 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities
Dec 13, 2022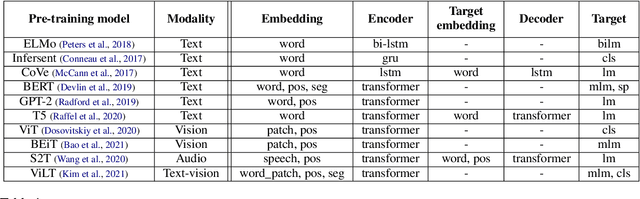
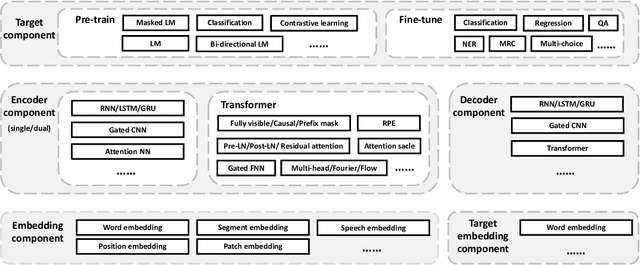
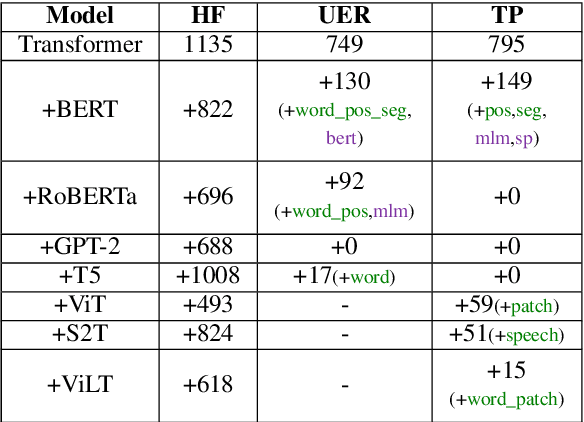
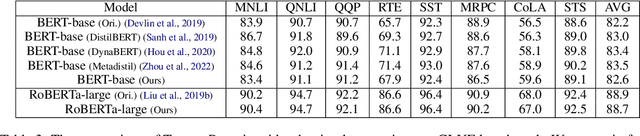
Recently, the success of pre-training in text domain has been fully extended to vision, audio, and cross-modal scenarios. The proposed pre-training models of different modalities are showing a rising trend of homogeneity in their model structures, which brings the opportunity to implement different pre-training models within a uniform framework. In this paper, we present TencentPretrain, a toolkit supporting pre-training models of different modalities. The core feature of TencentPretrain is the modular design. The toolkit uniformly divides pre-training models into 5 components: embedding, encoder, target embedding, decoder, and target. As almost all of common modules are provided in each component, users can choose the desired modules from different components to build a complete pre-training model. The modular design enables users to efficiently reproduce existing pre-training models or build brand-new one. We test the toolkit on text, vision, and audio benchmarks and show that it can match the performance of the original implementations.
A Simple and Effective Method to Improve Zero-Shot Cross-Lingual Transfer Learning
Oct 18, 2022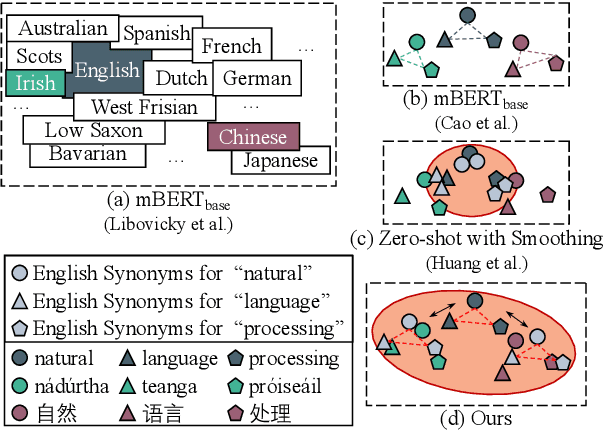
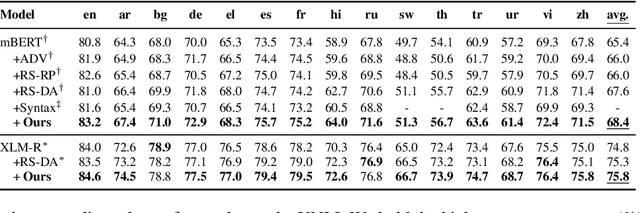
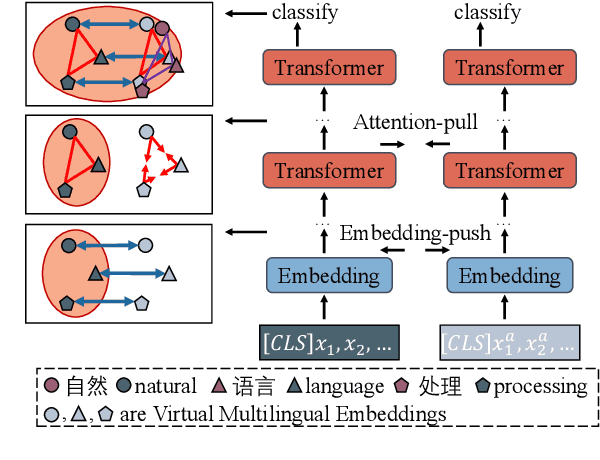
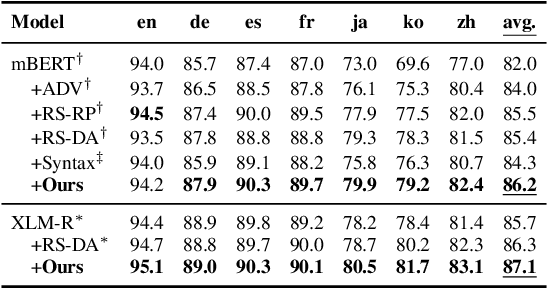
Existing zero-shot cross-lingual transfer methods rely on parallel corpora or bilingual dictionaries, which are expensive and impractical for low-resource languages. To disengage from these dependencies, researchers have explored training multilingual models on English-only resources and transferring them to low-resource languages. However, its effect is limited by the gap between embedding clusters of different languages. To address this issue, we propose Embedding-Push, Attention-Pull, and Robust targets to transfer English embeddings to virtual multilingual embeddings without semantic loss, thereby improving cross-lingual transferability. Experimental results on mBERT and XLM-R demonstrate that our method significantly outperforms previous works on the zero-shot cross-lingual text classification task and can obtain a better multilingual alignment.
SAMP: A Toolkit for Model Inference with Self-Adaptive Mixed-Precision
Sep 19, 2022
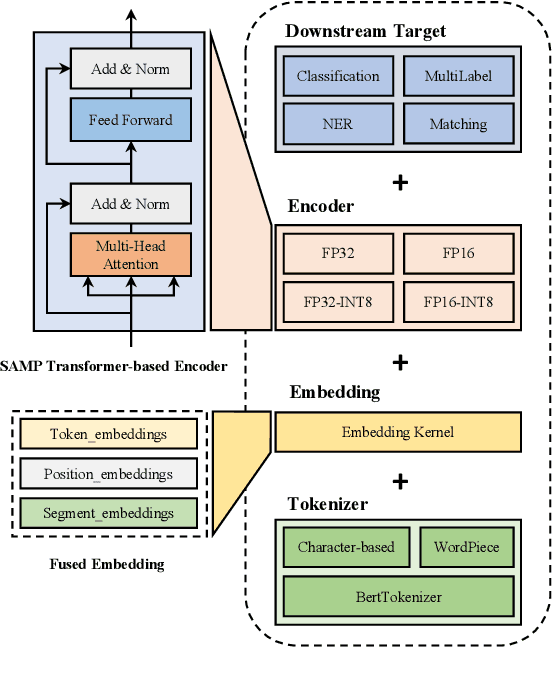
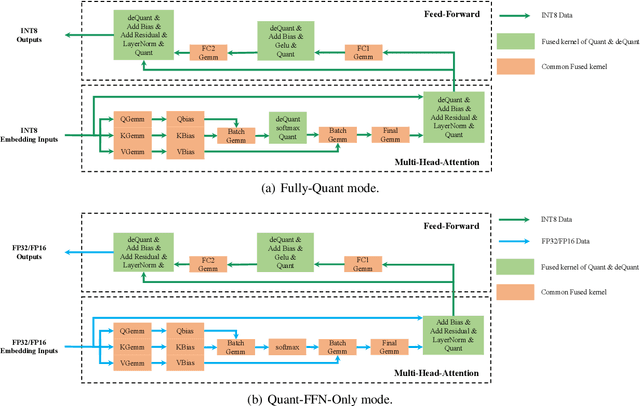
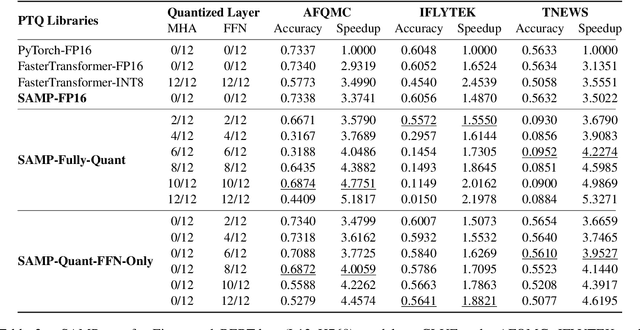
The latest industrial inference engines, such as FasterTransformer1 and TurboTransformers, have verified that half-precision floating point (FP16) and 8-bit integer (INT8) quantization can greatly improve model inference speed. However, the existing FP16 or INT8 quantization methods are too complicated, and improper usage will lead to performance damage greatly. In this paper, we develop a toolkit for users to easily quantize their models for inference, in which a Self-Adaptive Mixed-Precision (SAMP) is proposed to automatically control quantization rate by a mixed-precision architecture to balance efficiency and performance. Experimental results show that our SAMP toolkit has a higher speedup than PyTorch and FasterTransformer while ensuring the required performance. In addition, SAMP is based on a modular design, decoupling the tokenizer, embedding, encoder and target layers, which allows users to handle various downstream tasks and can be seamlessly integrated into PyTorch.
CSL: A Large-scale Chinese Scientific Literature Dataset
Sep 12, 2022
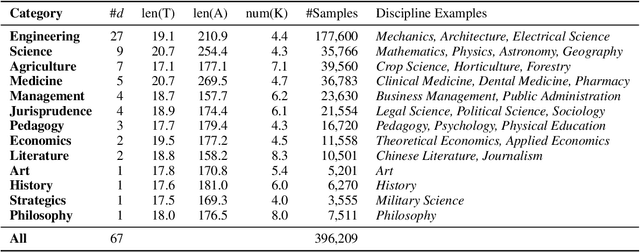
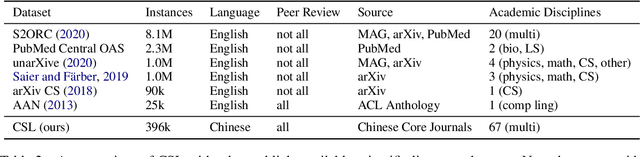
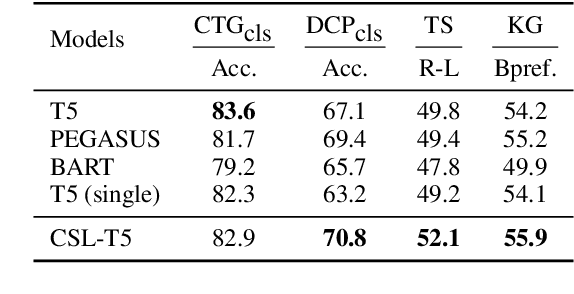
Scientific literature serves as a high-quality corpus, supporting a lot of Natural Language Processing (NLP) research. However, existing datasets are centered around the English language, which restricts the development of Chinese scientific NLP. In this work, we present CSL, a large-scale Chinese Scientific Literature dataset, which contains the titles, abstracts, keywords and academic fields of 396k papers. To our knowledge, CSL is the first scientific document dataset in Chinese. The CSL can serve as a Chinese corpus. Also, this semi-structured data is a natural annotation that can constitute many supervised NLP tasks. Based on CSL, we present a benchmark to evaluate the performance of models across scientific domain tasks, i.e., summarization, keyword generation and text classification. We analyze the behavior of existing text-to-text models on the evaluation tasks and reveal the challenges for Chinese scientific NLP tasks, which provides a valuable reference for future research. Data and code are available at https://github.com/ydli-ai/CSL
Semantic Matching from Different Perspectives
Feb 14, 2022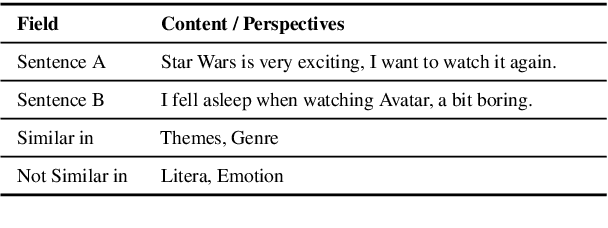
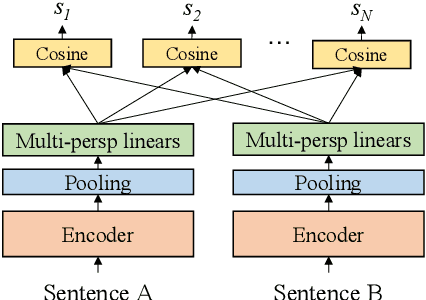
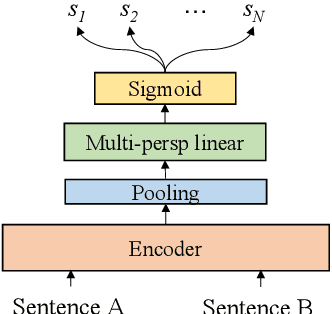

In this paper, we pay attention to the issue which is usually overlooked, i.e., \textit{similarity should be determined from different perspectives}. To explore this issue, we release a Multi-Perspective Text Similarity (MPTS) dataset, in which sentence similarities are labeled from twelve perspectives. Furthermore, we conduct a series of experimental analysis on this task by retrofitting some famous text matching models. Finally, we obtain several conclusions and baseline models, laying the foundation for the following investigation of this issue. The dataset and code are publicly available at Github\footnote{\url{https://github.com/autoliuweijie/MPTS}
Topic Detection and Tracking with Time-Aware Document Embeddings
Dec 12, 2021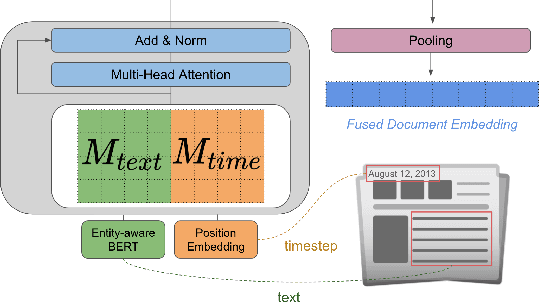

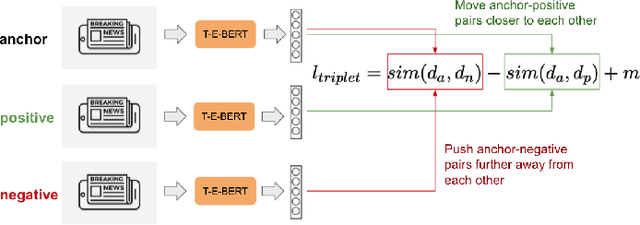
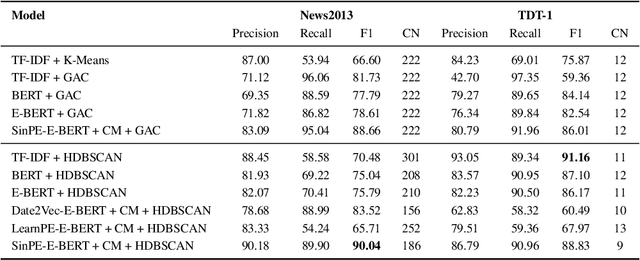
The time at which a message is communicated is a vital piece of metadata in many real-world natural language processing tasks such as Topic Detection and Tracking (TDT). TDT systems aim to cluster a corpus of news articles by event, and in that context, stories that describe the same event are likely to have been written at around the same time. Prior work on time modeling for TDT takes this into account, but does not well capture how time interacts with the semantic nature of the event. For example, stories about a tropical storm are likely to be written within a short time interval, while stories about a movie release may appear over weeks or months. In our work, we design a neural method that fuses temporal and textual information into a single representation of news documents for event detection. We fine-tune these time-aware document embeddings with a triplet loss architecture, integrate the model into downstream TDT systems, and evaluate the systems on two benchmark TDT data sets in English. In the retrospective setting, we apply clustering algorithms to the time-aware embeddings and show substantial improvements over baselines on the News2013 data set. In the online streaming setting, we add our document encoder to an existing state-of-the-art TDT pipeline and demonstrate that it can benefit the overall performance. We conduct ablation studies on the time representation and fusion algorithm strategies, showing that our proposed model outperforms alternative strategies. Finally, we probe the model to examine how it handles recurring events more effectively than previous TDT systems.
TunaGAN: Interpretable GAN for Smart Editing
Aug 16, 2019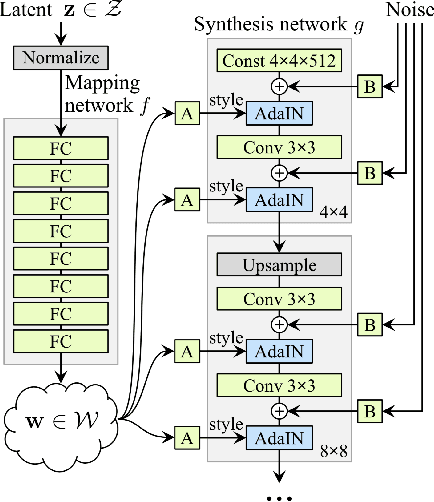
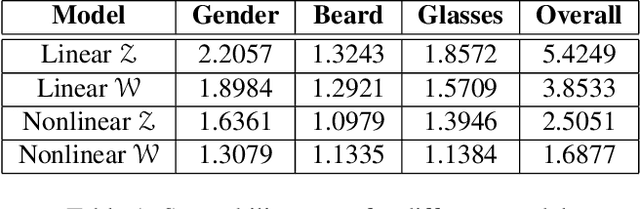
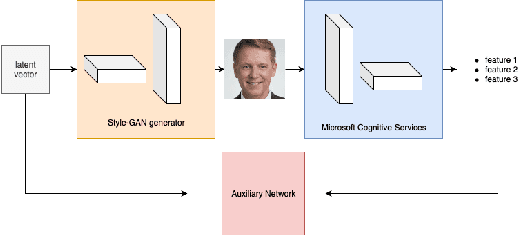

In this paper, we introduce a tunable generative adversary network (TunaGAN) that uses an auxiliary network on top of existing generator networks (Style-GAN) to modify high-resolution face images according to user's high-level instructions, with good qualitative and quantitative performance. To optimize for feature disentanglement, we also investigate two different latent space that could be traversed for modification. The problem of mode collapse is characterized in detail for model robustness. This work could be easily extended to content-aware image editor based on other GANs and provide insight on mode collapse problems in more general settings.