 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASSESS: A Semantic and Structural Evaluation Framework for Statement Similarity
Sep 26, 2025Statement autoformalization, the automated translation of statements from natural language into formal languages, has seen significant advancements, yet the development of automated evaluation metrics remains limited. Existing metrics for formal statement similarity often fail to balance semantic and structural information. String-based approaches capture syntactic structure but ignore semantic meaning, whereas proof-based methods validate semantic equivalence but disregard structural nuances and, critically, provide no graded similarity score in the event of proof failure. To address these issues, we introduce ASSESS (A Semantic and Structural Evaluation Framework for Statement Similarity), which comprehensively integrates semantic and structural information to provide a continuous similarity score. Our framework first transforms formal statements into Operator Trees to capture their syntactic structure and then computes a similarity score using our novel TransTED (Transformation Tree Edit Distance) Similarity metric, which enhances traditional Tree Edit Distance by incorporating semantic awareness through transformations. For rigorous validation, we present EPLA (Evaluating Provability and Likeness for Autoformalization), a new benchmark of 524 expert-annotated formal statement pairs derived from miniF2F and ProofNet, with labels for both semantic provability and structural likeness. Experiments on EPLA demonstrate that TransTED Similarity outperforms existing methods, achieving state-of-the-art accuracy and the highest Kappa coefficient. The benchmark, and implementation code will be made public soon.
Generalized Tree Edit Distance (GTED): A Faithful Evaluation Metric for Statement Autoformalization
Jul 10, 2025Statement autoformalization, the automated translation of statement from natural language into formal languages, has become a subject of extensive research, yet the development of robust automated evaluation metrics remains limited. Existing evaluation methods often lack semantic understanding, face challenges with high computational costs, and are constrained by the current progress of automated theorem proving. To address these issues, we propose GTED (Generalized Tree Edit Distance), a novel evaluation framework that first standardizes formal statements and converts them into operator trees, then determines the semantic similarity using the eponymous GTED metric. On the miniF2F and ProofNet benchmarks, GTED outperforms all baseline metrics by achieving the highest accuracy and Kappa scores, thus providing the community with a more faithful metric for automated evaluation. The code and experimental results are available at https://github.com/XiaoyangLiu-sjtu/GTED.
A Data Synthesis Method Driven by Large Language Models for Proactive Mining of Implicit User Intentions in Tourism
May 14, 2025



In the tourism domain, Large Language Models (LLMs) often struggle to mine implicit user intentions from tourists' ambiguous inquiries and lack the capacity to proactively guide users toward clarifying their needs. A critical bottleneck is the scarcity of high-quality training datasets that facilitate proactive questioning and implicit intention mining. While recent advances leverage LLM-driven data synthesis to generate such datasets and transfer specialized knowledge to downstream models, existing approaches suffer from several shortcomings: (1) lack of adaptation to the tourism domain, (2) skewed distributions of detail levels in initial inquiries, (3) contextual redundancy in the implicit intention mining module, and (4) lack of explicit thinking about tourists' emotions and intention values. Therefore, we propose SynPT (A Data Synthesis Method Driven by LLMs for Proactive Mining of Implicit User Intentions in the Tourism), which constructs an LLM-driven user agent and assistant agent to simulate dialogues based on seed data collected from Chinese tourism websites. This approach addresses the aforementioned limitations and generates SynPT-Dialog, a training dataset containing explicit reasoning. The dataset is utilized to fine-tune a general LLM, enabling it to proactively mine implicit user intentions. Experimental evaluations, conducted from both human and LLM perspectives, demonstrate the superiority of SynPT compared to existing methods. Furthermore, we analyze key hyperparameters and present case studies to illustrate the practical applicability of our method, including discussions on its adaptability to English-language scenarios. All code and data are publicly available.
ProDisc-VAD: An Efficient System for Weakly-Supervised Anomaly Detection in Video Surveillance Applications
May 04, 2025Weakly-supervised video anomaly detection (WS-VAD) using Multiple Instance Learning (MIL) suffers from label ambiguity, hindering discriminative feature learning. We propose ProDisc-VAD, an efficient framework tackling this via two synergistic components. The Prototype Interaction Layer (PIL) provides controlled normality modeling using a small set of learnable prototypes, establishing a robust baseline without being overwhelmed by dominant normal data. The Pseudo-Instance Discriminative Enhancement (PIDE) loss boosts separability by applying targeted contrastive learning exclusively to the most reliable extreme-scoring instances (highest/lowest scores). ProDisc-VAD achieves strong AUCs (97.98% ShanghaiTech, 87.12% UCF-Crime) using only 0.4M parameters, over 800x fewer than recent ViT-based methods like VadCLIP, demonstrating exceptional efficiency alongside state-of-the-art performance. Code is available at https://github.com/modadundun/ProDisc-VAD.
Unified Autoregressive Visual Generation and Understanding with Continuous Tokens
Mar 17, 2025We present UniFluid, a unified autoregressive framework for joint visual generation and understanding leveraging continuous visual tokens. Our unified autoregressive architecture processes multimodal image and text inputs, generating discrete tokens for text and continuous tokens for image. We find though there is an inherent trade-off between the image generation and understanding task, a carefully tuned training recipe enables them to improve each other. By selecting an appropriate loss balance weight, the unified model achieves results comparable to or exceeding those of single-task baselines on both tasks. Furthermore, we demonstrate that employing stronger pre-trained LLMs and random-order generation during training is important to achieve high-fidelity image generation within this unified framework. Built upon the Gemma model series, UniFluid exhibits competitive performance across both image generation and understanding, demonstrating strong transferability to various downstream tasks, including image editing for generation, as well as visual captioning and question answering for understanding.
HAR-DoReMi: Optimizing Data Mixture for Self-Supervised Human Activity Recognition Across Heterogeneous IMU Datasets
Mar 16, 2025Cross-dataset Human Activity Recognition (HAR) suffers from limited model generalization, hindering its practical deployment. To address this critical challenge, inspired by the success of DoReMi in Large Language Models (LLMs), we introduce a data mixture optimization strategy for pre-training HAR models, aiming to improve the recognition performance across heterogeneous datasets. However, directly applying DoReMi to the HAR field encounters new challenges due to the continuous, multi-channel and intrinsic heterogeneous characteristics of IMU sensor data. To overcome these limitations, we propose a novel framework HAR-DoReMi, which introduces a masked reconstruction task based on Mean Squared Error (MSE) loss. By raplacing the discrete language sequence prediction task, which relies on the Negative Log-Likelihood (NLL) loss, in the original DoReMi framework, the proposed framework is inherently more appropriate for handling the continuous and multi-channel characteristics of IMU data. In addition, HAR-DoReMi integrates the Mahony fusion algorithm into the self-supervised HAR pre-training, aiming to mitigate the heterogeneity of varying sensor orientation. This is achieved by estimating the sensor orientation within each dataset and facilitating alignment with a unified coordinate system, thereby improving the cross-dataset generalization ability of the HAR model. Experimental evaluation on multiple cross-dataset HAR transfer tasks demonstrates that HAR-DoReMi improves the accuracy by an average of 6.51%, compared to the current state-of-the-art method with only approximately 30% to 50% of the data usage. These results confirm the effectiveness of HAR-DoReMi in improving the generalization and data efficiency of pre-training HAR models, underscoring its significant potential to facilitate the practical deployment of HAR technology.
PTMs-TSCIL Pre-Trained Models Based Class-Incremental Learning
Mar 10, 2025Class-incremental learning (CIL) for time series data faces critical challenges in balancing stability against catastrophic forgetting and plasticity for new knowledge acquisition, particularly under real-world constraints where historical data access is restricted. While pre-trained models (PTMs) have shown promise in CIL for vision and NLP domains, their potential in time series class-incremental learning (TSCIL) remains underexplored due to the scarcity of large-scale time series pre-trained models. Prompted by the recent emergence of large-scale pre-trained models (PTMs) for time series data, we present the first exploration of PTM-based Time Series Class-Incremental Learning (TSCIL). Our approach leverages frozen PTM backbones coupled with incrementally tuning the shared adapter, preserving generalization capabilities while mitigating feature drift through knowledge distillation. Furthermore, we introduce a Feature Drift Compensation Network (DCN), designed with a novel two-stage training strategy to precisely model feature space transformations across incremental tasks. This allows for accurate projection of old class prototypes into the new feature space. By employing DCN-corrected prototypes, we effectively enhance the unified classifier retraining, mitigating model feature drift and alleviating catastrophic forgetting. Extensive experiments on five real-world datasets demonstrate state-of-the-art performance, with our method yielding final accuracy gains of 1.4%-6.1% across all datasets compared to existing PTM-based approaches. Our work establishes a new paradigm for TSCIL, providing insights into stability-plasticity optimization for continual learning systems.
ReLU-KAN: New Kolmogorov-Arnold Networks that Only Need Matrix Addition, Dot Multiplication, and ReLU
Jun 04, 2024

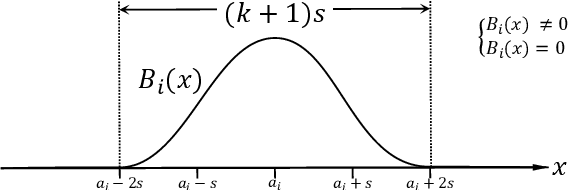
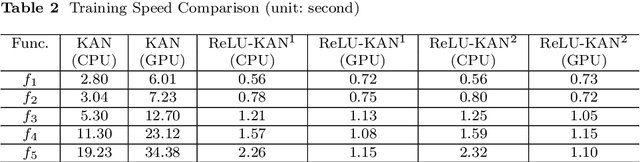
Limited by the complexity of basis function (B-spline) calculations, Kolmogorov-Arnold Networks (KAN) suffer from restricted parallel computing capability on GPUs. This paper proposes a novel ReLU-KAN implementation that inherits the core idea of KAN. By adopting ReLU (Rectified Linear Unit) and point-wise multiplication, we simplify the design of KAN's basis function and optimize the computation process for efficient CUDA computing. The proposed ReLU-KAN architecture can be readily implemented on existing deep learning frameworks (e.g., PyTorch) for both inference and training. Experimental results demonstrate that ReLU-KAN achieves a 20x speedup compared to traditional KAN with 4-layer networks. Furthermore, ReLU-KAN exhibits a more stable training process with superior fitting ability while preserving the "catastrophic forgetting avoidance" property of KAN. You can get the code in https://github.com/quiqi/relu_kan
HARMamba: Efficient Wearable Sensor Human Activity Recognition Based on Bidirectional Selective SSM
Mar 29, 2024



Wearable sensor human activity recognition (HAR) is a crucial area of research in activity sensing. While transformer-based temporal deep learning models have been extensively studied and implemented, their large number of parameters present significant challenges in terms of system computing load and memory usage, rendering them unsuitable for real-time mobile activity recognition applications. Recently, an efficient hardware-aware state space model (SSM) called Mamba has emerged as a promising alternative. Mamba demonstrates strong potential in long sequence modeling, boasts a simpler network architecture, and offers an efficient hardware-aware design. Leveraging SSM for activity recognition represents an appealing avenue for exploration. In this study, we introduce HARMamba, which employs a more lightweight selective SSM as the foundational model architecture for activity recognition. The goal is to address the computational resource constraints encountered in real-time activity recognition scenarios. Our approach involves processing sensor data flow by independently learning each channel and segmenting the data into "patches". The marked sensor sequence's position embedding serves as the input token for the bidirectional state space model, ultimately leading to activity categorization through the classification head. Compared to established activity recognition frameworks like Transformer-based models, HARMamba achieves superior performance while also reducing computational and memory overhead. Furthermore, our proposed method has been extensively tested on four public activity datasets: PAMAP2, WISDM, UNIMIB, and UCI, demonstrating impressive performance in activity recognition tasks.
P2LHAP:Wearable sensor-based human activity recognition, segmentation and forecast through Patch-to-Label Seq2Seq Transformer
Mar 13, 2024Traditional deep learning methods struggle to simultaneously segment, recognize, and forecast human activities from sensor data. This limits their usefulness in many fields such as healthcare and assisted living, where real-time understanding of ongoing and upcoming activities is crucial. This paper introduces P2LHAP, a novel Patch-to-Label Seq2Seq framework that tackles all three tasks in a efficient single-task model. P2LHAP divides sensor data streams into a sequence of "patches", served as input tokens, and outputs a sequence of patch-level activity labels including the predicted future activities. A unique smoothing technique based on surrounding patch labels, is proposed to identify activity boundaries accurately. Additionally, P2LHAP learns patch-level representation by sensor signal channel-independent Transformer encoders and decoders. All channels share embedding and Transformer weights across all sequences. Evaluated on three public datasets, P2LHAP significantly outperforms the state-of-the-art in all three tasks, demonstrating its effectiveness and potential for real-world applications.