 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabyLM Turns 4 and Goes Multilingual: Call for Papers for the 2026 BabyLM Workshop
Feb 24, 2026The goal of the BabyLM is to stimulate new research connections between cognitive modeling and language model pretraining. We invite contributions in this vein to the BabyLM Workshop, which will also include the 4th iteration of the BabyLM Challenge. As in previous years, the challenge features two ``standard'' tracks (Strict and Strict-Small), in which participants must train language models on under 100M or 10M words of data, respectively. This year, we move beyond our previous English-only pretraining datasets with a new Multilingual track, focusing on English, Dutch, and Chinese. For the workshop, we call for papers related to the overall theme of BabyLM, which includes training efficiency, small-scale training datasets, cognitive modeling, model evaluation, and architecture innovation.
Updating Parametric Knowledge with Context Distillation Retains Post-Training Capabilities
Feb 17, 2026Post-training endows pretrained LLMs with a variety of desirable skills, including instruction-following, reasoning, and others. However, these post-trained LLMs only encode knowledge up to a cut-off date, necessitating continual adaptation. Unfortunately, existing solutions cannot simultaneously learn new knowledge from an adaptation document corpora and mitigate the forgetting of earlier learned capabilities. To address this, we introduce Distillation via Split Contexts (DiSC), a simple context-distillation based approach for continual knowledge adaptation. \methodname~derives student and teacher distributions by conditioning on distinct segments of the training example and minimizes the KL divergence between the shared tokens. This allows us to efficiently apply context-distillation without requiring explicit generation steps during training. We run experiments on four post-trained models and two adaptation domains. Compared to prior finetuning and distillation methods for continual adaptation, DiSC consistently reports the best trade-off between learning new knowledge and mitigating forgetting of previously learned skills like instruction-following, reasoning, and factual knowledge.
Retrospective Learning from Interactions
Oct 17, 2024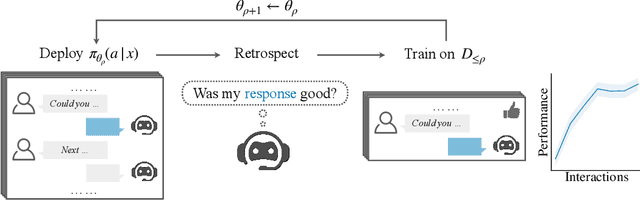


Multi-turn interactions between large language models (LLMs) and users naturally include implicit feedback signals. If an LLM responds in an unexpected way to an instruction, the user is likely to signal it by rephrasing the request, expressing frustration, or pivoting to an alternative task. Such signals are task-independent and occupy a relatively constrained subspace of language, allowing the LLM to identify them even if it fails on the actual task. This creates an avenue for continually learning from interactions without additional annotations. We introduce ReSpect, a method to learn from such signals in past interactions via retrospection. We deploy ReSpect in a new multimodal interaction scenario, where humans instruct an LLM to solve an abstract reasoning task with a combinatorial solution space. Through thousands of interactions with humans, we show how ReSpect gradually improves task completion rate from 31% to 82%, all without any external annotation.
CoGen: Learning from Feedback with Coupled Comprehension and Generation
Aug 28, 2024Systems with both language comprehension and generation capabilities can benefit from the tight connection between the two. This work studies coupling comprehension and generation with focus on continually learning from interaction with users. We propose techniques to tightly integrate the two capabilities for both learning and inference. We situate our studies in two-player reference games, and deploy various models for thousands of interactions with human users, while learning from interaction feedback signals. We show dramatic improvements in performance over time, with comprehension-generation coupling leading to performance improvements up to 26% in absolute terms and up to 17% higher accuracies compared to a non-coupled system. Our analysis also shows coupling has substantial qualitative impact on the system's language, making it significantly more human-like.
CB2: Collaborative Natural Language Interaction Research Platform
Mar 14, 2023



CB2 is a multi-agent platform to study collaborative natural language interaction in a grounded task-oriented scenario. It includes a 3D game environment, a backend server designed to serve trained models to human agents, and various tools and processes to enable scalable studies. We deploy CB2 at https://cb2.ai as a system demonstration with a learned instruction following model.
CREPE: Can Vision-Language Foundation Models Reason Compositionally?
Dec 13, 2022A fundamental characteristic common to both human vision and natural language is their compositional nature. Yet, despite the performance gains contributed by large vision and language pretraining, we find that - across 6 architectures trained with 4 algorithms on massive datasets - they exhibit little compositionality. To arrive at this conclusion, we introduce a new compositionality evaluation benchmark CREPE which measures two important aspects of compositionality identified by cognitive science literature: systematicity and productivity. To measure systematicity, CREPE consists of three test datasets. The three test sets are designed to test models trained on three of the popular training datasets: CC-12M, YFCC-15M, and LAION-400M. They contain 385K, 385K, and 373K image-text pairs and 237K, 210K, and 178K hard negative captions. To test productivity, CREPE contains 17K image-text pairs with nine different complexities plus 246K hard negative captions with atomic, swapping, and negation foils. The datasets are generated by repurposing the Visual Genome scene graphs and region descriptions and applying handcrafted templates and GPT-3. For systematicity, we find that model performance decreases consistently when novel compositions dominate the retrieval set, with Recall@1 dropping by up to 8%. For productivity, models' retrieval success decays as complexity increases, frequently nearing random chance at high complexity. These results hold regardless of model and training dataset size.
Measuring Compositional Consistency for Video Question Answering
Apr 14, 2022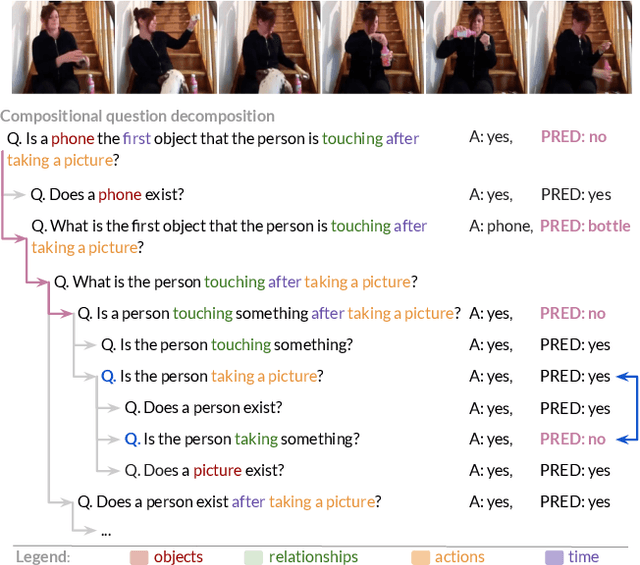
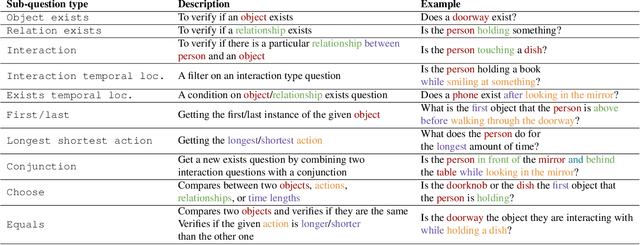
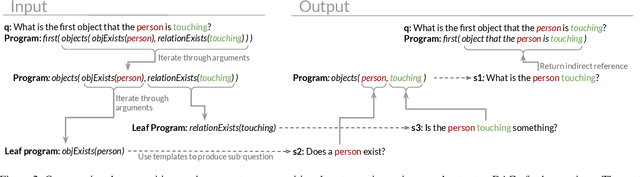
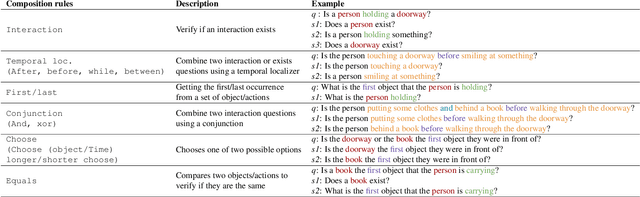
Recent video question answering benchmarks indicate that state-of-the-art models struggle to answer compositional questions. However, it remains unclear which types of compositional reasoning cause models to mispredict. Furthermore, it is difficult to discern whether models arrive at answers using compositional reasoning or by leveraging data biases. In this paper, we develop a question decomposition engine that programmatically deconstructs a compositional question into a directed acyclic graph of sub-questions. The graph is designed such that each parent question is a composition of its children. We present AGQA-Decomp, a benchmark containing $2.3M$ question graphs, with an average of $11.49$ sub-questions per graph, and $4.55M$ total new sub-questions. Using question graphs, we evaluate three state-of-the-art models with a suite of novel compositional consistency metrics. We find that models either cannot reason correctly through most compositions or are reliant on incorrect reasoning to reach answers, frequently contradicting themselves or achieving high accuracies when failing at intermediate reasoning steps.
* To appear in CVPR 2022. 23 pages, 12 figures and 12 tables