 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECGomics: An Open Platform for AI-ECG Digital Biomarker Discovery
Jan 19, 2026Background: Conventional electrocardiogram (ECG) analysis faces a persistent dichotomy: expert-driven features ensure interpretability but lack sensitivity to latent patterns, while deep learning offers high accuracy but functions as a black box with high data dependency. We introduce ECGomics, a systematic paradigm and open-source platform for the multidimensional deconstruction of cardiac signals into digital biomarker. Methods: Inspired by the taxonomic rigor of genomics, ECGomics deconstructs cardiac activity across four dimensions: Structural, Intensity, Functional, and Comparative. This taxonomy synergizes expert-defined morphological rules with data-driven latent representations, effectively bridging the gap between handcrafted features and deep learning embeddings. Results: We operationalized this framework into a scalable ecosystem consisting of a web-based research platform and a mobile-integrated solution (https://github.com/PKUDigitalHealth/ECGomics). The web platform facilitates high-throughput analysis via precision parameter configuration, high-fidelity data ingestion, and 12-lead visualization, allowing for the systematic extraction of biomarkers across the four ECGomics dimensions. Complementarily, the mobile interface, integrated with portable sensors and a cloud-based engine, enables real-time signal acquisition and near-instantaneous delivery of structured diagnostic reports. This dual-interface architecture successfully transitions ECGomics from theoretical discovery to decentralized, real-world health management, ensuring professional-grade monitoring in diverse clinical and home-based settings. Conclusion: ECGomics harmonizes diagnostic precision, interpretability, and data efficiency. By providing a deployable software ecosystem, this paradigm establishes a robust foundation for digital biomarker discovery and personalized cardiovascular medicine.
Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Jun 26, 2025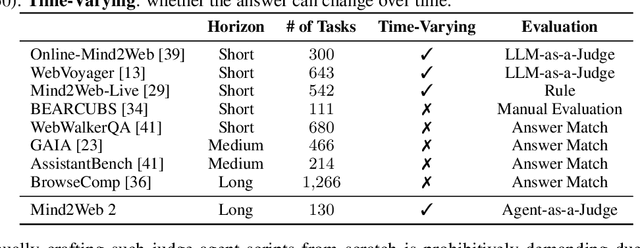
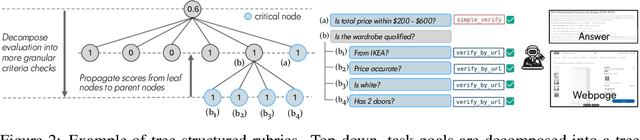

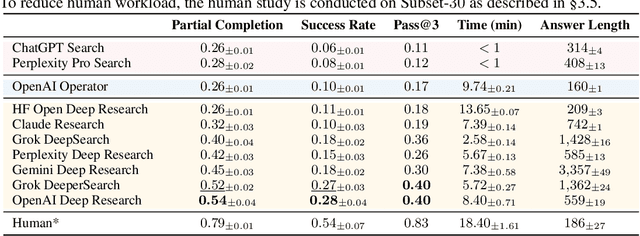
Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
AutoSDT: Scaling Data-Driven Discovery Tasks Toward Open Co-Scientists
Jun 09, 2025



Despite long-standing efforts in accelerating scientific discovery with AI, building AI co-scientists remains challenging due to limited high-quality data for training and evaluation. To tackle this data scarcity issue, we present AutoSDT, an automatic pipeline that collects high-quality coding tasks in real-world data-driven discovery workflows. AutoSDT leverages the coding capabilities and parametric knowledge of LLMs to search for diverse sources, select ecologically valid tasks, and synthesize accurate task instructions and code solutions. Using our pipeline, we construct AutoSDT-5K, a dataset of 5,404 coding tasks for data-driven discovery that covers four scientific disciplines and 756 unique Python packages. To the best of our knowledge, AutoSDT-5K is the only automatically collected and the largest open dataset for data-driven scientific discovery. Expert feedback on a subset of 256 tasks shows the effectiveness of AutoSDT: 93% of the collected tasks are ecologically valid, and 92.2% of the synthesized programs are functionally correct. Trained on AutoSDT-5K, the Qwen2.5-Coder-Instruct LLM series, dubbed AutoSDT-Coder, show substantial improvement on two challenging data-driven discovery benchmarks, ScienceAgentBench and DiscoveryBench. Most notably, AutoSDT-Coder-32B reaches the same level of performance as GPT-4o on ScienceAgentBench with a success rate of 7.8%, doubling the performance of its base model. On DiscoveryBench, it lifts the hypothesis matching score to 8.1, bringing a 17.4% relative improvement and closing the gap between open-weight models and GPT-4o.
Completing A Systematic Review in Hours instead of Months with Interactive AI Agents
Apr 21, 2025Systematic reviews (SRs) are vital for evidence-based practice in high stakes disciplines, such as healthcare, but are often impeded by intensive labors and lengthy processes that can take months to complete. Due to the high demand for domain expertise, existing automatic summarization methods fail to accurately identify relevant studies and generate high-quality summaries. To that end, we introduce InsightAgent, a human-centered interactive AI agent powered by large language models that revolutionize this workflow. InsightAgent partitions a large literature corpus based on semantics and employs a multi-agent design for more focused processing of literature, leading to significant improvement in the quality of generated SRs. InsightAgent also provides intuitive visualizations of the corpus and agent trajectories, allowing users to effortlessly monitor the actions of the agent and provide real-time feedback based on their expertise. Our user studies with 9 medical professionals demonstrate that the visualization and interaction mechanisms can effectively improve the quality of synthesized SRs by 27.2%, reaching 79.7% of human-written quality. At the same time, user satisfaction is improved by 34.4%. With InsightAgent, it only takes a clinician about 1.5 hours, rather than months, to complete a high-quality systematic review.
The R2D2 Deep Neural Network Series for Scalable Non-Cartesian Magnetic Resonance Imaging
Mar 13, 2025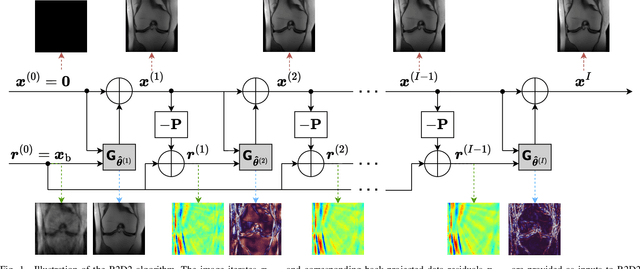
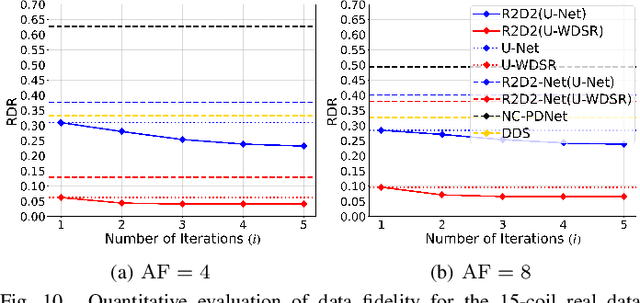
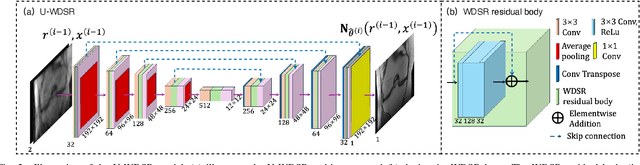
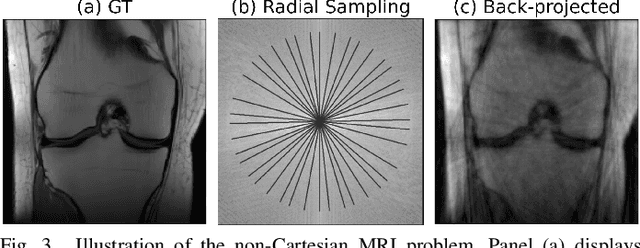
We introduce the R2D2 Deep Neural Network (DNN) series paradigm for fast and scalable image reconstruction from highly-accelerated non-Cartesian k-space acquisitions in Magnetic Resonance Imaging (MRI). While unrolled DNN architectures provide a robust image formation approach via data-consistency layers, embedding non-uniform fast Fourier transform operators in a DNN can become impractical to train at large scale, e.g in 2D MRI with a large number of coils, or for higher-dimensional imaging. Plug-and-play approaches that alternate a learned denoiser blind to the measurement setting with a data-consistency step are not affected by this limitation but their highly iterative nature implies slow reconstruction. To address this scalability challenge, we leverage the R2D2 paradigm that was recently introduced to enable ultra-fast reconstruction for large-scale Fourier imaging in radio astronomy. R2D2's reconstruction is formed as a series of residual images iteratively estimated as outputs of DNN modules taking the previous iteration's data residual as input. The method can be interpreted as a learned version of the Matching Pursuit algorithm. A series of R2D2 DNN modules were sequentially trained in a supervised manner on the fastMRI dataset and validated for 2D multi-coil MRI in simulation and on real data, targeting highly under-sampled radial k-space sampling. Results suggest that a series with only few DNNs achieves superior reconstruction quality over its unrolled incarnation R2D2-Net (whose training is also much less scalable), and over the state-of-the-art diffusion-based "Decomposed Diffusion Sampler" approach (also characterised by a slower reconstruction process).
ScienceAgentBench: Toward Rigorous Assessment of Language Agents for Data-Driven Scientific Discovery
Oct 07, 2024



The advancements of language language models (LLMs) have piqued growing interest in developing LLM-based language agents to automate scientific discovery end-to-end, which has sparked both excitement and skepticism about the true capabilities of such agents. In this work, we argue that for an agent to fully automate scientific discovery, it must be able to complete all essential tasks in the workflow. Thus, we call for rigorous assessment of agents on individual tasks in a scientific workflow before making bold claims on end-to-end automation. To this end, we present ScienceAgentBench, a new benchmark for evaluating language agents for data-driven scientific discovery. To ensure the scientific authenticity and real-world relevance of our benchmark, we extract 102 tasks from 44 peer-reviewed publications in four disciplines and engage nine subject matter experts to validate them. We unify the target output for every task to a self-contained Python program file and employ an array of evaluation metrics to examine the generated programs, execution results, and costs. Each task goes through multiple rounds of manual validation by annotators and subject matter experts to ensure its annotation quality and scientific plausibility. We also propose two effective strategies to mitigate data contamination concerns. Using our benchmark, we evaluate five open-weight and proprietary LLMs, each with three frameworks: direct prompting, OpenHands, and self-debug. Given three attempts for each task, the best-performing agent can only solve 32.4% of the tasks independently and 34.3% with expert-provided knowledge. These results underscore the limited capacities of current language agents in generating code for data-driven discovery, let alone end-to-end automation for scientific research.
Attention in Large Language Models Yields Efficient Zero-Shot Re-Rankers
Oct 03, 2024



Information retrieval (IR) systems have played a vital role in modern digital life and have cemented their continued usefulness in this new era of generative AI via retrieval-augmented generation. With strong language processing capabilities and remarkable versatility, large language models (LLMs) have become popular choices for zero-shot re-ranking in IR systems. So far, LLM-based re-ranking methods rely on strong generative capabilities, which restricts their use to either specialized or powerful proprietary models. Given these restrictions, we ask: is autoregressive generation necessary and optimal for LLMs to perform re-ranking? We hypothesize that there are abundant signals relevant to re-ranking within LLMs that might not be used to their full potential via generation. To more directly leverage such signals, we propose in-context re-ranking (ICR), a novel method that leverages the change in attention pattern caused by the search query for accurate and efficient re-ranking. To mitigate the intrinsic biases in LLMs, we propose a calibration method using a content-free query. Due to the absence of generation, ICR only requires two ($O(1)$) forward passes to re-rank $N$ documents, making it substantially more efficient than generative re-ranking methods that require at least $O(N)$ forward passes. Our novel design also enables ICR to be applied to any LLM without specialized training while guaranteeing a well-formed ranking. Extensive experiments with two popular open-weight LLMs on standard single-hop and multi-hop information retrieval benchmarks show that ICR outperforms RankGPT while cutting the latency by more than 60% in practice. Through detailed analyses, we show that ICR's performance is specially strong on tasks that require more complex re-ranking signals. Our findings call for further exploration on novel ways of utilizing open-weight LLMs beyond text generation.
Roll Up Your Sleeves: Working with a Collaborative and Engaging Task-Oriented Dialogue System
Jul 29, 2023We introduce TacoBot, a user-centered task-oriented digital assistant designed to guide users through complex real-world tasks with multiple steps. Covering a wide range of cooking and how-to tasks, we aim to deliver a collaborative and engaging dialogue experience. Equipped with language understanding, dialogue management, and response generation components supported by a robust search engine, TacoBot ensures efficient task assistance. To enhance the dialogue experience, we explore a series of data augmentation strategies using LLMs to train advanced neural models continuously. TacoBot builds upon our successful participation in the inaugural Alexa Prize TaskBot Challenge, where our team secured third place among ten competing teams. We offer TacoBot as an open-source framework that serves as a practical example for deploying task-oriented dialogue systems.
Mind2Web: Towards a Generalist Agent for the Web
Jun 15, 2023



We introduce Mind2Web, the first dataset for developing and evaluating generalist agents for the web that can follow language instructions to complete complex tasks on any website. Existing datasets for web agents either use simulated websites or only cover a limited set of websites and tasks, thus not suitable for generalist web agents. With over 2,000 open-ended tasks collected from 137 websites spanning 31 domains and crowdsourced action sequences for the tasks, Mind2Web provides three necessary ingredients for building generalist web agents: 1) diverse domains, websites, and tasks, 2) use of real-world websites instead of simulated and simplified ones, and 3) a broad spectrum of user interaction patterns. Based on Mind2Web, we conduct an initial exploration of using large language models (LLMs) for building generalist web agents. While the raw HTML of real-world websites are often too large to be fed to LLMs, we show that first filtering it with a small LM significantly improves the effectiveness and efficiency of LLMs. Our solution demonstrates a decent level of performance, even on websites or entire domains the model has never seen before, but there is still a substantial room to improve towards truly generalizable agents. We open-source our dataset, model implementation, and trained models (https://osu-nlp-group.github.io/Mind2Web) to facilitate further research on building a generalist agent for the web.
Error Detection for Text-to-SQL Semantic Parsing
May 23, 2023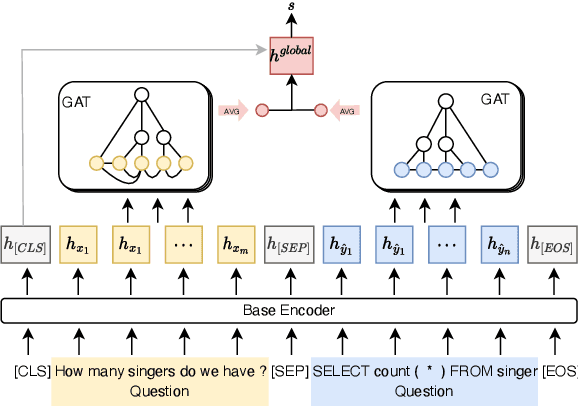

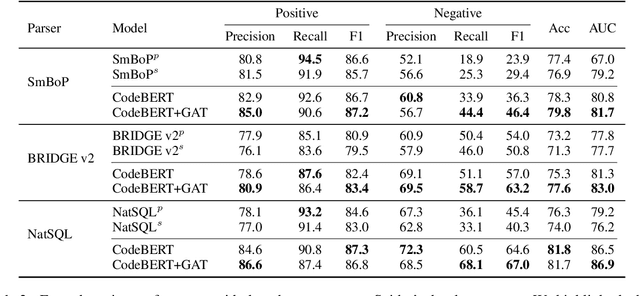
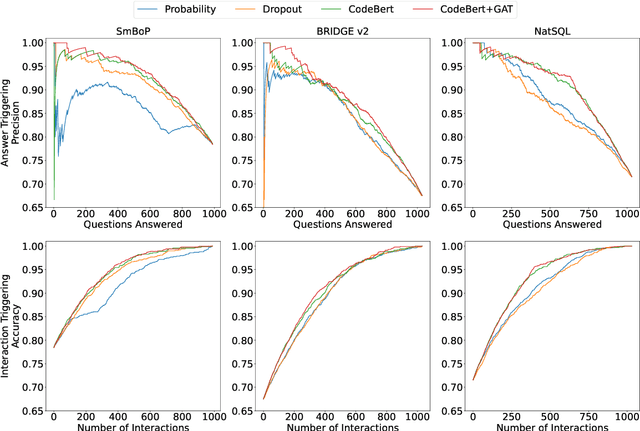
Despite remarkable progress in text-to-SQL semantic parsing in recent years, the performance of existing parsers is still far from perfect. At the same time, modern deep learning based text-to-SQL parsers are often over-confident and thus casting doubt on their trustworthiness when deployed for real use. To that end, we propose to build a parser-independent error detection model for text-to-SQL semantic parsing. The proposed model is based on pre-trained language model of code and is enhanced with structural features learned by graph neural networks. We train our model on realistic parsing errors collected from a cross-domain setting. Experiments with three strong text-to-SQL parsers featuring different decoding mechanisms show that our approach outperforms parser-dependent uncertainty metrics and could effectively improve the performance and usability of text-to-SQL semantic parsers regardless of their architectures.