 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interpretable Multi-Plane Fusion Framework With Kolmogorov-Arnold Network Guided Attention Enhancement for Alzheimer's Disease Diagnosis
Aug 08, 2025Alzheimer's disease (AD) is a progressive neurodegenerative disorder that severely impairs cognitive function and quality of life. Timely intervention in AD relies heavily on early and precise diagnosis, which remains challenging due to the complex and subtle structural changes in the brain. Most existing deep learning methods focus only on a single plane of structural magnetic resonance imaging (sMRI) and struggle to accurately capture the complex and nonlinear relationships among pathological regions of the brain, thus limiting their ability to precisely identify atrophic features. To overcome these limitations, we propose an innovative framework, MPF-KANSC, which integrates multi-plane fusion (MPF) for combining features from the coronal, sagittal, and axial planes, and a Kolmogorov-Arnold Network-guided spatial-channel attention mechanism (KANSC) to more effectively learn and represent sMRI atrophy features. Specifically, the proposed model enables parallel feature extraction from multiple anatomical planes, thus capturing more comprehensive structural information. The KANSC attention mechanism further leverages a more flexible and accurate nonlinear function approximation technique, facilitating precise identification and localization of disease-related abnormalities. Experiments on the ADNI dataset confirm that the proposed MPF-KANSC achieves superior performance in AD diagnosis. Moreover, our findings provide new evidence of right-lateralized asymmetry in subcortical structural changes during AD progression, highlighting the model's promising interpretability.
ETSM: Automating Dissection Trajectory Suggestion and Confidence Map-Based Safety Margin Prediction for Robot-assisted Endoscopic Submucosal Dissection
Nov 28, 2024Robot-assisted Endoscopic Submucosal Dissection (ESD) improves the surgical procedure by providing a more comprehensive view through advanced robotic instruments and bimanual operation, thereby enhancing dissection efficiency and accuracy. Accurate prediction of dissection trajectories is crucial for better decision-making, reducing intraoperative errors, and improving surgical training. Nevertheless, predicting these trajectories is challenging due to variable tumor margins and dynamic visual conditions. To address this issue, we create the ESD Trajectory and Confidence Map-based Safety Margin (ETSM) dataset with $1849$ short clips, focusing on submucosal dissection with a dual-arm robotic system. We also introduce a framework that combines optimal dissection trajectory prediction with a confidence map-based safety margin, providing a more secure and intelligent decision-making tool to minimize surgical risks for ESD procedures. Additionally, we propose the Regression-based Confidence Map Prediction Network (RCMNet), which utilizes a regression approach to predict confidence maps for dissection areas, thereby delineating various levels of safety margins. We evaluate our RCMNet using three distinct experimental setups: in-domain evaluation, robustness assessment, and out-of-domain evaluation. Experimental results show that our approach excels in the confidence map-based safety margin prediction task, achieving a mean absolute error (MAE) of only $3.18$. To the best of our knowledge, this is the first study to apply a regression approach for visual guidance concerning delineating varying safety levels of dissection areas. Our approach bridges gaps in current research by improving prediction accuracy and enhancing the safety of the dissection process, showing great clinical significance in practice.
PDZSeg: Adapting the Foundation Model for Dissection Zone Segmentation with Visual Prompts in Robot-assisted Endoscopic Submucosal Dissection
Nov 27, 2024Purpose: Endoscopic surgical environments present challenges for dissection zone segmentation due to unclear boundaries between tissue types, leading to segmentation errors where models misidentify or overlook edges. This study aims to provide precise dissection zone suggestions during endoscopic submucosal dissection (ESD) procedures, enhancing ESD safety. Methods: We propose the Prompted-based Dissection Zone Segmentation (PDZSeg) model, designed to leverage diverse visual prompts such as scribbles and bounding boxes. By overlaying these prompts onto images and fine-tuning a foundational model on a specialized dataset, our approach improves segmentation performance and user experience through flexible input methods. Results: The PDZSeg model was validated using three experimental setups: in-domain evaluation, variability in visual prompt availability, and robustness assessment. Using the ESD-DZSeg dataset, results show that our method outperforms state-of-the-art segmentation approaches. This is the first study to integrate visual prompt design into dissection zone segmentation. Conclusion: The PDZSeg model effectively utilizes visual prompts to enhance segmentation performance and user experience, supported by the novel ESD-DZSeg dataset as a benchmark for dissection zone segmentation in ESD. Our work establishes a foundation for future research.
CoPESD: A Multi-Level Surgical Motion Dataset for Training Large Vision-Language Models to Co-Pilot Endoscopic Submucosal Dissection
Oct 10, 2024



submucosal dissection (ESD) enables rapid resection of large lesions, minimizing recurrence rates and improving long-term overall survival. Despite these advantages, ESD is technically challenging and carries high risks of complications, necessitating skilled surgeons and precise instruments. Recent advancements in Large Visual-Language Models (LVLMs) offer promising decision support and predictive planning capabilities for robotic systems, which can augment the accuracy of ESD and reduce procedural risks. However, existing datasets for multi-level fine-grained ESD surgical motion understanding are scarce and lack detailed annotations. In this paper, we design a hierarchical decomposition of ESD motion granularity and introduce a multi-level surgical motion dataset (CoPESD) for training LVLMs as the robotic \textbf{Co}-\textbf{P}ilot of \textbf{E}ndoscopic \textbf{S}ubmucosal \textbf{D}issection. CoPESD includes 17,679 images with 32,699 bounding boxes and 88,395 multi-level motions, from over 35 hours of ESD videos for both robot-assisted and conventional surgeries. CoPESD enables granular analysis of ESD motions, focusing on the complex task of submucosal dissection. Extensive experiments on the LVLMs demonstrate the effectiveness of CoPESD in training LVLMs to predict following surgical robotic motions. As the first multimodal ESD motion dataset, CoPESD supports advanced research in ESD instruction-following and surgical automation. The dataset is available at \href{https://github.com/gkw0010/CoPESD}{https://github.com/gkw0010/CoPESD.}}
AMFD: Distillation via Adaptive Multimodal Fusion for Multispectral Pedestrian Detection
May 21, 2024
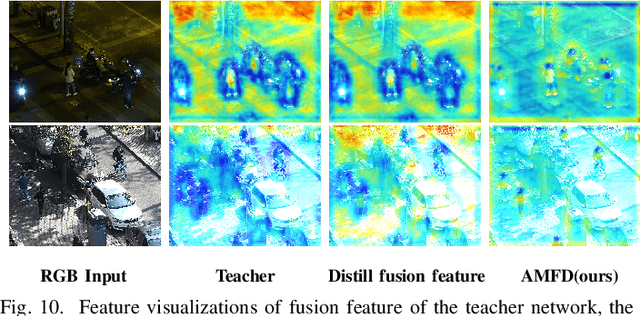


Multispectral pedestrian detection has been shown to be effective in improving performance within complex illumination scenarios. However, prevalent double-stream networks in multispectral detection employ two separate feature extraction branches for multi-modal data, leading to nearly double the inference time compared to single-stream networks utilizing only one feature extraction branch. This increased inference time has hindered the widespread employment of multispectral pedestrian detection in embedded devices for autonomous systems. To address this limitation, various knowledge distillation methods have been proposed. However, traditional distillation methods focus only on the fusion features and ignore the large amount of information in the original multi-modal features, thereby restricting the student network's performance. To tackle the challenge, we introduce the Adaptive Modal Fusion Distillation (AMFD) framework, which can fully utilize the original modal features of the teacher network. Specifically, a Modal Extraction Alignment (MEA) module is utilized to derive learning weights for student networks, integrating focal and global attention mechanisms. This methodology enables the student network to acquire optimal fusion strategies independent from that of teacher network without necessitating an additional feature fusion module. Furthermore, we present the SMOD dataset, a well-aligned challenging multispectral dataset for detection. Extensive experiments on the challenging KAIST, LLVIP and SMOD datasets are conducted to validate the effectiveness of AMFD. The results demonstrate that our method outperforms existing state-of-the-art methods in both reducing log-average Miss Rate and improving mean Average Precision. The code is available at https://github.com/bigD233/AMFD.git.
LighTDiff: Surgical Endoscopic Image Low-Light Enhancement with T-Diffusion
May 17, 2024



Advances in endoscopy use in surgeries face challenges like inadequate lighting. Deep learning, notably the Denoising Diffusion Probabilistic Model (DDPM), holds promise for low-light image enhancement in the medical field. However, DDPMs are computationally demanding and slow, limiting their practical medical applications. To bridge this gap, we propose a lightweight DDPM, dubbed LighTDiff. It adopts a T-shape model architecture to capture global structural information using low-resolution images and gradually recover the details in subsequent denoising steps. We further prone the model to significantly reduce the model size while retaining performance. While discarding certain downsampling operations to save parameters leads to instability and low efficiency in convergence during the training, we introduce a Temporal Light Unit (TLU), a plug-and-play module, for more stable training and better performance. TLU associates time steps with denoised image features, establishing temporal dependencies of the denoising steps and improving denoising outcomes. Moreover, while recovering images using the diffusion model, potential spectral shifts were noted. We further introduce a Chroma Balancer (CB) to mitigate this issue. Our LighTDiff outperforms many competitive LLIE methods with exceptional computational efficiency.
Adapting SAM for Surgical Instrument Tracking and Segmentation in Endoscopic Submucosal Dissection Videos
Apr 16, 2024



The precise tracking and segmentation of surgical instruments have led to a remarkable enhancement in the efficiency of surgical procedures. However, the challenge lies in achieving accurate segmentation of surgical instruments while minimizing the need for manual annotation and reducing the time required for the segmentation process. To tackle this, we propose a novel framework for surgical instrument segmentation and tracking. Specifically, with a tiny subset of frames for segmentation, we ensure accurate segmentation across the entire surgical video. Our method adopts a two-stage approach to efficiently segment videos. Initially, we utilize the Segment-Anything (SAM) model, which has been fine-tuned using the Low-Rank Adaptation (LoRA) on the EndoVis17 Dataset. The fine-tuned SAM model is applied to segment the initial frames of the video accurately. Subsequently, we deploy the XMem++ tracking algorithm to follow the annotated frames, thereby facilitating the segmentation of the entire video sequence. This workflow enables us to precisely segment and track objects within the video. Through extensive evaluation of the in-distribution dataset (EndoVis17) and the out-of-distribution datasets (EndoVis18 \& the endoscopic submucosal dissection surgery (ESD) dataset), our framework demonstrates exceptional accuracy and robustness, thus showcasing its potential to advance the automated robotic-assisted surgery.
OSSAR: Towards Open-Set Surgical Activity Recognition in Robot-assisted Surgery
Feb 10, 2024



In the realm of automated robotic surgery and computer-assisted interventions, understanding robotic surgical activities stands paramount. Existing algorithms dedicated to surgical activity recognition predominantly cater to pre-defined closed-set paradigms, ignoring the challenges of real-world open-set scenarios. Such algorithms often falter in the presence of test samples originating from classes unseen during training phases. To tackle this problem, we introduce an innovative Open-Set Surgical Activity Recognition (OSSAR) framework. Our solution leverages the hyperspherical reciprocal point strategy to enhance the distinction between known and unknown classes in the feature space. Additionally, we address the issue of over-confidence in the closed set by refining model calibration, avoiding misclassification of unknown classes as known ones. To support our assertions, we establish an open-set surgical activity benchmark utilizing the public JIGSAWS dataset. Besides, we also collect a novel dataset on endoscopic submucosal dissection for surgical activity tasks. Extensive comparisons and ablation experiments on these datasets demonstrate the significant outperformance of our method over existing state-of-the-art approaches. Our proposed solution can effectively address the challenges of real-world surgical scenarios. Our code is publicly accessible at https://github.com/longbai1006/OSSAR.
A Miniature 3-DoF Flexible Parallel Robotic Wrist Using NiTi Wires for Gastrointestinal Endoscopic Surgery
Jul 11, 2022
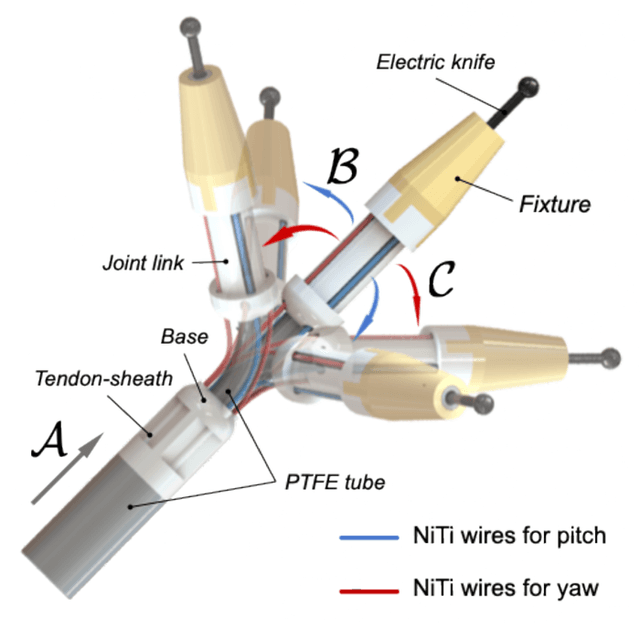
Gastrointestinal endoscopic surgery (GES) has high requirements for instruments' size and distal dexterity, because of the narrow endoscopic channel and long, tortuous human gastrointestinal tract. This paper utilized Nickel-Titanium (NiTi) wires to develop a miniature 3-DoF (pitch-yaw-translation) flexible parallel robotic wrist (FPRW). Additionally, we assembled an electric knife on the wrist's connection interface and then teleoperated it to perform an endoscopic submucosal dissection (ESD) on porcine stomachs. The effective performance in each ESD workflow proves that the designed FPRW has sufficient workspace, high distal dexterity, and high positioning accuracy.
BAANet: Learning Bi-directional Adaptive Attention Gates for Multispectral Pedestrian Detection
Dec 04, 2021
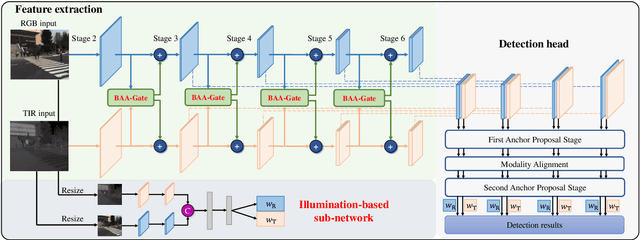
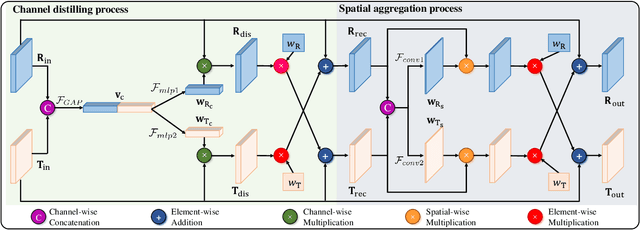
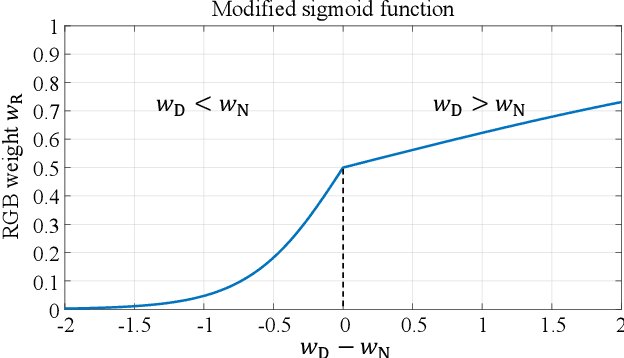
Thermal infrared (TIR) image has proven effectiveness in providing temperature cues to the RGB features for multispectral pedestrian detection. Most existing methods directly inject the TIR modality into the RGB-based framework or simply ensemble the results of two modalities. This, however, could lead to inferior detection performance, as the RGB and TIR features generally have modality-specific noise, which might worsen the features along with the propagation of the network. Therefore, this work proposes an effective and efficient cross-modality fusion module called Bi-directional Adaptive Attention Gate (BAA-Gate). Based on the attention mechanism, the BAA-Gate is devised to distill the informative features and recalibrate the representations asymptotically. Concretely, a bi-direction multi-stage fusion strategy is adopted to progressively optimize features of two modalities and retain their specificity during the propagation. Moreover, an adaptive interaction of BAA-Gate is introduced by the illumination-based weighting strategy to adaptively adjust the recalibrating and aggregating strength in the BAA-Gate and enhance the robustness towards illumination changes. Considerable experiments on the challenging KAIST dataset demonstrate the superior performance of our method with satisfactory speed.