 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnical report on Conversational Question Answering
Sep 24, 2019
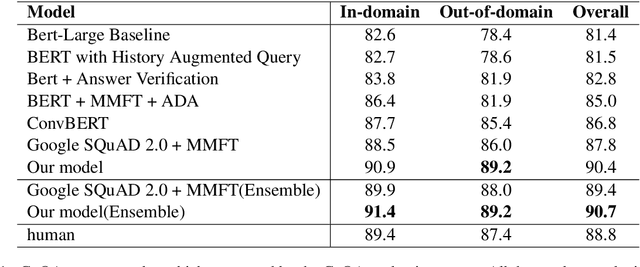
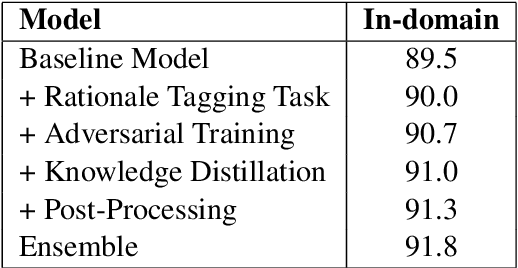
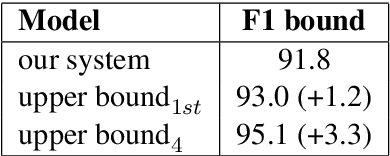
Conversational Question Answering is a challenging task since it requires understanding of conversational history. In this project, we propose a new system RoBERTa + AT +KD, which involves rationale tagging multi-task, adversarial training, knowledge distillation and a linguistic post-process strategy. Our single model achieves 90.4(F1) on the CoQA test set without data augmentation, outperforming the current state-of-the-art single model by 2.6% F1.
Pretata: predicting TATA binding proteins with novel features and dimensionality reduction strategy
Mar 07, 2017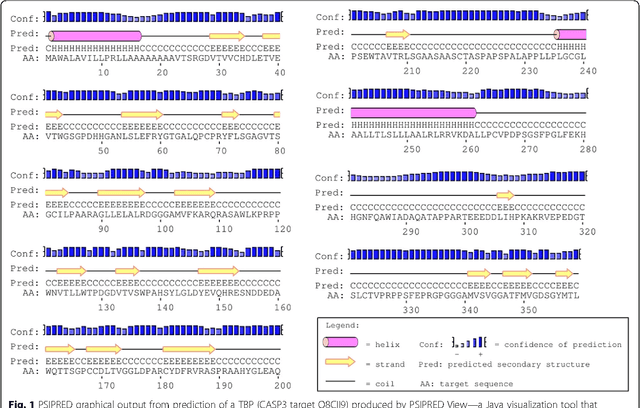
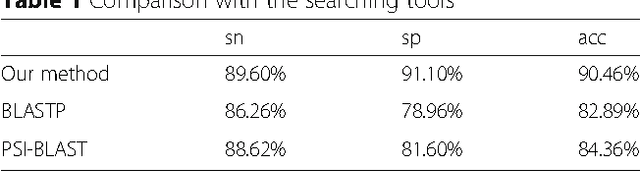
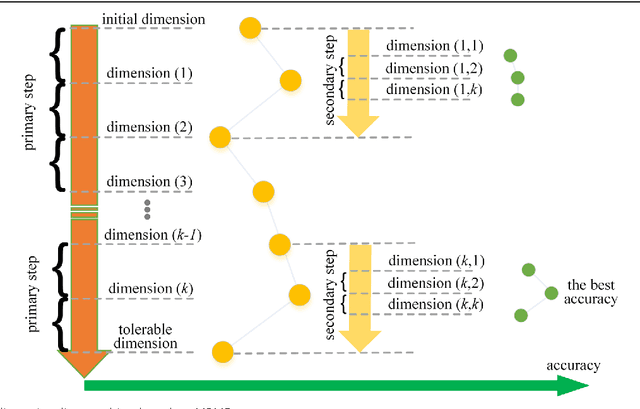
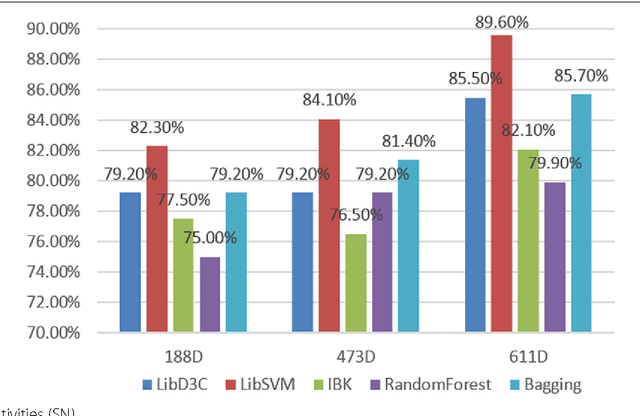
Background: It is necessary and essential to discovery protein function from the novel primary sequences. Wet lab experimental procedures are not only time-consuming, but also costly, so predicting protein structure and function reliably based only on amino acid sequence has significant value. TATA-binding protein (TBP) is a kind of DNA binding protein, which plays a key role in the transcription regulation. Our study proposed an automatic approach for identifying TATA-binding proteins efficiently, accurately, and conveniently. This method would guide for the special protein identification with computational intelligence strategies. Results: Firstly, we proposed novel fingerprint features for TBP based on pseudo amino acid composition, physicochemical properties, and secondary structure. Secondly, hierarchical features dimensionality reduction strategies were employed to improve the performance furthermore. Currently, Pretata achieves 92.92% TATA- binding protein prediction accuracy, which is better than all other existing methods. Conclusions: The experiments demonstrate that our method could greatly improve the prediction accuracy and speed, thus allowing large-scale NGS data prediction to be practical. A web server is developed to facilitate the other researchers, which can be accessed at http://server.malab.cn/preTata/.