 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Pixels and Words: Mask-Aware Local Semantic Fusion for Multimodal Media Verification
Mar 27, 2026As multimodal misinformation becomes more sophisticated, its detection and grounding are crucial. However, current multimodal verification methods, relying on passive holistic fusion, struggle with sophisticated misinformation. Due to 'feature dilution,' global alignments tend to average out subtle local semantic inconsistencies, effectively masking the very conflicts they are designed to find. We introduce MaLSF (Mask-aware Local Semantic Fusion), a novel framework that shifts the paradigm to active, bidirectional verification, mimicking human cognitive cross-referencing. MaLSF utilizes mask-label pairs as semantic anchors to bridge pixels and words. Its core mechanism features two innovations: 1) a Bidirectional Cross-modal Verification (BCV) module that acts as an interrogator, using parallel query streams (Text-as-Query and Image-as-Query) to explicitly pinpoint conflicts; and 2) a Hierarchical Semantic Aggregation (HSA) module that intelligently aggregates these multi-granularity conflict signals for task-specific reasoning. In addition, to extract fine-grained mask-label pairs, we introduce a set of diverse mask-label pair extraction parsers. MaLSF achieves state-of-the-art performance on both the DGM4 and multimodal fake news detection tasks. Extensive ablation studies and visualization results further verify its effectiveness and interpretability.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Knot So Simple: A Minimalistic Environment for Spatial Reasoning
May 23, 2025We propose KnotGym, an interactive environment for complex, spatial reasoning and manipulation. KnotGym includes goal-oriented rope manipulation tasks with varying levels of complexity, all requiring acting from pure image observations. Tasks are defined along a clear and quantifiable axis of complexity based on the number of knot crossings, creating a natural generalization test. KnotGym has a simple observation space, allowing for scalable development, yet it highlights core challenges in integrating acute perception, spatial reasoning, and grounded manipulation. We evaluate methods of different classes, including model-based RL, model-predictive control, and chain-of-thought reasoning, and illustrate the challenges KnotGym presents. KnotGym is available at https://github.com/lil-lab/knotgym.
Retrospective Learning from Interactions
Oct 17, 2024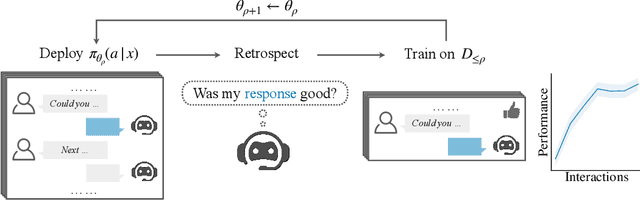


Multi-turn interactions between large language models (LLMs) and users naturally include implicit feedback signals. If an LLM responds in an unexpected way to an instruction, the user is likely to signal it by rephrasing the request, expressing frustration, or pivoting to an alternative task. Such signals are task-independent and occupy a relatively constrained subspace of language, allowing the LLM to identify them even if it fails on the actual task. This creates an avenue for continually learning from interactions without additional annotations. We introduce ReSpect, a method to learn from such signals in past interactions via retrospection. We deploy ReSpect in a new multimodal interaction scenario, where humans instruct an LLM to solve an abstract reasoning task with a combinatorial solution space. Through thousands of interactions with humans, we show how ReSpect gradually improves task completion rate from 31% to 82%, all without any external annotation.
Reward Machines for Deep RL in Noisy and Uncertain Environments
May 31, 2024

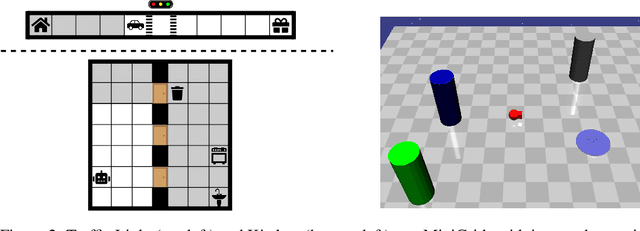

Reward Machines provide an automata-inspired structure for specifying instructions, safety constraints, and other temporally extended reward-worthy behaviour. By exposing complex reward function structure, they enable counterfactual learning updates that have resulted in impressive sample efficiency gains. While Reward Machines have been employed in both tabular and deep RL settings, they have typically relied on a ground-truth interpretation of the domain-specific vocabulary that form the building blocks of the reward function. Such ground-truth interpretations can be elusive in many real-world settings, due in part to partial observability or noisy sensing. In this paper, we explore the use of Reward Machines for Deep RL in noisy and uncertain environments. We characterize this problem as a POMDP and propose a suite of RL algorithms that leverage task structure under uncertain interpretation of domain-specific vocabulary. Theoretical analysis exposes pitfalls in naive approaches to this problem, while experimental results show that our algorithms successfully leverage task structure to improve performance under noisy interpretations of the vocabulary. Our results provide a general framework for exploiting Reward Machines in partially observable environments.
AMFD: Distillation via Adaptive Multimodal Fusion for Multispectral Pedestrian Detection
May 21, 2024
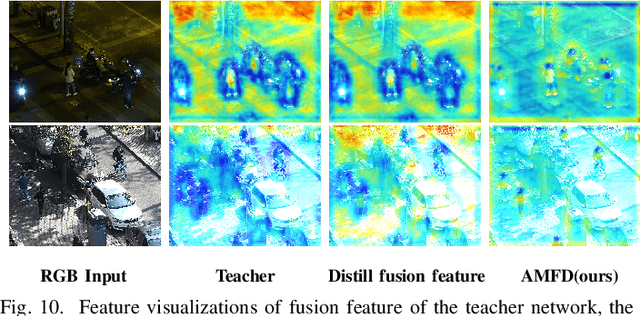


Multispectral pedestrian detection has been shown to be effective in improving performance within complex illumination scenarios. However, prevalent double-stream networks in multispectral detection employ two separate feature extraction branches for multi-modal data, leading to nearly double the inference time compared to single-stream networks utilizing only one feature extraction branch. This increased inference time has hindered the widespread employment of multispectral pedestrian detection in embedded devices for autonomous systems. To address this limitation, various knowledge distillation methods have been proposed. However, traditional distillation methods focus only on the fusion features and ignore the large amount of information in the original multi-modal features, thereby restricting the student network's performance. To tackle the challenge, we introduce the Adaptive Modal Fusion Distillation (AMFD) framework, which can fully utilize the original modal features of the teacher network. Specifically, a Modal Extraction Alignment (MEA) module is utilized to derive learning weights for student networks, integrating focal and global attention mechanisms. This methodology enables the student network to acquire optimal fusion strategies independent from that of teacher network without necessitating an additional feature fusion module. Furthermore, we present the SMOD dataset, a well-aligned challenging multispectral dataset for detection. Extensive experiments on the challenging KAIST, LLVIP and SMOD datasets are conducted to validate the effectiveness of AMFD. The results demonstrate that our method outperforms existing state-of-the-art methods in both reducing log-average Miss Rate and improving mean Average Precision. The code is available at https://github.com/bigD233/AMFD.git.
Noisy Symbolic Abstractions for Deep RL: A case study with Reward Machines
Nov 23, 2022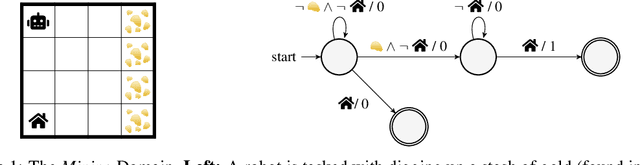
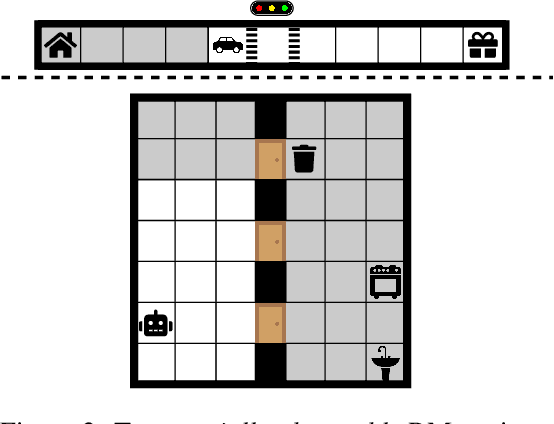
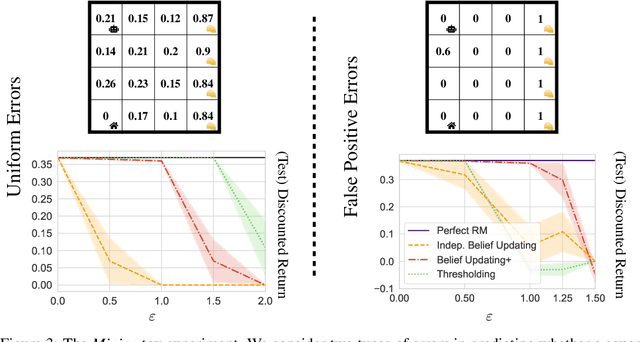
Natural and formal languages provide an effective mechanism for humans to specify instructions and reward functions. We investigate how to generate policies via RL when reward functions are specified in a symbolic language captured by Reward Machines, an increasingly popular automaton-inspired structure. We are interested in the case where the mapping of environment state to a symbolic (here, Reward Machine) vocabulary -- commonly known as the labelling function -- is uncertain from the perspective of the agent. We formulate the problem of policy learning in Reward Machines with noisy symbolic abstractions as a special class of POMDP optimization problem, and investigate several methods to address the problem, building on existing and new techniques, the latter focused on predicting Reward Machine state, rather than on grounding of individual symbols. We analyze these methods and evaluate them experimentally under varying degrees of uncertainty in the correct interpretation of the symbolic vocabulary. We verify the strength of our approach and the limitation of existing methods via an empirical investigation on both illustrative, toy domains and partially observable, deep RL domains.
Classify Respiratory Abnormality in Lung Sounds Using STFT and a Fine-Tuned ResNet18 Network
Aug 30, 2022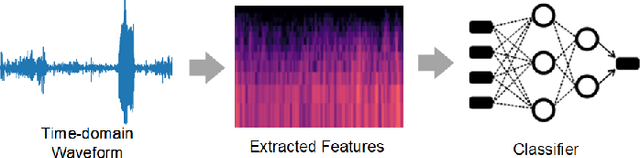
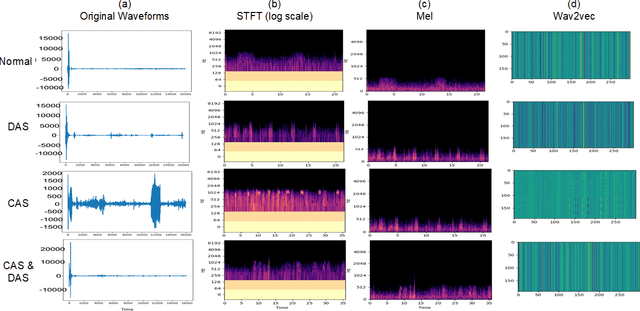
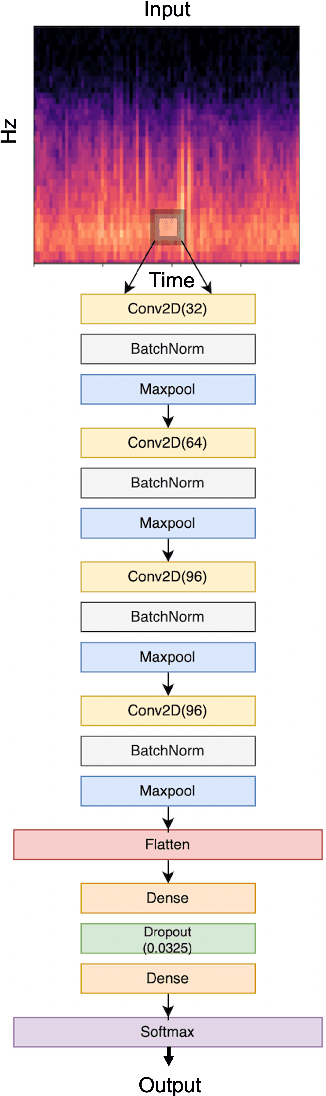
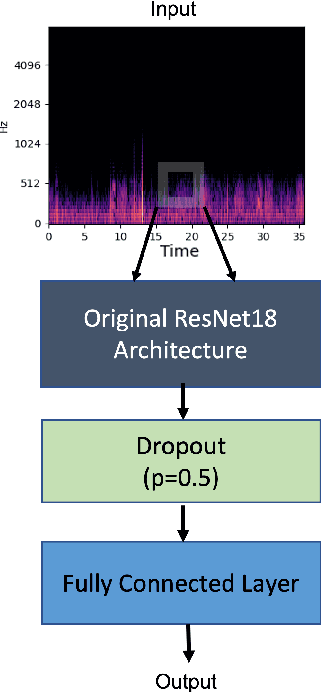
Recognizing patterns in lung sounds is crucial to detecting and monitoring respiratory diseases. Current techniques for analyzing respiratory sounds demand domain experts and are subject to interpretation. Hence an accurate and automatic respiratory sound classification system is desired. In this work, we took a data-driven approach to classify abnormal lung sounds. We compared the performance using three different feature extraction techniques, which are short-time Fourier transformation (STFT), Mel spectrograms, and Wav2vec, as well as three different classifiers, including pre-trained ResNet18, LightCNN, and Audio Spectrogram Transformer. Our key contributions include the bench-marking of different audio feature extractors and neural network based classifiers, and the implementation of a complete pipeline using STFT and a fine-tuned ResNet18 network. The proposed method achieved Harmonic Scores of 0.89, 0.80, 0.71, 0.36 for tasks 1-1, 1-2, 2-1 and 2-2, respectively on the testing sets in the IEEE BioCAS 2022 Grand Challenge on Respiratory Sound Classification.