 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHy-MT2: A Family of Fast, Efficient and Powerful Multilingual Translation Models in the Wild
May 21, 2026Hy-MT2 is a family of fast-thinking multilingual translation models designed for complex real-world scenarios. It includes three model sizes: 1.8B, 7B, and 30B-A3B (MoE), all of which support translation among 33 languages and effectively follow translation instructions in multiple languages. For on-device deployment, with AngelSlim 1.25-bit extreme quantization, the 1.8B model requires only 440 MB of storage and improves inference speed by 1.5x. Multi-dimensional evaluations show that Hy-MT2 delivers outstanding performance across general, real-world business, domain-specific, and instruction-following translation tasks. The 7B and 30B models outperform open-source models such as DeepSeek-V4-Pro and Kimi K2.6 in fast-thinking mode, while the lightweight 1.8B model also surpasses mainstream commercial APIs from providers such as Microsoft and Doubao overall.
SkillSafetyBench: Evaluating Agent Safety under Skill-Facing Attack Surfaces
May 12, 2026Reusable skills are becoming a common interface for extending large language model agents, packaging procedural guidance with access to files, tools, memory, and execution environments. However, this modularity introduces attack surfaces that are largely missed by existing safety evaluations: even when the user request is benign, task-relevant skill materials or local artifacts can steer an agent toward unsafe actions. We present SkillSafetyBench, a runnable benchmark for evaluating such skill-mediated safety failures. SkillSafetyBench includes 155 adversarial cases across 47 tasks, 6 risk domains, and 30 safety categories, each evaluated with a case-specific rule-based verifier. Experiments with multiple CLI agents and model backends show that localized non-user attacks can consistently induce unsafe behavior, with distinct failure patterns across domains, attack methods, and scaffold-model pairings. Our findings suggest that agent safety depends not only on model-level alignment, but also on how agents interpret skills, trust workflow context, and act through executable environments.
Self-Distillation for Multi-Token Prediction
Mar 25, 2026As Large Language Models (LLMs) scale up, inference efficiency becomes a critical bottleneck. Multi-Token Prediction (MTP) could accelerate LLM inference by predicting multiple future tokens in parallel. However, existing MTP approaches still face two challenges: limited acceptance rates of MTP heads, and difficulties in jointly training multiple MTP heads. Therefore, we propose MTP-D, a simple yet effective self-distillation method with minimal additional training cost, which boosts MTP head acceptance rates (+7.5\%) while maximumly preserving main-head performance. We also introduce a looped extension strategy for MTP-D, enabling effective and economical MTP head extension and further significant inference speedup to 1-head MTP (+220.4\%). Moreover, we systematically explore and validate key insights on the distillation strategies and the potential scalability of MTP through extensive experiments on seven benchmarks. These results demonstrate that our MTP-D and looped extension strategy effectively enhance MTP-head performance and inference efficiency, facilitating the practical usage of MTP in LLMs.
SurgAtt-Tracker: Online Surgical Attention Tracking via Temporal Proposal Reranking and Motion-Aware Refinement
Feb 24, 2026Accurate and stable field-of-view (FoV) guidance is critical for safe and efficient minimally invasive surgery, yet existing approaches often conflate visual attention estimation with downstream camera control or rely on direct object-centric assumptions. In this work, we formulate surgical attention tracking as a spatio-temporal learning problem and model surgeon focus as a dense attention heatmap, enabling continuous and interpretable frame-wise FoV guidance. We propose SurgAtt-Tracker, a holistic framework that robustly tracks surgical attention by exploiting temporal coherence through proposal-level reranking and motion-aware refinement, rather than direct regression. To support systematic training and evaluation, we introduce SurgAtt-1.16M, a large-scale benchmark with a clinically grounded annotation protocol that enables comprehensive heatmap-based attention analysis across procedures and institutions. Extensive experiments on multiple surgical datasets demonstrate that SurgAtt-Tracker consistently achieves state-of-the-art performance and strong robustness under occlusion, multi-instrument interference, and cross-domain settings. Beyond attention tracking, our approach provides a frame-wise FoV guidance signal that can directly support downstream robotic FoV planning and automatic camera control.
UniSurg: A Video-Native Foundation Model for Universal Understanding of Surgical Videos
Feb 05, 2026While foundation models have advanced surgical video analysis, current approaches rely predominantly on pixel-level reconstruction objectives that waste model capacity on low-level visual details - such as smoke, specular reflections, and fluid motion - rather than semantic structures essential for surgical understanding. We present UniSurg, a video-native foundation model that shifts the learning paradigm from pixel-level reconstruction to latent motion prediction. Built on the Video Joint Embedding Predictive Architecture (V-JEPA), UniSurg introduces three key technical innovations tailored to surgical videos: 1) motion-guided latent prediction to prioritize semantically meaningful regions, 2) spatiotemporal affinity self-distillation to enforce relational consistency, and 3) feature diversity regularization to prevent representation collapse in texture-sparse surgical scenes. To enable large-scale pretraining, we curate UniSurg-15M, the largest surgical video dataset to date, comprising 3,658 hours of video from 50 sources across 13 anatomical regions. Extensive experiments across 17 benchmarks demonstrate that UniSurg significantly outperforms state-of-the-art methods on surgical workflow recognition (+14.6% F1 on EgoSurgery, +10.3% on PitVis), action triplet recognition (39.54% mAP-IVT on CholecT50), skill assessment, polyp segmentation, and depth estimation. These results establish UniSurg as a new standard for universal, motion-oriented surgical video understanding.
Bridging Vision and Language for Robust Context-Aware Surgical Point Tracking: The VL-SurgPT Dataset and Benchmark
Nov 15, 2025Accurate point tracking in surgical environments remains challenging due to complex visual conditions, including smoke occlusion, specular reflections, and tissue deformation. While existing surgical tracking datasets provide coordinate information, they lack the semantic context necessary to understand tracking failure mechanisms. We introduce VL-SurgPT, the first large-scale multimodal dataset that bridges visual tracking with textual descriptions of point status in surgical scenes. The dataset comprises 908 in vivo video clips, including 754 for tissue tracking (17,171 annotated points across five challenging scenarios) and 154 for instrument tracking (covering seven instrument types with detailed keypoint annotations). We establish comprehensive benchmarks using eight state-of-the-art tracking methods and propose TG-SurgPT, a text-guided tracking approach that leverages semantic descriptions to improve robustness in visually challenging conditions. Experimental results demonstrate that incorporating point status information significantly improves tracking accuracy and reliability, particularly in adverse visual scenarios where conventional vision-only methods struggle. By bridging visual and linguistic modalities, VL-SurgPT enables the development of context-aware tracking systems crucial for advancing computer-assisted surgery applications that can maintain performance even under challenging intraoperative conditions.
EASE: Practical and Efficient Safety Alignment for Small Language Models
Nov 09, 2025Small language models (SLMs) are increasingly deployed on edge devices, making their safety alignment crucial yet challenging. Current shallow alignment methods that rely on direct refusal of malicious queries fail to provide robust protection, particularly against adversarial jailbreaks. While deliberative safety reasoning alignment offers deeper alignment for defending against sophisticated attacks, effectively implanting such reasoning capability in SLMs with limited capabilities remains an open challenge. Moreover, safety reasoning incurs significant computational overhead as models apply reasoning to nearly all queries, making it impractical for resource-constrained edge deployment scenarios that demand rapid responses. We propose EASE, a novel framework that enables practical and Efficient safety Alignment for Small languagE models. Our approach first identifies the optimal safety reasoning teacher that can effectively distill safety reasoning capabilities to SLMs. We then align models to selectively activate safety reasoning for dangerous adversarial jailbreak queries while providing direct responses to straightforward malicious queries and general helpful tasks. This selective mechanism enables small models to maintain robust safety guarantees against sophisticated attacks while preserving computational efficiency for benign interactions. Experimental results demonstrate that EASE reduces jailbreak attack success rates by up to 17% compared to shallow alignment methods while reducing inference overhead by up to 90% compared to deliberative safety reasoning alignment, making it practical for SLMs real-world edge deployments.
Comparative validation of surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation in endoscopy: Results of the PhaKIR 2024 challenge
Jul 22, 2025Reliable recognition and localization of surgical instruments in endoscopic video recordings are foundational for a wide range of applications in computer- and robot-assisted minimally invasive surgery (RAMIS), including surgical training, skill assessment, and autonomous assistance. However, robust performance under real-world conditions remains a significant challenge. Incorporating surgical context - such as the current procedural phase - has emerged as a promising strategy to improve robustness and interpretability. To address these challenges, we organized the Surgical Procedure Phase, Keypoint, and Instrument Recognition (PhaKIR) sub-challenge as part of the Endoscopic Vision (EndoVis) challenge at MICCAI 2024. We introduced a novel, multi-center dataset comprising thirteen full-length laparoscopic cholecystectomy videos collected from three distinct medical institutions, with unified annotations for three interrelated tasks: surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation. Unlike existing datasets, ours enables joint investigation of instrument localization and procedural context within the same data while supporting the integration of temporal information across entire procedures. We report results and findings in accordance with the BIAS guidelines for biomedical image analysis challenges. The PhaKIR sub-challenge advances the field by providing a unique benchmark for developing temporally aware, context-driven methods in RAMIS and offers a high-quality resource to support future research in surgical scene understanding.
Point Tracking in Surgery--The 2024 Surgical Tattoos in Infrared (STIR) Challenge
Mar 31, 2025Understanding tissue motion in surgery is crucial to enable applications in downstream tasks such as segmentation, 3D reconstruction, virtual tissue landmarking, autonomous probe-based scanning, and subtask autonomy. Labeled data are essential to enabling algorithms in these downstream tasks since they allow us to quantify and train algorithms. This paper introduces a point tracking challenge to address this, wherein participants can submit their algorithms for quantification. The submitted algorithms are evaluated using a dataset named surgical tattoos in infrared (STIR), with the challenge aptly named the STIR Challenge 2024. The STIR Challenge 2024 comprises two quantitative components: accuracy and efficiency. The accuracy component tests the accuracy of algorithms on in vivo and ex vivo sequences. The efficiency component tests the latency of algorithm inference. The challenge was conducted as a part of MICCAI EndoVis 2024. In this challenge, we had 8 total teams, with 4 teams submitting before and 4 submitting after challenge day. This paper details the STIR Challenge 2024, which serves to move the field towards more accurate and efficient algorithms for spatial understanding in surgery. In this paper we summarize the design, submissions, and results from the challenge. The challenge dataset is available here: https://zenodo.org/records/14803158 , and the code for baseline models and metric calculation is available here: https://github.com/athaddius/STIRMetrics
Endo-TTAP: Robust Endoscopic Tissue Tracking via Multi-Facet Guided Attention and Hybrid Flow-point Supervision
Mar 28, 2025
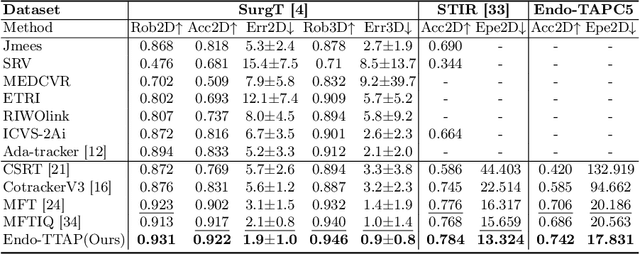
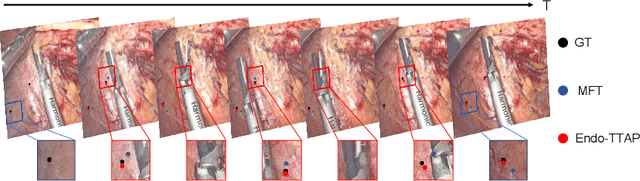

Accurate tissue point tracking in endoscopic videos is critical for robotic-assisted surgical navigation and scene understanding, but remains challenging due to complex deformations, instrument occlusion, and the scarcity of dense trajectory annotations. Existing methods struggle with long-term tracking under these conditions due to limited feature utilization and annotation dependence. We present Endo-TTAP, a novel framework addressing these challenges through: (1) A Multi-Facet Guided Attention (MFGA) module that synergizes multi-scale flow dynamics, DINOv2 semantic embeddings, and explicit motion patterns to jointly predict point positions with uncertainty and occlusion awareness; (2) A two-stage curriculum learning strategy employing an Auxiliary Curriculum Adapter (ACA) for progressive initialization and hybrid supervision. Stage I utilizes synthetic data with optical flow ground truth for uncertainty-occlusion regularization, while Stage II combines unsupervised flow consistency and semi-supervised learning with refined pseudo-labels from off-the-shelf trackers. Extensive validation on two MICCAI Challenge datasets and our collected dataset demonstrates that Endo-TTAP achieves state-of-the-art performance in tissue point tracking, particularly in scenarios characterized by complex endoscopic conditions. The source code and dataset will be available at https://anonymous.4open.science/r/Endo-TTAP-36E5.