 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHPSLPred: An Ensemble Multi-label Classifier for Human Protein Subcellular Location Prediction with Imbalanced Source
Apr 18, 2017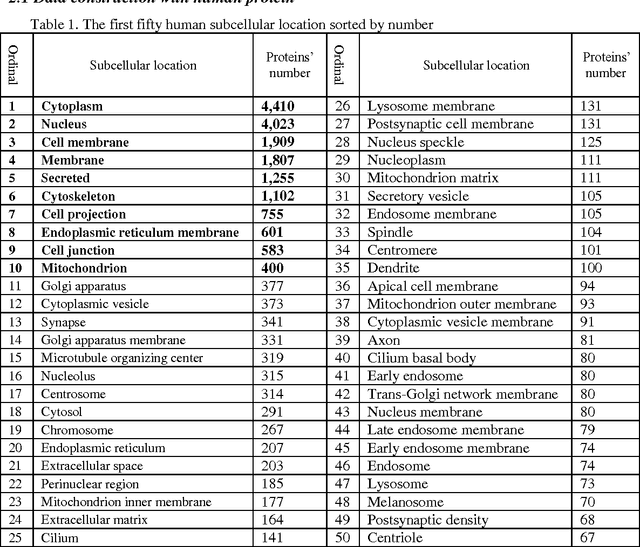
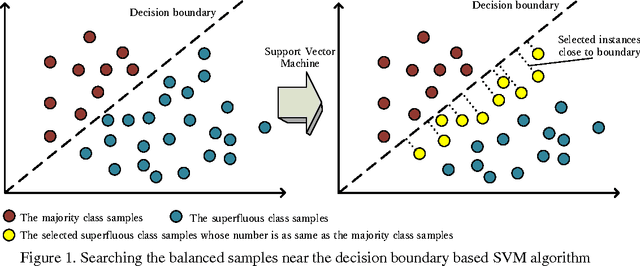
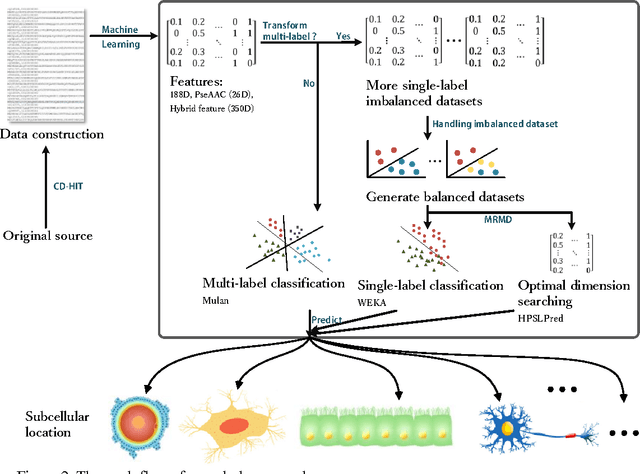

Predicting the subcellular localization of proteins is an important and challenging problem. Traditional experimental approaches are often expensive and time-consuming. Consequently, a growing number of research efforts employ a series of machine learning approaches to predict the subcellular location of proteins. There are two main challenges among the state-of-the-art prediction methods. First, most of the existing techniques are designed to deal with multi-class rather than multi-label classification, which ignores connections between multiple labels. In reality, multiple locations of particular proteins implies that there are vital and unique biological significances that deserve special focus and cannot be ignored. Second, techniques for handling imbalanced data in multi-label classification problems are necessary, but never employed. For solving these two issues, we have developed an ensemble multi-label classifier called HPSLPred, which can be applied for multi-label classification with an imbalanced protein source. For convenience, a user-friendly webserver has been established at http://server.malab.cn/HPSLPred.
Pretata: predicting TATA binding proteins with novel features and dimensionality reduction strategy
Mar 07, 2017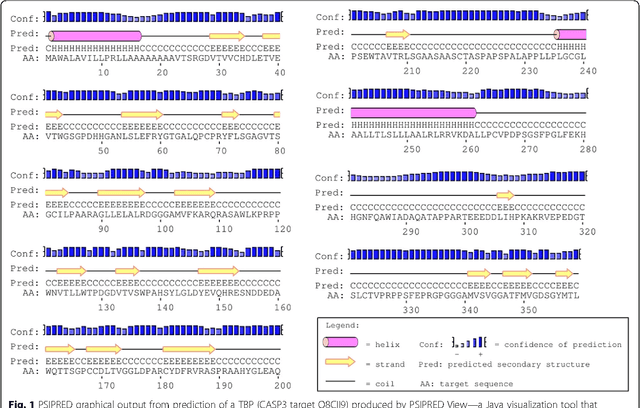
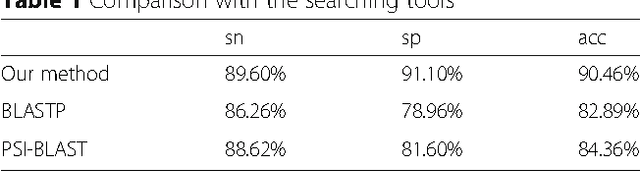
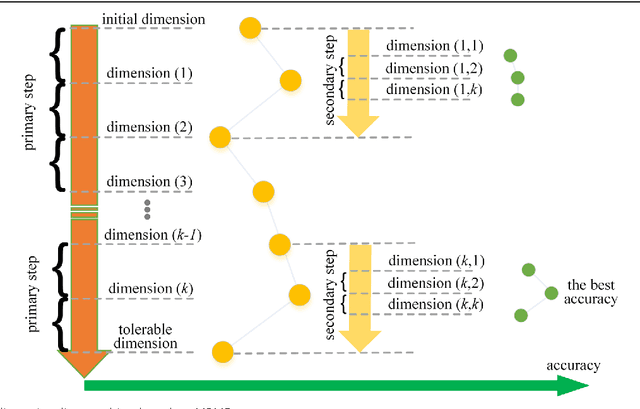
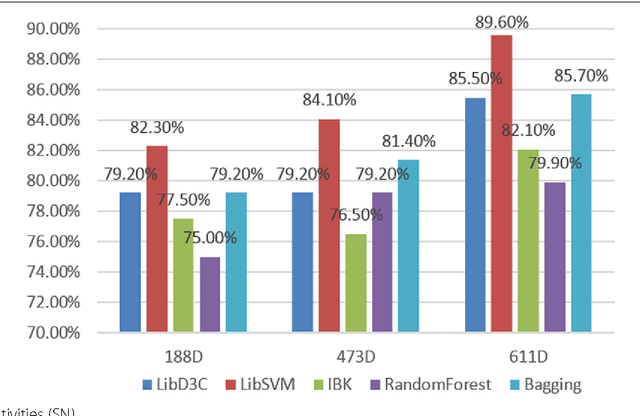
Background: It is necessary and essential to discovery protein function from the novel primary sequences. Wet lab experimental procedures are not only time-consuming, but also costly, so predicting protein structure and function reliably based only on amino acid sequence has significant value. TATA-binding protein (TBP) is a kind of DNA binding protein, which plays a key role in the transcription regulation. Our study proposed an automatic approach for identifying TATA-binding proteins efficiently, accurately, and conveniently. This method would guide for the special protein identification with computational intelligence strategies. Results: Firstly, we proposed novel fingerprint features for TBP based on pseudo amino acid composition, physicochemical properties, and secondary structure. Secondly, hierarchical features dimensionality reduction strategies were employed to improve the performance furthermore. Currently, Pretata achieves 92.92% TATA- binding protein prediction accuracy, which is better than all other existing methods. Conclusions: The experiments demonstrate that our method could greatly improve the prediction accuracy and speed, thus allowing large-scale NGS data prediction to be practical. A web server is developed to facilitate the other researchers, which can be accessed at http://server.malab.cn/preTata/.