 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKCoEvo: A Knowledge Graph Augmented Framework for Evolutionary Code Generation
Mar 08, 2026Code evolution is inevitable in modern software development. Changes to third-party APIs frequently break existing code and complicate maintenance, posing practical challenges for developers. While large language models (LLMs) have shown promise in code generation, they struggle to reason without a structured representation of these evolving relationships, often leading them to produce outdated APIs or invalid outputs. In this work, we propose a knowledge graph-augmented framework that decomposes the migration task into two synergistic stages: evolution path retrieval and path-informed code generation. Our approach constructs static and dynamic API graphs to model intra-version structures and cross-version transitions, enabling structured reasoning over API evolution. Both modules are trained with synthetic supervision automatically derived from real-world API diffs, ensuring scalability and minimal human effort. Extensive experiments across single-package and multi-package benchmarks demonstrate that our framework significantly improves migration accuracy, controllability, and execution success over standard LLM baselines. The source code and datasets are available at: https://github.com/kangjz1203/KCoEvo.
LFPO: Likelihood-Free Policy Optimization for Masked Diffusion Models
Mar 02, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has achieved remarkable success in improving autoregressive models, especially in domains requiring correctness like mathematical reasoning and code generation. However, directly applying such paradigms to Diffusion Large Language Models (dLLMs) is fundamentally hindered by the intractability of exact likelihood computation, which forces existing methods to rely on high-variance approximations. To bridge this gap, we propose Likelihood-Free Policy Optimization (LFPO), a native framework that maps the concept of vector field flow matching to the discrete token space. Specifically, LFPO formulates alignment as geometric velocity rectification, which directly optimizes denoising logits via contrastive updates. This design effectively bypasses the errors inherent in likelihood approximation, yielding the precise gradient estimation. Furthermore, LFPO enforce consistency by predicting final solutions from intermediate steps, effectively straightening the probability flow to enable high-quality generation with significantly fewer iterations. Extensive experiments demonstrate that LFPO not only outperforms state-of-the-art baselines on code and reasoning benchmarks but also accelerates inference by approximately 20% through reduced diffusion steps.
ContextModule: Improving Code Completion via Repository-level Contextual Information
Dec 11, 2024Large Language Models (LLMs) have demonstrated impressive capabilities in code completion tasks, where they assist developers by predicting and generating new code in real-time. However, existing LLM-based code completion systems primarily rely on the immediate context of the file being edited, often missing valuable repository-level information, user behaviour and edit history that could improve suggestion accuracy. Additionally, challenges such as efficiently retrieving relevant code snippets from large repositories, incorporating user behavior, and balancing accuracy with low-latency requirements in production environments remain unresolved. In this paper, we propose ContextModule, a framework designed to enhance LLM-based code completion by retrieving and integrating three types of contextual information from the repository: user behavior-based code, similar code snippets, and critical symbol definitions. By capturing user interactions across files and leveraging repository-wide static analysis, ContextModule improves the relevance and precision of generated code. We implement performance optimizations, such as index caching, to ensure the system meets the latency constraints of real-world coding environments. Experimental results and industrial practise demonstrate that ContextModule significantly improves code completion accuracy and user acceptance rates.
TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities
Dec 13, 2022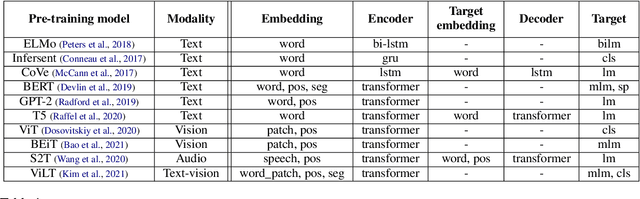
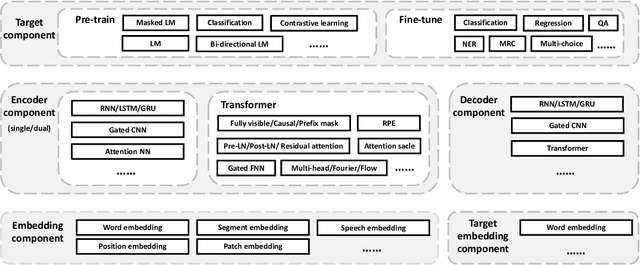
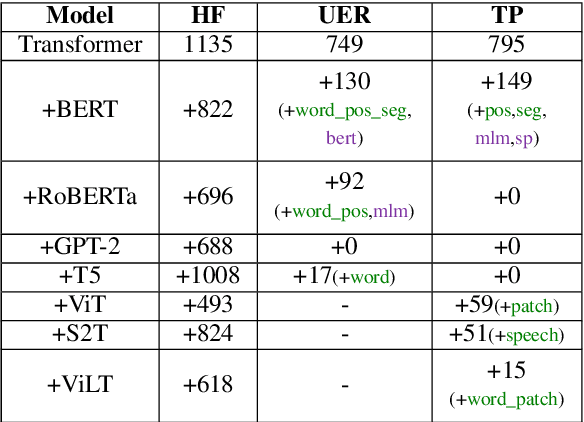
Recently, the success of pre-training in text domain has been fully extended to vision, audio, and cross-modal scenarios. The proposed pre-training models of different modalities are showing a rising trend of homogeneity in their model structures, which brings the opportunity to implement different pre-training models within a uniform framework. In this paper, we present TencentPretrain, a toolkit supporting pre-training models of different modalities. The core feature of TencentPretrain is the modular design. The toolkit uniformly divides pre-training models into 5 components: embedding, encoder, target embedding, decoder, and target. As almost all of common modules are provided in each component, users can choose the desired modules from different components to build a complete pre-training model. The modular design enables users to efficiently reproduce existing pre-training models or build brand-new one. We test the toolkit on text, vision, and audio benchmarks and show that it can match the performance of the original implementations.
Offset-Guided Attention Network for Room-Level Aware Floor Plan Segmentation
Oct 22, 2022Recognition of floor plans has been a challenging and popular task. Despite that many recent approaches have been proposed for this task, they typically fail to make the room-level unified prediction. Specifically, multiple semantic categories can be assigned in a single room, which seriously limits their visual quality and applicability. In this paper, we propose a novel approach to recognize the floor plan layouts with a newly proposed Offset-Guided Attention mechanism to improve the semantic consistency within a room. In addition, we present a Feature Fusion Attention module that leverages the channel-wise attention to encourage the consistency of the room, wall, and door predictions, further enhancing the room-level semantic consistency. Experimental results manifest our approach is able to improve the room-level semantic consistency and outperforms the existing works both qualitatively and quantitatively.
TableQA: a Large-Scale Chinese Text-to-SQL Dataset for Table-Aware SQL Generation
Jun 10, 2020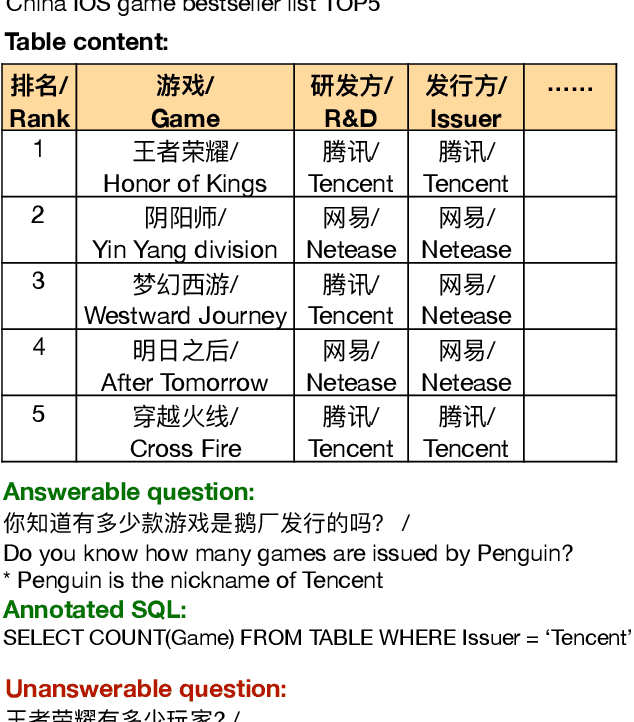



Parsing natural language to corresponding SQL (NL2SQL) with data driven approaches like deep neural networks attracts much attention in recent years. Existing NL2SQL datasets assume that condition values should appear exactly in natural language questions and the queries are answerable given the table. However, these assumptions may fail in practical scenarios, because user may use different expressions for the same content in the table, and query information outside the table without the full picture of contents in table. Therefore we present TableQA, a large-scale cross-domain Natural Language to SQL dataset in Chinese language consisting 64,891 questions and 20,311 unique SQL queries on over 6,000 tables. Different from exisiting NL2SQL datasets, TableQA requires to generalize well not only to SQL skeletons of different questions and table schemas, but also to the various expressions for condition values. Experiment results show that the state-of-the-art model with 95.1% condition value accuracy on WikiSQL only gets 46.8% condition value accuracy and 43.0% logic form accuracy on TableQA, indicating the proposed dataset is challenging and necessary to handle. Two table-aware approaches are proposed to alleviate the problem, the end-to-end approaches obtains 51.3% and 47.4% accuracy on the condition value and logic form tasks, with improvement of 4.7% and 3.4% respectively.