 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORCA: Object Recognition and Comprehension for Archiving Marine Species
Dec 24, 2025Marine visual understanding is essential for monitoring and protecting marine ecosystems, enabling automatic and scalable biological surveys. However, progress is hindered by limited training data and the lack of a systematic task formulation that aligns domain-specific marine challenges with well-defined computer vision tasks, thereby limiting effective model application. To address this gap, we present ORCA, a multi-modal benchmark for marine research comprising 14,647 images from 478 species, with 42,217 bounding box annotations and 22,321 expert-verified instance captions. The dataset provides fine-grained visual and textual annotations that capture morphology-oriented attributes across diverse marine species. To catalyze methodological advances, we evaluate 18 state-of-the-art models on three tasks: object detection (closed-set and open-vocabulary), instance captioning, and visual grounding. Results highlight key challenges, including species diversity, morphological overlap, and specialized domain demands, underscoring the difficulty of marine understanding. ORCA thus establishes a comprehensive benchmark to advance research in marine domain. Project Page: http://orca.hkustvgd.com/.
Leak@$k$: Unlearning Does Not Make LLMs Forget Under Probabilistic Decoding
Nov 07, 2025Unlearning in large language models (LLMs) is critical for regulatory compliance and for building ethical generative AI systems that avoid producing private, toxic, illegal, or copyrighted content. Despite rapid progress, in this work we show that \textit{almost all} existing unlearning methods fail to achieve true forgetting in practice. Specifically, while evaluations of these `unlearned' models under deterministic (greedy) decoding often suggest successful knowledge removal using standard benchmarks (as has been done in the literature), we show that sensitive information reliably resurfaces when models are sampled with standard probabilistic decoding. To rigorously capture this vulnerability, we introduce \texttt{leak@$k$}, a new meta-evaluation metric that quantifies the likelihood of forgotten knowledge reappearing when generating $k$ samples from the model under realistic decoding strategies. Using three widely adopted benchmarks, TOFU, MUSE, and WMDP, we conduct the first large-scale, systematic study of unlearning reliability using our newly defined \texttt{leak@$k$} metric. Our findings demonstrate that knowledge leakage persists across methods and tasks, underscoring that current state-of-the-art unlearning techniques provide only limited forgetting and highlighting the urgent need for more robust approaches to LLM unlearning.
QiNN-QJ: A Quantum-inspired Neural Network with Quantum Jump for Multimodal Sentiment Analysis
Oct 31, 2025Quantum theory provides non-classical principles, such as superposition and entanglement, that inspires promising paradigms in machine learning. However, most existing quantum-inspired fusion models rely solely on unitary or unitary-like transformations to generate quantum entanglement. While theoretically expressive, such approaches often suffer from training instability and limited generalizability. In this work, we propose a Quantum-inspired Neural Network with Quantum Jump (QiNN-QJ) for multimodal entanglement modelling. Each modality is firstly encoded as a quantum pure state, after which a differentiable module simulating the QJ operator transforms the separable product state into the entangled representation. By jointly learning Hamiltonian and Lindblad operators, QiNN-QJ generates controllable cross-modal entanglement among modalities with dissipative dynamics, where structured stochasticity and steady-state attractor properties serve to stabilize training and constrain entanglement shaping. The resulting entangled states are projected onto trainable measurement vectors to produce predictions. In addition to achieving superior performance over the state-of-the-art models on benchmark datasets, including CMU-MOSI, CMU-MOSEI, and CH-SIMS, QiNN-QJ facilitates enhanced post-hoc interpretability through von-Neumann entanglement entropy. This work establishes a principled framework for entangled multimodal fusion and paves the way for quantum-inspired approaches in modelling complex cross-modal correlations.
Less Is More: Training-Free Sparse Attention with Global Locality for Efficient Reasoning
Aug 09, 2025Large reasoning models achieve strong performance through test-time scaling but incur substantial computational overhead, particularly from excessive token generation when processing short input prompts. While sparse attention mechanisms can reduce latency and memory usage, existing approaches suffer from significant accuracy degradation due to accumulated errors during long-generation reasoning. These methods generally require either high token retention rates or expensive retraining. We introduce LessIsMore, a training-free sparse attention mechanism for reasoning tasks, which leverages global attention patterns rather than relying on traditional head-specific local optimizations. LessIsMore aggregates token selections from local attention heads with recent contextual information, enabling unified cross-head token ranking for future decoding layers. This unified selection improves generalization and efficiency by avoiding the need to maintain separate token subsets per head. Evaluation across diverse reasoning tasks and benchmarks shows that LessIsMore preserves -- and in some cases improves -- accuracy while achieving a $1.1\times$ average decoding speed-up compared to full attention. Moreover, LessIsMore attends to $2\times$ fewer tokens without accuracy loss, achieving a $1.13\times$ end-to-end speed-up compared to existing sparse attention methods.
MoSE: Skill-by-Skill Mixture-of-Expert Learning for Autonomous Driving
Jul 10, 2025
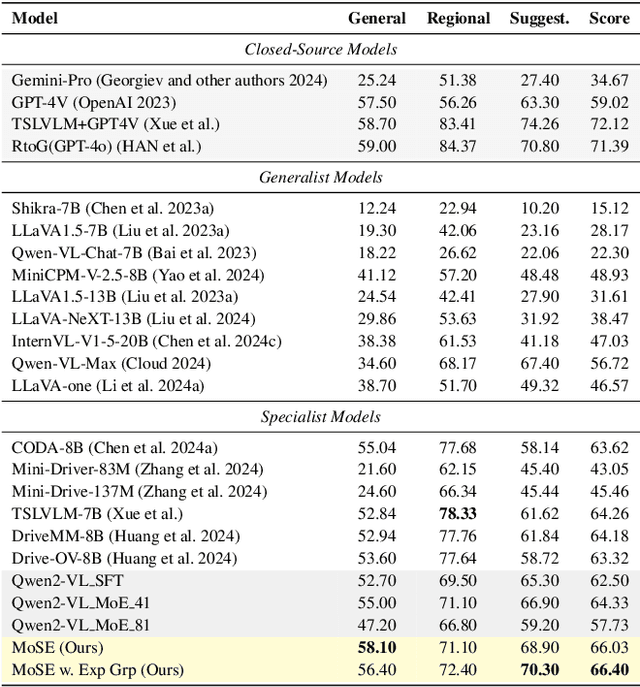
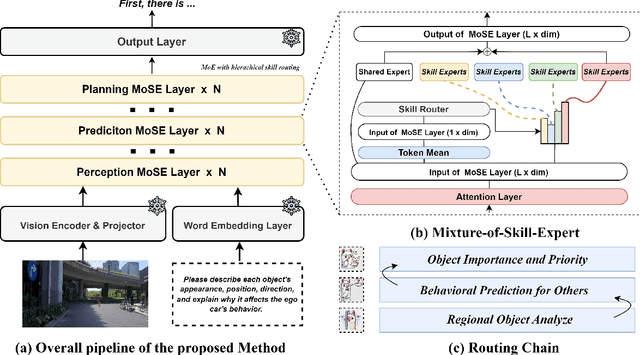
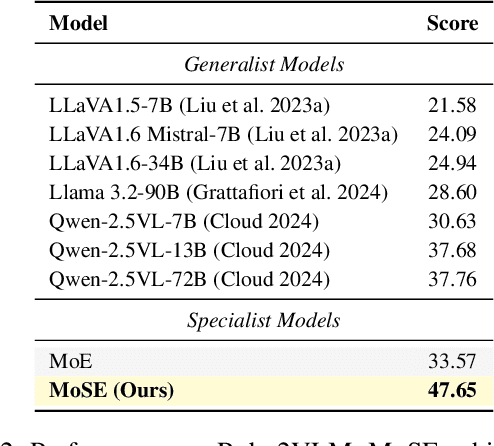
Recent studies show large language models (LLMs) and vision language models (VLMs) trained using web-scale data can empower end-to-end autonomous driving systems for a better generalization and interpretation. Specifically, by dynamically routing inputs to specialized subsets of parameters, the Mixture-of-Experts (MoE) technique enables general LLMs or VLMs to achieve substantial performance improvements while maintaining computational efficiency. However, general MoE models usually demands extensive training data and complex optimization. In this work, inspired by the learning process of human drivers, we propose a skill-oriented MoE, called MoSE, which mimics human drivers' learning process and reasoning process, skill-by-skill and step-by-step. We propose a skill-oriented routing mechanism that begins with defining and annotating specific skills, enabling experts to identify the necessary driving competencies for various scenarios and reasoning tasks, thereby facilitating skill-by-skill learning. Further align the driving process to multi-step planning in human reasoning and end-to-end driving models, we build a hierarchical skill dataset and pretrain the router to encourage the model to think step-by-step. Unlike multi-round dialogs, MoSE integrates valuable auxiliary tasks (e.g.\ description, reasoning, planning) in one single forward process without introducing any extra computational cost. With less than 3B sparsely activated parameters, our model outperforms several 8B+ parameters on CODA AD corner case reasoning task. Compared to existing methods based on open-source models and data, our approach achieves state-of-the-art performance with significantly reduced activated model size (at least by $62.5\%$) with a single-turn conversation.
Safety Mirage: How Spurious Correlations Undermine VLM Safety Fine-tuning
Mar 14, 2025Recent vision-language models (VLMs) have made remarkable strides in generative modeling with multimodal inputs, particularly text and images. However, their susceptibility to generating harmful content when exposed to unsafe queries raises critical safety concerns. While current alignment strategies primarily rely on supervised safety fine-tuning with curated datasets, we identify a fundamental limitation we call the "safety mirage" where supervised fine-tuning inadvertently reinforces spurious correlations between superficial textual patterns and safety responses, rather than fostering deep, intrinsic mitigation of harm. We show that these spurious correlations leave fine-tuned VLMs vulnerable even to a simple one-word modification-based attack, where substituting a single word in text queries with a spurious correlation-inducing alternative can effectively bypass safeguards. Additionally, these correlations contribute to the over prudence, causing fine-tuned VLMs to refuse benign queries unnecessarily. To address this issue, we show machine unlearning (MU) as a powerful alternative to supervised safety fine-tuning as it avoids biased feature-label mappings and directly removes harmful knowledge from VLMs while preserving their general capabilities. Extensive evaluations across safety benchmarks show that under one-word attacks, MU-based alignment reduces the attack success rate by up to 60.17% and cuts unnecessary rejections by over 84.20%. Codes are available at https://github.com/OPTML-Group/VLM-Safety-MU. WARNING: There exist AI generations that may be offensive in nature.
The R2D2 Deep Neural Network Series for Scalable Non-Cartesian Magnetic Resonance Imaging
Mar 13, 2025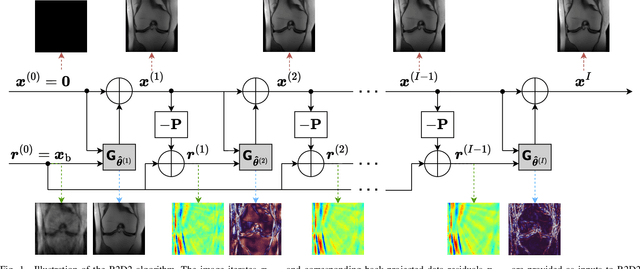
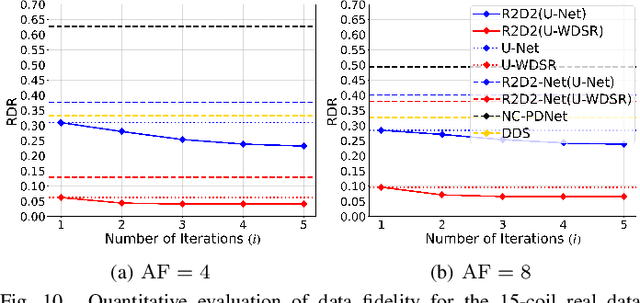
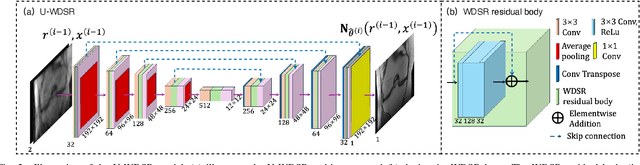
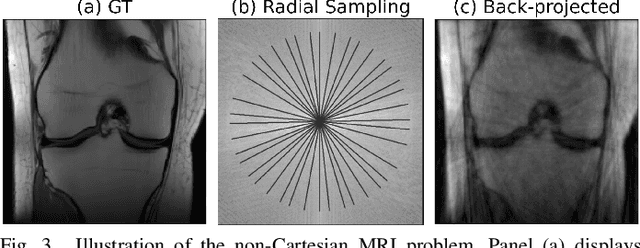
We introduce the R2D2 Deep Neural Network (DNN) series paradigm for fast and scalable image reconstruction from highly-accelerated non-Cartesian k-space acquisitions in Magnetic Resonance Imaging (MRI). While unrolled DNN architectures provide a robust image formation approach via data-consistency layers, embedding non-uniform fast Fourier transform operators in a DNN can become impractical to train at large scale, e.g in 2D MRI with a large number of coils, or for higher-dimensional imaging. Plug-and-play approaches that alternate a learned denoiser blind to the measurement setting with a data-consistency step are not affected by this limitation but their highly iterative nature implies slow reconstruction. To address this scalability challenge, we leverage the R2D2 paradigm that was recently introduced to enable ultra-fast reconstruction for large-scale Fourier imaging in radio astronomy. R2D2's reconstruction is formed as a series of residual images iteratively estimated as outputs of DNN modules taking the previous iteration's data residual as input. The method can be interpreted as a learned version of the Matching Pursuit algorithm. A series of R2D2 DNN modules were sequentially trained in a supervised manner on the fastMRI dataset and validated for 2D multi-coil MRI in simulation and on real data, targeting highly under-sampled radial k-space sampling. Results suggest that a series with only few DNNs achieves superior reconstruction quality over its unrolled incarnation R2D2-Net (whose training is also much less scalable), and over the state-of-the-art diffusion-based "Decomposed Diffusion Sampler" approach (also characterised by a slower reconstruction process).
Retrospective Learning from Interactions
Oct 17, 2024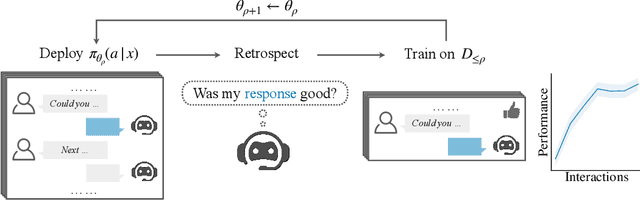


Multi-turn interactions between large language models (LLMs) and users naturally include implicit feedback signals. If an LLM responds in an unexpected way to an instruction, the user is likely to signal it by rephrasing the request, expressing frustration, or pivoting to an alternative task. Such signals are task-independent and occupy a relatively constrained subspace of language, allowing the LLM to identify them even if it fails on the actual task. This creates an avenue for continually learning from interactions without additional annotations. We introduce ReSpect, a method to learn from such signals in past interactions via retrospection. We deploy ReSpect in a new multimodal interaction scenario, where humans instruct an LLM to solve an abstract reasoning task with a combinatorial solution space. Through thousands of interactions with humans, we show how ReSpect gradually improves task completion rate from 31% to 82%, all without any external annotation.
Diffusion Guided Language Modeling
Aug 08, 2024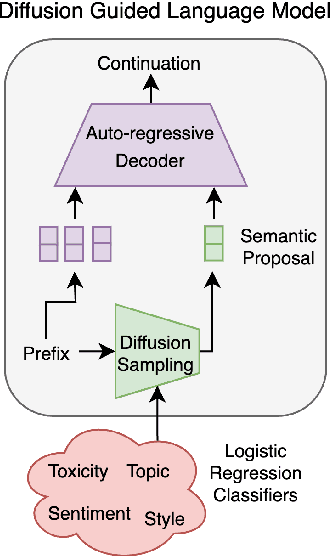



Current language models demonstrate remarkable proficiency in text generation. However, for many applications it is desirable to control attributes, such as sentiment, or toxicity, of the generated language -- ideally tailored towards each specific use case and target audience. For auto-regressive language models, existing guidance methods are prone to decoding errors that cascade during generation and degrade performance. In contrast, text diffusion models can easily be guided with, for example, a simple linear sentiment classifier -- however they do suffer from significantly higher perplexity than auto-regressive alternatives. In this paper we use a guided diffusion model to produce a latent proposal that steers an auto-regressive language model to generate text with desired properties. Our model inherits the unmatched fluency of the auto-regressive approach and the plug-and-play flexibility of diffusion. We show that it outperforms previous plug-and-play guidance methods across a wide range of benchmark data sets. Further, controlling a new attribute in our framework is reduced to training a single logistic regression classifier.
Scalable Non-Cartesian Magnetic Resonance Imaging with R2D2
Mar 27, 2024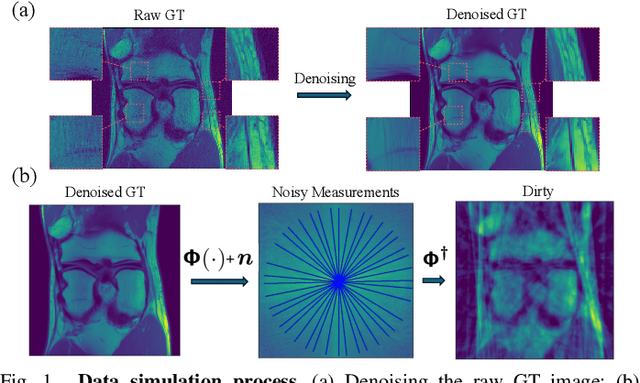
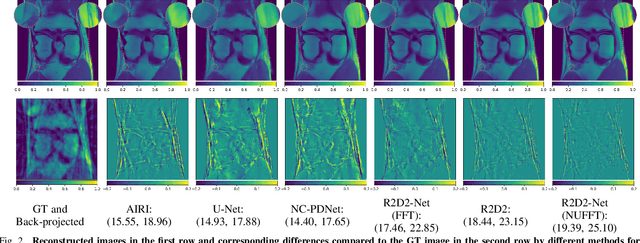
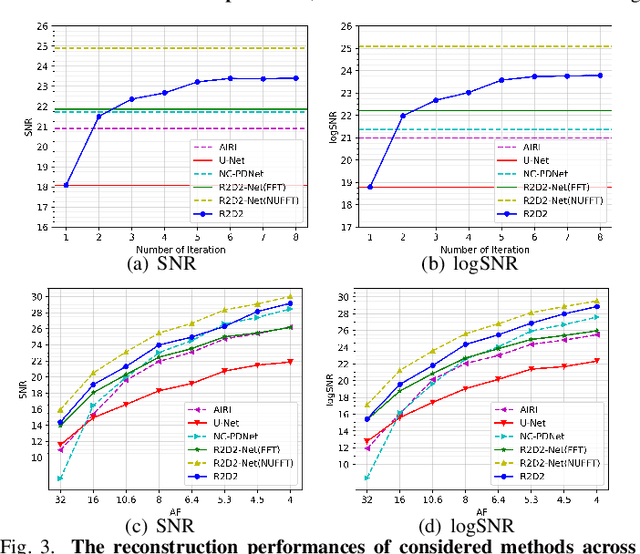
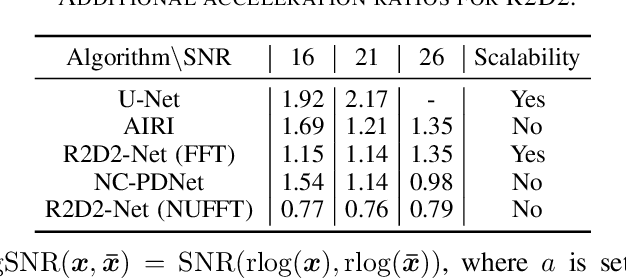
We propose a new approach for non-Cartesian magnetic resonance image reconstruction. While unrolled architectures provide robustness via data-consistency layers, embedding measurement operators in Deep Neural Network (DNN) can become impractical at large scale. Alternative Plug-and-Play (PnP) approaches, where the denoising DNNs are blind to the measurement setting, are not affected by this limitation and have also proven effective, but their highly iterative nature also affects scalability. To address this scalability challenge, we leverage the "Residual-to-Residual DNN series for high-Dynamic range imaging (R2D2)" approach recently introduced in astronomical imaging. R2D2's reconstruction is formed as a series of residual images, iteratively estimated as outputs of DNNs taking the previous iteration's image estimate and associated data residual as inputs. The method can be interpreted as a learned version of the Matching Pursuit algorithm. We demonstrate R2D2 in simulation, considering radial k-space sampling acquisition sequences. Our preliminary results suggest that R2D2 achieves: (i) suboptimal performance compared to its unrolled incarnation R2D2-Net, which is however non-scalable due to the necessary embedding of NUFFT-based data-consistency layers; (ii) superior reconstruction quality to a scalable version of R2D2-Net embedding an FFT-based approximation for data consistency; (iii) superior reconstruction quality to PnP, while only requiring few iterations.