 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore than Segmentation: Benchmarking SAM 3 for Segmentation, 3D Perception, and Reconstruction in Robotic Surgery
Dec 10, 2025The recent SAM 3 and SAM 3D have introduced significant advancements over the predecessor, SAM 2, particularly with the integration of language-based segmentation and enhanced 3D perception capabilities. SAM 3 supports zero-shot segmentation across a wide range of prompts, including point, bounding box, and language-based prompts, allowing for more flexible and intuitive interactions with the model. In this empirical evaluation, we assess the performance of SAM 3 in robot-assisted surgery, benchmarking its zero-shot segmentation with point and bounding box prompts and exploring its effectiveness in dynamic video tracking, alongside its newly introduced language prompt segmentation. While language prompts show potential, their performance in the surgical domain is currently suboptimal, highlighting the need for further domain-specific training. Additionally, we investigate SAM 3D's depth reconstruction abilities, demonstrating its capacity to process surgical scene data and reconstruct 3D anatomical structures from 2D images. Through comprehensive testing on the MICCAI EndoVis 2017 and EndoVis 2018 benchmarks, SAM 3 shows clear improvements over SAM and SAM 2 in both image and video segmentation under spatial prompts, while the zero-shot evaluations of SAM 3D on SCARED, StereoMIS, and EndoNeRF indicate strong monocular depth estimation and realistic 3D instrument reconstruction, yet also reveal remaining limitations in complex, highly dynamic surgical scenes.
SAM 2 in Robotic Surgery: An Empirical Evaluation for Robustness and Generalization in Surgical Video Segmentation
Aug 08, 2024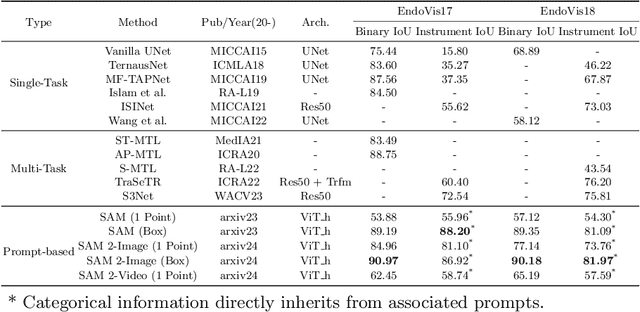



The recent Segment Anything Model (SAM) 2 has demonstrated remarkable foundational competence in semantic segmentation, with its memory mechanism and mask decoder further addressing challenges in video tracking and object occlusion, thereby achieving superior results in interactive segmentation for both images and videos. Building upon our previous empirical studies, we further explore the zero-shot segmentation performance of SAM 2 in robot-assisted surgery based on prompts, alongside its robustness against real-world corruption. For static images, we employ two forms of prompts: 1-point and bounding box, while for video sequences, the 1-point prompt is applied to the initial frame. Through extensive experimentation on the MICCAI EndoVis 2017 and EndoVis 2018 benchmarks, SAM 2, when utilizing bounding box prompts, outperforms state-of-the-art (SOTA) methods in comparative evaluations. The results with point prompts also exhibit a substantial enhancement over SAM's capabilities, nearing or even surpassing existing unprompted SOTA methodologies. Besides, SAM 2 demonstrates improved inference speed and less performance degradation against various image corruption. Although slightly unsatisfactory results remain in specific edges or regions, SAM 2's robust adaptability to 1-point prompts underscores its potential for downstream surgical tasks with limited prompt requirements.
Adapting SAM for Surgical Instrument Tracking and Segmentation in Endoscopic Submucosal Dissection Videos
Apr 16, 2024



The precise tracking and segmentation of surgical instruments have led to a remarkable enhancement in the efficiency of surgical procedures. However, the challenge lies in achieving accurate segmentation of surgical instruments while minimizing the need for manual annotation and reducing the time required for the segmentation process. To tackle this, we propose a novel framework for surgical instrument segmentation and tracking. Specifically, with a tiny subset of frames for segmentation, we ensure accurate segmentation across the entire surgical video. Our method adopts a two-stage approach to efficiently segment videos. Initially, we utilize the Segment-Anything (SAM) model, which has been fine-tuned using the Low-Rank Adaptation (LoRA) on the EndoVis17 Dataset. The fine-tuned SAM model is applied to segment the initial frames of the video accurately. Subsequently, we deploy the XMem++ tracking algorithm to follow the annotated frames, thereby facilitating the segmentation of the entire video sequence. This workflow enables us to precisely segment and track objects within the video. Through extensive evaluation of the in-distribution dataset (EndoVis17) and the out-of-distribution datasets (EndoVis18 \& the endoscopic submucosal dissection surgery (ESD) dataset), our framework demonstrates exceptional accuracy and robustness, thus showcasing its potential to advance the automated robotic-assisted surgery.