 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlcLaM: Arabic Dialectal Language Model
Jul 18, 2024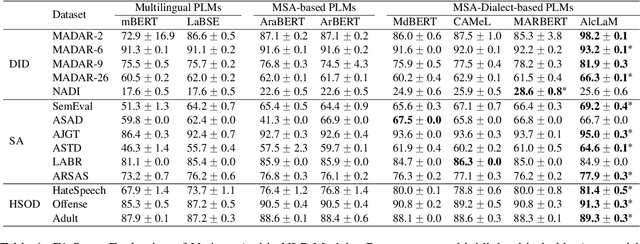
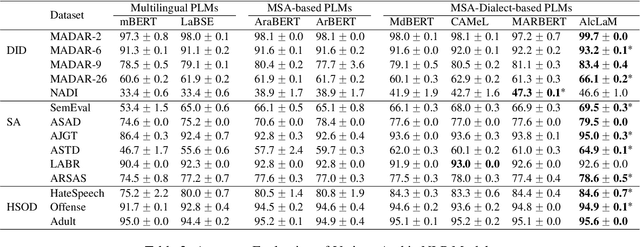
Pre-trained Language Models (PLMs) are integral to many modern natural language processing (NLP) systems. Although multilingual models cover a wide range of languages, they often grapple with challenges like high inference costs and a lack of diverse non-English training data. Arabic-specific PLMs are trained predominantly on modern standard Arabic, which compromises their performance on regional dialects. To tackle this, we construct an Arabic dialectal corpus comprising 3.4M sentences gathered from social media platforms. We utilize this corpus to expand the vocabulary and retrain a BERT-based model from scratch. Named AlcLaM, our model was trained using only 13 GB of text, which represents a fraction of the data used by existing models such as CAMeL, MARBERT, and ArBERT, compared to 7.8%, 10.2%, and 21.3%, respectively. Remarkably, AlcLaM demonstrates superior performance on a variety of Arabic NLP tasks despite the limited training data. AlcLaM is available at GitHub https://github.com/amurtadha/Alclam and HuggingFace https://huggingface.co/rahbi.
Naive Bayes-based Context Extension for Large Language Models
Mar 26, 2024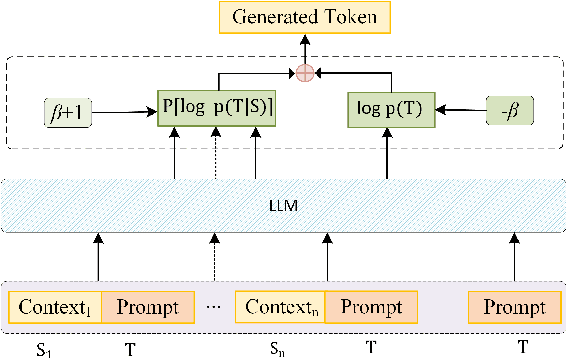
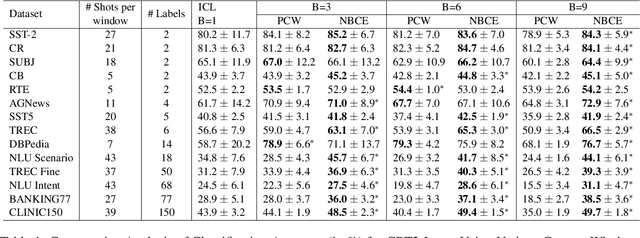
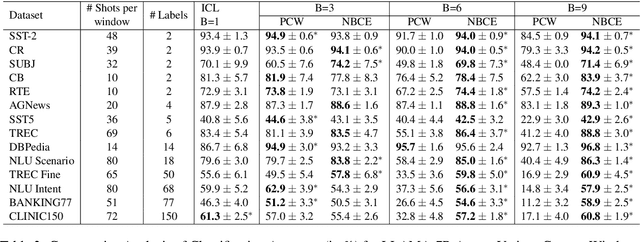
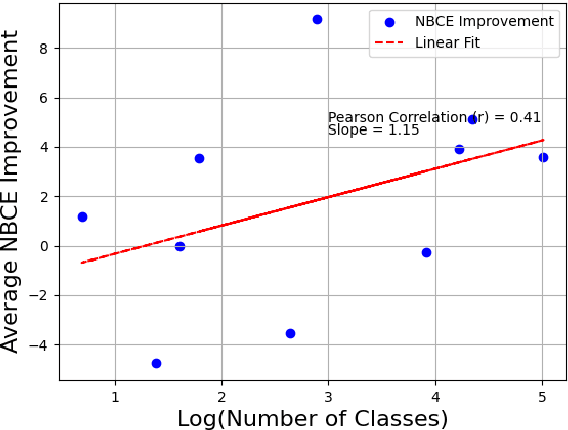
Large Language Models (LLMs) have shown promising in-context learning abilities. However, conventional In-Context Learning (ICL) approaches are often impeded by length limitations of transformer architecture, which pose challenges when attempting to effectively integrate supervision from a substantial number of demonstration examples. In this paper, we introduce a novel framework, called Naive Bayes-based Context Extension (NBCE), to enable existing LLMs to perform ICL with an increased number of demonstrations by significantly expanding their context size. Importantly, this expansion does not require fine-tuning or dependence on particular model architectures, all the while preserving linear efficiency. NBCE initially splits the context into equal-sized windows fitting the target LLM's maximum length. Then, it introduces a voting mechanism to select the most relevant window, regarded as the posterior context. Finally, it employs Bayes' theorem to generate the test task. Our experimental results demonstrate that NBCE substantially enhances performance, particularly as the number of demonstration examples increases, consistently outperforming alternative methods. The NBCE code will be made publicly accessible. The code NBCE is available at: https://github.com/amurtadha/NBCE-master
Rank-Aware Negative Training for Semi-Supervised Text Classification
Jun 13, 2023Semi-supervised text classification-based paradigms (SSTC) typically employ the spirit of self-training. The key idea is to train a deep classifier on limited labeled texts and then iteratively predict the unlabeled texts as their pseudo-labels for further training. However, the performance is largely affected by the accuracy of pseudo-labels, which may not be significant in real-world scenarios. This paper presents a Rank-aware Negative Training (RNT) framework to address SSTC in learning with noisy label manner. To alleviate the noisy information, we adapt a reasoning with uncertainty-based approach to rank the unlabeled texts based on the evidential support received from the labeled texts. Moreover, we propose the use of negative training to train RNT based on the concept that ``the input instance does not belong to the complementary label''. A complementary label is randomly selected from all labels except the label on-target. Intuitively, the probability of a true label serving as a complementary label is low and thus provides less noisy information during the training, resulting in better performance on the test data. Finally, we evaluate the proposed solution on various text classification benchmark datasets. Our extensive experiments show that it consistently overcomes the state-of-the-art alternatives in most scenarios and achieves competitive performance in the others. The code of RNT is publicly available at:https://github.com/amurtadha/RNT.
Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition
Aug 05, 2022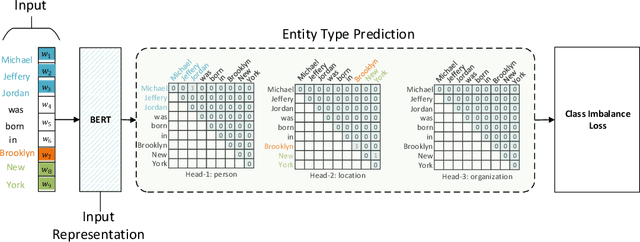
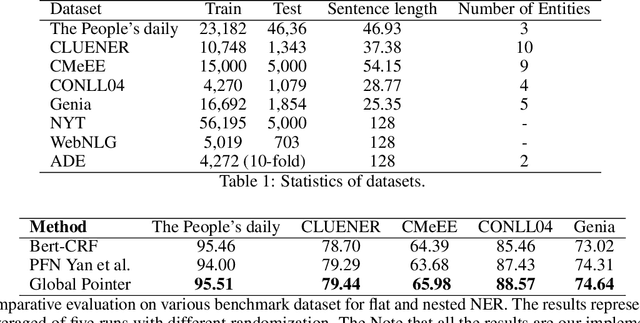
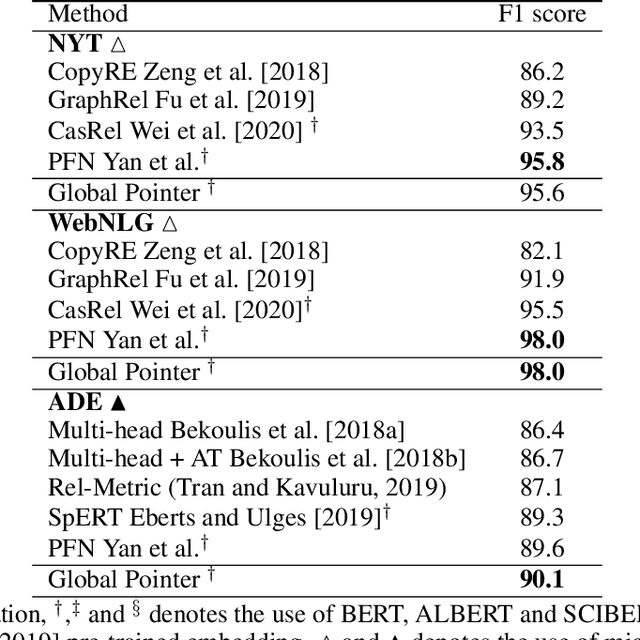

Named entity recognition (NER) task aims at identifying entities from a piece of text that belong to predefined semantic types such as person, location, organization, etc. The state-of-the-art solutions for flat entities NER commonly suffer from capturing the fine-grained semantic information in underlying texts. The existing span-based approaches overcome this limitation, but the computation time is still a concern. In this work, we propose a novel span-based NER framework, namely Global Pointer (GP), that leverages the relative positions through a multiplicative attention mechanism. The ultimate goal is to enable a global view that considers the beginning and the end positions to predict the entity. To this end, we design two modules to identify the head and the tail of a given entity to enable the inconsistency between the training and inference processes. Moreover, we introduce a novel classification loss function to address the imbalance label problem. In terms of parameters, we introduce a simple but effective approximate method to reduce the training parameters. We extensively evaluate GP on various benchmark datasets. Our extensive experiments demonstrate that GP can outperform the existing solution. Moreover, the experimental results show the efficacy of the introduced loss function compared to softmax and entropy alternatives.
ZLPR: A Novel Loss for Multi-label Classification
Aug 05, 2022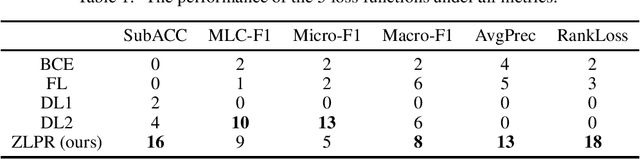
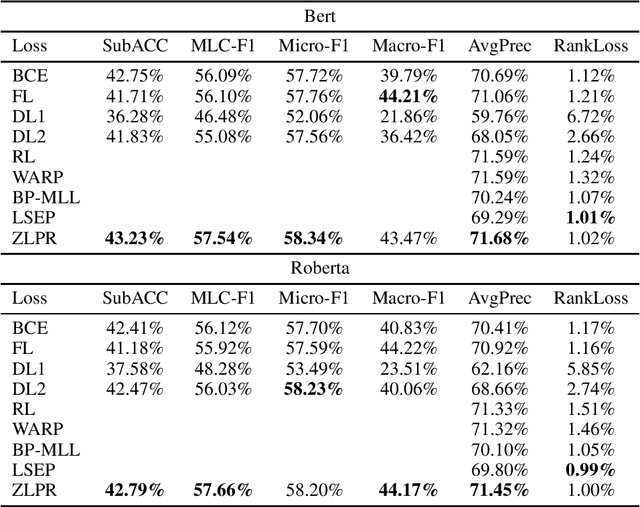
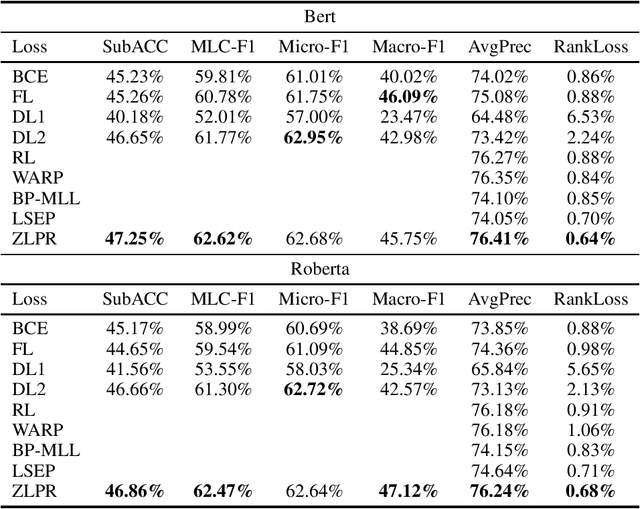
In the era of deep learning, loss functions determine the range of tasks available to models and algorithms. To support the application of deep learning in multi-label classification (MLC) tasks, we propose the ZLPR (zero-bounded log-sum-exp \& pairwise rank-based) loss in this paper. Compared to other rank-based losses for MLC, ZLPR can handel problems that the number of target labels is uncertain, which, in this point of view, makes it equally capable with the other two strategies often used in MLC, namely the binary relevance (BR) and the label powerset (LP). Additionally, ZLPR takes the corelation between labels into consideration, which makes it more comprehensive than the BR methods. In terms of computational complexity, ZLPR can compete with the BR methods because its prediction is also label-independent, which makes it take less time and memory than the LP methods. Our experiments demonstrate the effectiveness of ZLPR on multiple benchmark datasets and multiple evaluation metrics. Moreover, we propose the soft version and the corresponding KL-divergency calculation method of ZLPR, which makes it possible to apply some regularization tricks such as label smoothing to enhance the generalization of models.
BERT-ASC: Auxiliary-Sentence Construction for Implicit Aspect Learning in Sentiment Analysis
Mar 22, 2022
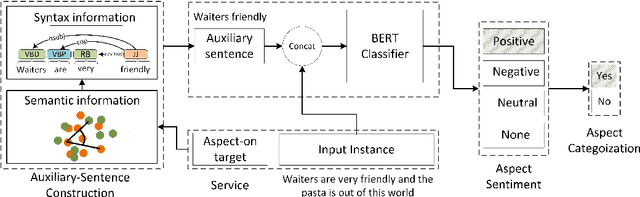
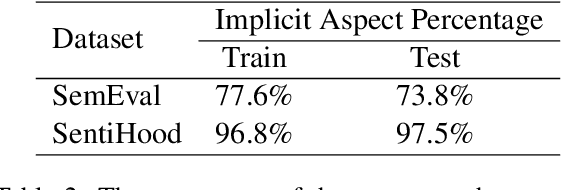

Aspect-based sentiment analysis (ABSA) task aims to associate a piece of text with a set of aspects and meanwhile infer their respective sentimental polarities. Up to now, the state-of-the-art approaches are built upon fine-tuning of various pre-trained language models. They commonly aim to learn the aspect-specific representation in the corpus. Unfortunately, the aspect is often expressed implicitly through a set of representatives and thus renders implicit mapping process unattainable unless sufficient labeled examples. In this paper, we propose to jointly address aspect categorization and aspect-based sentiment subtasks in a unified framework. Specifically, we first introduce a simple but effective mechanism that collaborates the semantic and syntactic information to construct auxiliary-sentences for the implicit aspect. Then, we encourage BERT to learn the aspect-specific representation in response to the automatically constructed auxiliary-sentence instead of the aspect itself. Finally, we empirically evaluate the performance of the proposed solution by a comparative study on real benchmark datasets for both ABSA and Targeted-ABSA tasks. Our extensive experiments show that it consistently achieves state-of-the-art performance in terms of aspect categorization and aspect-based sentiment across all datasets and the improvement margins are considerable.
Efficient Speech Emotion Recognition Using Multi-Scale CNN and Attention
Jun 08, 2021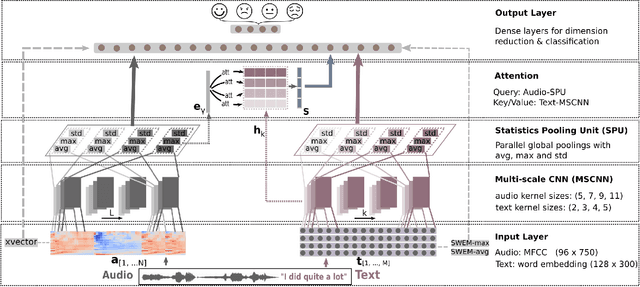
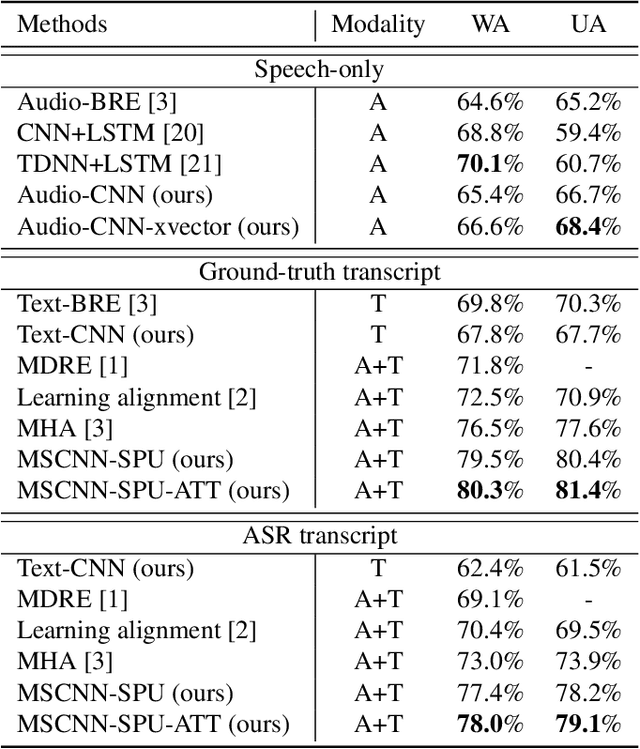

Emotion recognition from speech is a challenging task. Re-cent advances in deep learning have led bi-directional recur-rent neural network (Bi-RNN) and attention mechanism as astandard method for speech emotion recognition, extractingand attending multi-modal features - audio and text, and thenfusing them for downstream emotion classification tasks. Inthis paper, we propose a simple yet efficient neural networkarchitecture to exploit both acoustic and lexical informationfrom speech. The proposed framework using multi-scale con-volutional layers (MSCNN) to obtain both audio and text hid-den representations. Then, a statistical pooling unit (SPU)is used to further extract the features in each modality. Be-sides, an attention module can be built on top of the MSCNN-SPU (audio) and MSCNN (text) to further improve the perfor-mance. Extensive experiments show that the proposed modeloutperforms previous state-of-the-art methods on IEMOCAPdataset with four emotion categories (i.e., angry, happy, sadand neutral) in both weighted accuracy (WA) and unweightedaccuracy (UA), with an improvement of 5.0% and 5.2% respectively under the ASR setting.
* First two authors contributed equally.Accepted by ICASSP 2021
RoFormer: Enhanced Transformer with Rotary Position Embedding
Apr 20, 2021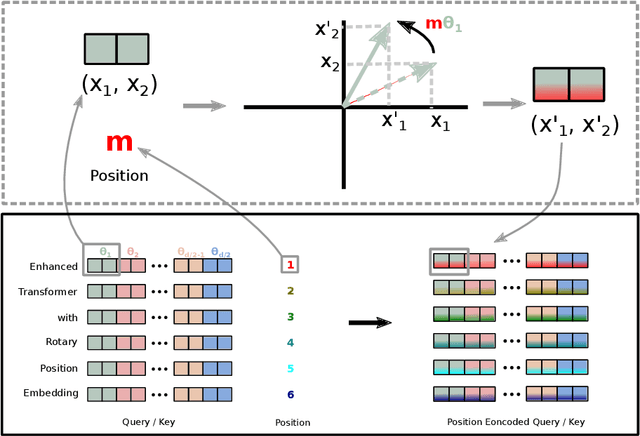
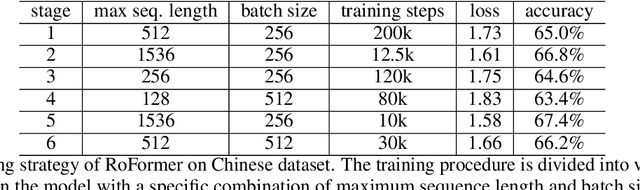
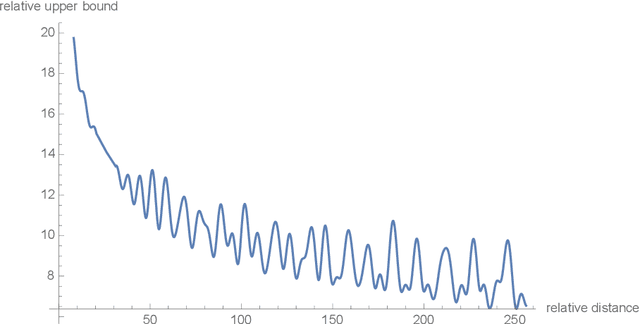
Position encoding in transformer architecture provides supervision for dependency modeling between elements at different positions in the sequence. We investigate various methods to encode positional information in transformer-based language models and propose a novel implementation named Rotary Position Embedding(RoPE). The proposed RoPE encodes absolute positional information with rotation matrix and naturally incorporates explicit relative position dependency in self-attention formulation. Notably, RoPE comes with valuable properties such as flexibility of being expand to any sequence lengths, decaying inter-token dependency with increasing relative distances, and capability of equipping the linear self-attention with relative position encoding. As a result, the enhanced transformer with rotary position embedding, or RoFormer, achieves superior performance in tasks with long texts. We release the theoretical analysis along with some preliminary experiment results on Chinese data. The undergoing experiment for English benchmark will soon be updated.
TableQA: a Large-Scale Chinese Text-to-SQL Dataset for Table-Aware SQL Generation
Jun 10, 2020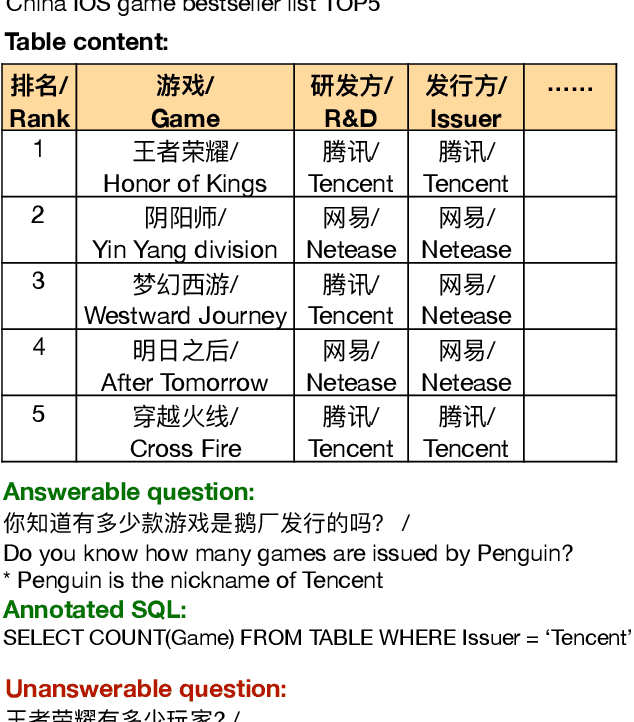



Parsing natural language to corresponding SQL (NL2SQL) with data driven approaches like deep neural networks attracts much attention in recent years. Existing NL2SQL datasets assume that condition values should appear exactly in natural language questions and the queries are answerable given the table. However, these assumptions may fail in practical scenarios, because user may use different expressions for the same content in the table, and query information outside the table without the full picture of contents in table. Therefore we present TableQA, a large-scale cross-domain Natural Language to SQL dataset in Chinese language consisting 64,891 questions and 20,311 unique SQL queries on over 6,000 tables. Different from exisiting NL2SQL datasets, TableQA requires to generalize well not only to SQL skeletons of different questions and table schemas, but also to the various expressions for condition values. Experiment results show that the state-of-the-art model with 95.1% condition value accuracy on WikiSQL only gets 46.8% condition value accuracy and 43.0% logic form accuracy on TableQA, indicating the proposed dataset is challenging and necessary to handle. Two table-aware approaches are proposed to alleviate the problem, the end-to-end approaches obtains 51.3% and 47.4% accuracy on the condition value and logic form tasks, with improvement of 4.7% and 3.4% respectively.
Technical report on Conversational Question Answering
Sep 24, 2019
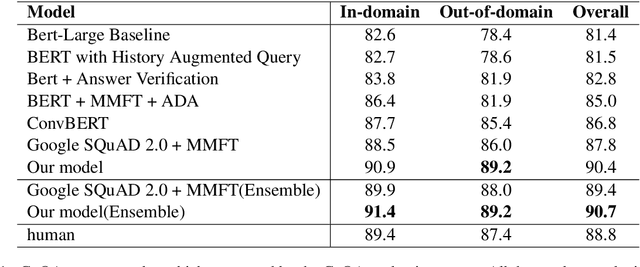
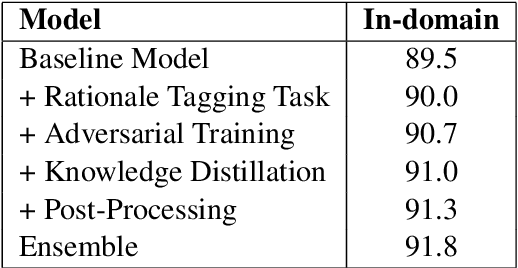
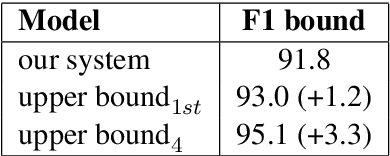
Conversational Question Answering is a challenging task since it requires understanding of conversational history. In this project, we propose a new system RoBERTa + AT +KD, which involves rationale tagging multi-task, adversarial training, knowledge distillation and a linguistic post-process strategy. Our single model achieves 90.4(F1) on the CoQA test set without data augmentation, outperforming the current state-of-the-art single model by 2.6% F1.