 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBongards at the Boundary of Perception and Reasoning: Programs or Language?
Feb 03, 2026Vision-Language Models (VLMs) have made great strides in everyday visual tasks, such as captioning a natural image, or answering commonsense questions about such images. But humans possess the puzzling ability to deploy their visual reasoning abilities in radically new situations, a skill rigorously tested by the classic set of visual reasoning challenges known as the Bongard problems. We present a neurosymbolic approach to solving these problems: given a hypothesized solution rule for a Bongard problem, we leverage LLMs to generate parameterized programmatic representations for the rule and perform parameter fitting using Bayesian optimization. We evaluate our method on classifying Bongard problem images given the ground truth rule, as well as on solving the problems from scratch.
OmniCode: A Benchmark for Evaluating Software Engineering Agents
Feb 02, 2026LLM-powered coding agents are redefining how real-world software is developed. To drive the research towards better coding agents, we require challenging benchmarks that can rigorously evaluate the ability of such agents to perform various software engineering tasks. However, popular coding benchmarks such as HumanEval and SWE-Bench focus on narrowly scoped tasks such as competition programming and patch generation. In reality, software engineers have to handle a broader set of tasks for real-world software development. To address this gap, we propose OmniCode, a novel software engineering benchmark that contains a broader and more diverse set of task categories beyond code or patch generation. Overall, OmniCode contains 1794 tasks spanning three programming languages (Python, Java, and C++) and four key categories: bug fixing, test generation, code review fixing, and style fixing. In contrast to prior software engineering benchmarks, the tasks in OmniCode are (1) manually validated to eliminate ill-defined problems, and (2) synthetically crafted or recently curated to avoid data leakage issues, presenting a new framework for synthetically generating diverse software tasks from limited real-world data. We evaluate OmniCode with popular agent frameworks such as SWE-Agent and show that while they may perform well on bug fixing for Python, they fall short on tasks such as Test Generation and in languages such as C++ and Java. For instance, SWE-Agent achieves a maximum of 20.9% with DeepSeek-V3.1 on Java Test Generation tasks. OmniCode aims to serve as a robust benchmark and spur the development of agents that can perform well across different aspects of software development. Code and data are available at https://github.com/seal-research/OmniCode.
MedAgentBench: Dataset for Benchmarking LLMs as Agents in Medical Applications
Jan 24, 2025Recent large language models (LLMs) have demonstrated significant advancements, particularly in their ability to serve as agents thereby surpassing their traditional role as chatbots. These agents can leverage their planning and tool utilization capabilities to address tasks specified at a high level. However, a standardized dataset to benchmark the agent capabilities of LLMs in medical applications is currently lacking, making the evaluation of LLMs on complex tasks in interactive healthcare environments challenging. To address this gap, we introduce MedAgentBench, a broad evaluation suite designed to assess the agent capabilities of large language models within medical records contexts. MedAgentBench encompasses 100 patient-specific clinically-derived tasks from 10 categories written by human physicians, realistic profiles of 100 patients with over 700,000 data elements, a FHIR-compliant interactive environment, and an accompanying codebase. The environment uses the standard APIs and communication infrastructure used in modern EMR systems, so it can be easily migrated into live EMR systems. MedAgentBench presents an unsaturated agent-oriented benchmark that current state-of-the-art LLMs exhibit some ability to succeed at. The best model (GPT-4o) achieves a success rate of 72%. However, there is still substantial space for improvement to give the community a next direction to optimize. Furthermore, there is significant variation in performance across task categories. MedAgentBench establishes this and is publicly available at https://github.com/stanfordmlgroup/MedAgentBench , offering a valuable framework for model developers to track progress and drive continuous improvements in the agent capabilities of large language models within the medical domain.
Retrospective Learning from Interactions
Oct 17, 2024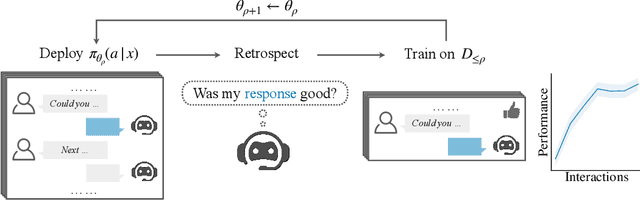
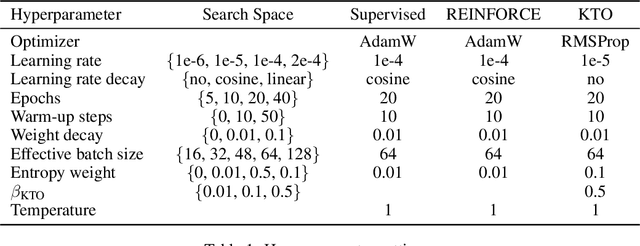


Multi-turn interactions between large language models (LLMs) and users naturally include implicit feedback signals. If an LLM responds in an unexpected way to an instruction, the user is likely to signal it by rephrasing the request, expressing frustration, or pivoting to an alternative task. Such signals are task-independent and occupy a relatively constrained subspace of language, allowing the LLM to identify them even if it fails on the actual task. This creates an avenue for continually learning from interactions without additional annotations. We introduce ReSpect, a method to learn from such signals in past interactions via retrospection. We deploy ReSpect in a new multimodal interaction scenario, where humans instruct an LLM to solve an abstract reasoning task with a combinatorial solution space. Through thousands of interactions with humans, we show how ReSpect gradually improves task completion rate from 31% to 82%, all without any external annotation.