, verify, and justify predictions with temporally targeted evidence. To close this gap, we propose MedScope, a tool-using clinical video reasoning model that performs coarse-to-fine evidence seeking over long-form procedures. By interleaving intermediate reasoning with targeted tool calls and verification on retrieved observations, MedScope produces more accurate and trustworthy predictions that are explicitly grounded in temporally localized visual evidence. To address the lack of high-fidelity supervision, we build ClinVideoSuite, an evidence-centric, fine-grained clinical video suite. We then optimize MedScope with Grounding-Aware Group Relative Policy Optimization (GA-GRPO), which directly reinforces tool use with grounding-aligned rewards and evidence-weighted advantages. On full and fine-grained video understanding benchmarks, MedScope achieves state-of-the-art performance in both in-domain and out-of-domain evaluations. Our approach illuminates a path toward medical AI agents that can genuinely "think with videos" through tool-integrated reasoning. We will release our code, models, and data.
GeoLanG: Geometry-Aware Language-Guided Grasping with Unified RGB-D Multimodal Learning
Feb 04, 2026Language-guided grasping has emerged as a promising paradigm for enabling robots to identify and manipulate target objects through natural language instructions, yet it remains highly challenging in cluttered or occluded scenes. Existing methods often rely on multi-stage pipelines that separate object perception and grasping, which leads to limited cross-modal fusion, redundant computation, and poor generalization in cluttered, occluded, or low-texture scenes. To address these limitations, we propose GeoLanG, an end-to-end multi-task framework built upon the CLIP architecture that unifies visual and linguistic inputs into a shared representation space for robust semantic alignment and improved generalization. To enhance target discrimination under occlusion and low-texture conditions, we explore a more effective use of depth information through the Depth-guided Geometric Module (DGGM), which converts depth into explicit geometric priors and injects them into the attention mechanism without additional computational overhead. In addition, we propose Adaptive Dense Channel Integration, which adaptively balances the contributions of multi-layer features to produce more discriminative and generalizable visual representations. Extensive experiments on the OCID-VLG dataset, as well as in both simulation and real-world hardware, demonstrate that GeoLanG enables precise and robust language-guided grasping in complex, cluttered environments, paving the way toward more reliable multimodal robotic manipulation in real-world human-centric settings.
EndoARSS: Adapting Spatially-Aware Foundation Model for Efficient Activity Recognition and Semantic Segmentation in Endoscopic Surgery
Jun 07, 2025Endoscopic surgery is the gold standard for robotic-assisted minimally invasive surgery, offering significant advantages in early disease detection and precise interventions. However, the complexity of surgical scenes, characterized by high variability in different surgical activity scenarios and confused image features between targets and the background, presents challenges for surgical environment understanding. Traditional deep learning models often struggle with cross-activity interference, leading to suboptimal performance in each downstream task. To address this limitation, we explore multi-task learning, which utilizes the interrelated features between tasks to enhance overall task performance. In this paper, we propose EndoARSS, a novel multi-task learning framework specifically designed for endoscopy surgery activity recognition and semantic segmentation. Built upon the DINOv2 foundation model, our approach integrates Low-Rank Adaptation to facilitate efficient fine-tuning while incorporating Task Efficient Shared Low-Rank Adapters to mitigate gradient conflicts across diverse tasks. Additionally, we introduce the Spatially-Aware Multi-Scale Attention that enhances feature representation discrimination by enabling cross-spatial learning of global information. In order to evaluate the effectiveness of our framework, we present three novel datasets, MTLESD, MTLEndovis and MTLEndovis-Gen, tailored for endoscopic surgery scenarios with detailed annotations for both activity recognition and semantic segmentation tasks. Extensive experiments demonstrate that EndoARSS achieves remarkable performance across multiple benchmarks, significantly improving both accuracy and robustness in comparison to existing models. These results underscore the potential of EndoARSS to advance AI-driven endoscopic surgical systems, offering valuable insights for enhancing surgical safety and efficiency.
EndoVLA: Dual-Phase Vision-Language-Action Model for Autonomous Tracking in Endoscopy
May 21, 2025In endoscopic procedures, autonomous tracking of abnormal regions and following circumferential cutting markers can significantly reduce the cognitive burden on endoscopists. However, conventional model-based pipelines are fragile for each component (e.g., detection, motion planning) requires manual tuning and struggles to incorporate high-level endoscopic intent, leading to poor generalization across diverse scenes. Vision-Language-Action (VLA) models, which integrate visual perception, language grounding, and motion planning within an end-to-end framework, offer a promising alternative by semantically adapting to surgeon prompts without manual recalibration. Despite their potential, applying VLA models to robotic endoscopy presents unique challenges due to the complex and dynamic anatomical environments of the gastrointestinal (GI) tract. To address this, we introduce EndoVLA, designed specifically for continuum robots in GI interventions. Given endoscopic images and surgeon-issued tracking prompts, EndoVLA performs three core tasks: (1) polyp tracking, (2) delineation and following of abnormal mucosal regions, and (3) adherence to circular markers during circumferential cutting. To tackle data scarcity and domain shifts, we propose a dual-phase strategy comprising supervised fine-tuning on our EndoVLA-Motion dataset and reinforcement fine-tuning with task-aware rewards. Our approach significantly improves tracking performance in endoscopy and enables zero-shot generalization in diverse scenes and complex sequential tasks.
Can DeepSeek Reason Like a Surgeon? An Empirical Evaluation for Vision-Language Understanding in Robotic-Assisted Surgery
Apr 02, 2025DeepSeek series have demonstrated outstanding performance in general scene understanding, question-answering (QA), and text generation tasks, owing to its efficient training paradigm and strong reasoning capabilities. In this study, we investigate the dialogue capabilities of the DeepSeek model in robotic surgery scenarios, focusing on tasks such as Single Phrase QA, Visual QA, and Detailed Description. The Single Phrase QA tasks further include sub-tasks such as surgical instrument recognition, action understanding, and spatial position analysis. We conduct extensive evaluations using publicly available datasets, including EndoVis18 and CholecT50, along with their corresponding dialogue data. Our comprehensive evaluation results indicate that, when provided with specific prompts, DeepSeek-V3 performs well in surgical instrument and tissue recognition tasks However, DeepSeek-V3 exhibits significant limitations in spatial position analysis and struggles to understand surgical actions accurately. Additionally, our findings reveal that, under general prompts, DeepSeek-V3 lacks the ability to effectively analyze global surgical concepts and fails to provide detailed insights into surgical scenarios. Based on our observations, we argue that the DeepSeek-V3 is not ready for vision-language tasks in surgical contexts without fine-tuning on surgery-specific datasets.
EndoChat: Grounded Multimodal Large Language Model for Endoscopic Surgery
Jan 20, 2025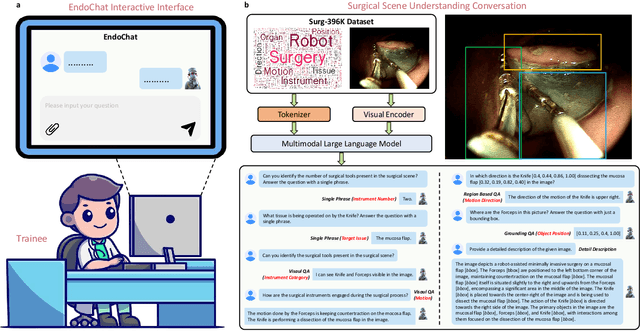
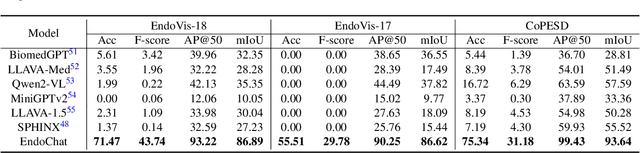
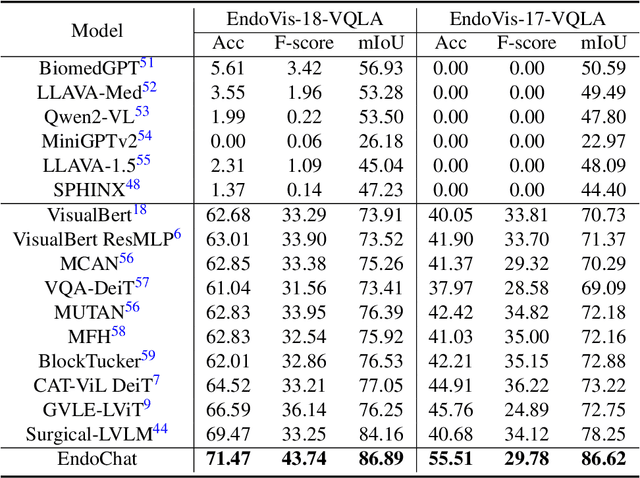
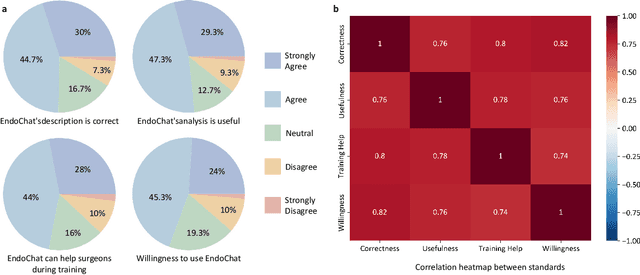
Recently, Multimodal Large Language Models (MLLMs) have demonstrated their immense potential in computer-aided diagnosis and decision-making. In the context of robotic-assisted surgery, MLLMs can serve as effective tools for surgical training and guidance. However, there is still a lack of MLLMs specialized for surgical scene understanding in clinical applications. In this work, we introduce EndoChat to address various dialogue paradigms and subtasks in surgical scene understanding that surgeons encounter. To train our EndoChat, we construct the Surg-396K dataset through a novel pipeline that systematically extracts surgical information and generates structured annotations based on collected large-scale endoscopic surgery datasets. Furthermore, we introduce a multi-scale visual token interaction mechanism and a visual contrast-based reasoning mechanism to enhance the model's representation learning and reasoning capabilities. Our model achieves state-of-the-art performance across five dialogue paradigms and eight surgical scene understanding tasks. Additionally, we conduct evaluations with professional surgeons, most of whom provide positive feedback on collaborating with EndoChat. Overall, these results demonstrate that our EndoChat has great potential to significantly advance training and automation in robotic-assisted surgery.
TSUBF-Net: Trans-Spatial UNet-like Network with Bi-direction Fusion for Segmentation of Adenoid Hypertrophy in CT
Dec 01, 2024Adenoid hypertrophy stands as a common cause of obstructive sleep apnea-hypopnea syndrome in children. It is characterized by snoring, nasal congestion, and growth disorders. Computed Tomography (CT) emerges as a pivotal medical imaging modality, utilizing X-rays and advanced computational techniques to generate detailed cross-sectional images. Within the realm of pediatric airway assessments, CT imaging provides an insightful perspective on the shape and volume of enlarged adenoids. Despite the advances of deep learning methods for medical imaging analysis, there remains an emptiness in the segmentation of adenoid hypertrophy in CT scans. To address this research gap, we introduce TSUBF-Nett (Trans-Spatial UNet-like Network based on Bi-direction Fusion), a 3D medical image segmentation framework. TSUBF-Net is engineered to effectively discern intricate 3D spatial interlayer features in CT scans and enhance the extraction of boundary-blurring features. Notably, we propose two innovative modules within the U-shaped network architecture:the Trans-Spatial Perception module (TSP) and the Bi-directional Sampling Collaborated Fusion module (BSCF).These two modules are in charge of operating during the sampling process and strategically fusing down-sampled and up-sampled features, respectively. Furthermore, we introduce the Sobel loss term, which optimizes the smoothness of the segmentation results and enhances model accuracy. Extensive 3D segmentation experiments are conducted on several datasets. TSUBF-Net is superior to the state-of-the-art methods with the lowest HD95: 7.03, IoU:85.63, and DSC: 92.26 on our own AHSD dataset. The results in the other two public datasets also demonstrate that our methods can robustly and effectively address the challenges of 3D segmentation in CT scans.
ETSM: Automating Dissection Trajectory Suggestion and Confidence Map-Based Safety Margin Prediction for Robot-assisted Endoscopic Submucosal Dissection
Nov 28, 2024Robot-assisted Endoscopic Submucosal Dissection (ESD) improves the surgical procedure by providing a more comprehensive view through advanced robotic instruments and bimanual operation, thereby enhancing dissection efficiency and accuracy. Accurate prediction of dissection trajectories is crucial for better decision-making, reducing intraoperative errors, and improving surgical training. Nevertheless, predicting these trajectories is challenging due to variable tumor margins and dynamic visual conditions. To address this issue, we create the ESD Trajectory and Confidence Map-based Safety Margin (ETSM) dataset with $1849$ short clips, focusing on submucosal dissection with a dual-arm robotic system. We also introduce a framework that combines optimal dissection trajectory prediction with a confidence map-based safety margin, providing a more secure and intelligent decision-making tool to minimize surgical risks for ESD procedures. Additionally, we propose the Regression-based Confidence Map Prediction Network (RCMNet), which utilizes a regression approach to predict confidence maps for dissection areas, thereby delineating various levels of safety margins. We evaluate our RCMNet using three distinct experimental setups: in-domain evaluation, robustness assessment, and out-of-domain evaluation. Experimental results show that our approach excels in the confidence map-based safety margin prediction task, achieving a mean absolute error (MAE) of only $3.18$. To the best of our knowledge, this is the first study to apply a regression approach for visual guidance concerning delineating varying safety levels of dissection areas. Our approach bridges gaps in current research by improving prediction accuracy and enhancing the safety of the dissection process, showing great clinical significance in practice.