 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Onto-Relational-Sophic Framework for Governing Synthetic Minds
Mar 19, 2026The rapid evolution of artificial intelligence, from task-specific systems to foundation models exhibiting broad, flexible competence across reasoning, creative synthesis, and social interaction, has outpaced the conceptual and governance frameworks designed to manage it. Current regulatory paradigms, anchored in a tool-centric worldview, address algorithmic bias and transparency but leave unanswered foundational questions about what increasingly capable synthetic minds are, how societies should relate to them, and the normative principles that should guide their development. Here we introduce the Onto-Relational-Sophic (ORS) framework, grounded in Cyberism philosophy, which offers integrated answers to these challenges through three pillars: (1) a Cyber-Physical-Social-Thinking (CPST) ontology that defines the mode of being for synthetic minds as irreducibly multi-dimensional rather than purely computational; (2) a graded spectrum of digital personhood providing a pragmatic relational taxonomy beyond binary person-or-tool classifications; and (3) Cybersophy, a wisdom-oriented axiology synthesizing virtue ethics, consequentialism, and relational approaches to guide governance. We apply the framework to emergent scenarios including autonomous research agents, AI-mediated healthcare, and agentic AI ecosystems, demonstrating its capacity to generate proportionate, adaptive governance recommendations. The ORS framework charts a path from narrow technical alignment toward comprehensive philosophical foundations for the synthetic minds already among us.
A Data Synthesis Method Driven by Large Language Models for Proactive Mining of Implicit User Intentions in Tourism
May 14, 2025



In the tourism domain, Large Language Models (LLMs) often struggle to mine implicit user intentions from tourists' ambiguous inquiries and lack the capacity to proactively guide users toward clarifying their needs. A critical bottleneck is the scarcity of high-quality training datasets that facilitate proactive questioning and implicit intention mining. While recent advances leverage LLM-driven data synthesis to generate such datasets and transfer specialized knowledge to downstream models, existing approaches suffer from several shortcomings: (1) lack of adaptation to the tourism domain, (2) skewed distributions of detail levels in initial inquiries, (3) contextual redundancy in the implicit intention mining module, and (4) lack of explicit thinking about tourists' emotions and intention values. Therefore, we propose SynPT (A Data Synthesis Method Driven by LLMs for Proactive Mining of Implicit User Intentions in the Tourism), which constructs an LLM-driven user agent and assistant agent to simulate dialogues based on seed data collected from Chinese tourism websites. This approach addresses the aforementioned limitations and generates SynPT-Dialog, a training dataset containing explicit reasoning. The dataset is utilized to fine-tune a general LLM, enabling it to proactively mine implicit user intentions. Experimental evaluations, conducted from both human and LLM perspectives, demonstrate the superiority of SynPT compared to existing methods. Furthermore, we analyze key hyperparameters and present case studies to illustrate the practical applicability of our method, including discussions on its adaptability to English-language scenarios. All code and data are publicly available.
Assessing Text Classification Methods for Cyberbullying Detection on Social Media Platforms
Dec 27, 2024
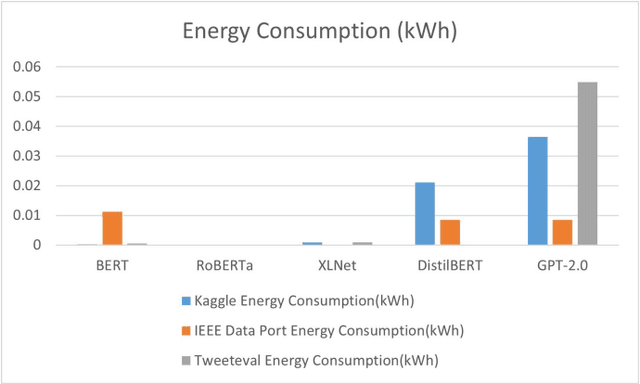
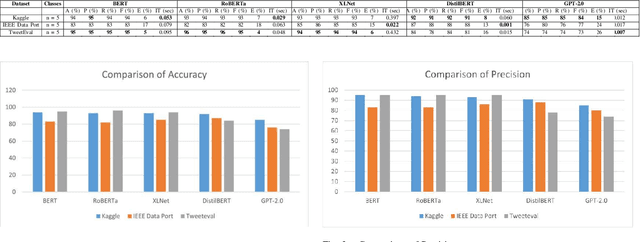
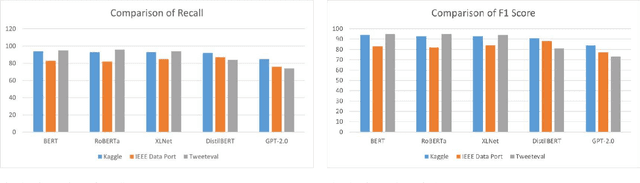
Cyberbullying significantly contributes to mental health issues in communities by negatively impacting the psychology of victims. It is a prevalent problem on social media platforms, necessitating effective, real-time detection and monitoring systems to identify harmful messages. However, current cyberbullying detection systems face challenges related to performance, dataset quality, time efficiency, and computational costs. This research aims to conduct a comparative study by adapting and evaluating existing text classification techniques within the cyberbullying detection domain. The study specifically evaluates the effectiveness and performance of these techniques in identifying cyberbullying instances on social media platforms. It focuses on leveraging and assessing large language models, including BERT, RoBERTa, XLNet, DistilBERT, and GPT-2.0, for their suitability in this domain. The results show that BERT strikes a balance between performance, time efficiency, and computational resources: Accuracy of 95%, Precision of 95%, Recall of 95%, F1 Score of 95%, Error Rate of 5%, Inference Time of 0.053 seconds, RAM Usage of 35.28 MB, CPU/GPU Usage of 0.4%, and Energy Consumption of 0.000263 kWh. The findings demonstrate that generative AI models, while powerful, do not consistently outperform fine-tuned models on the tested benchmarks. However, state-of-the-art performance can still be achieved through strategic adaptation and fine-tuning of existing models for specific datasets and tasks.
Blockchain-based Optimized Client Selection and Privacy Preserved Framework for Federated Learning
Jul 25, 2023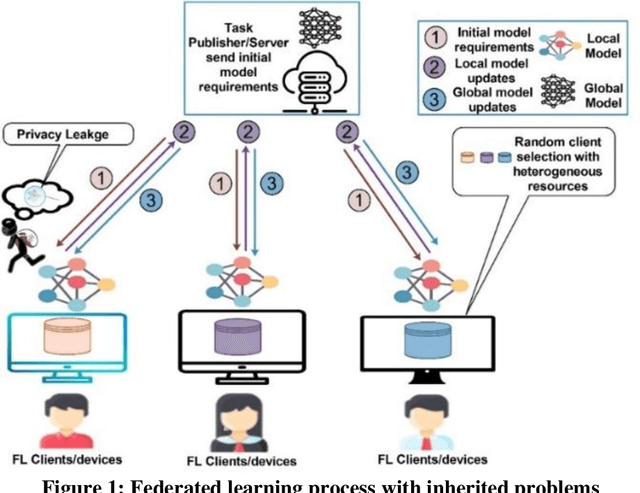

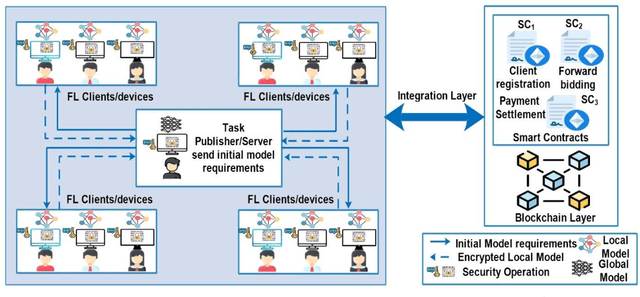
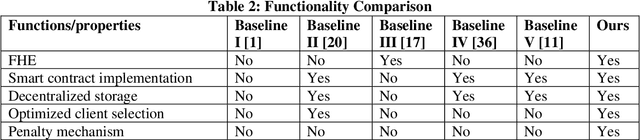
Federated learning is a distributed mechanism that trained large-scale neural network models with the participation of multiple clients and data remains on their devices, only sharing the local model updates. With this feature, federated learning is considered a secure solution for data privacy issues. However, the typical FL structure relies on the client-server, which leads to the single-point-of-failure (SPoF) attack, and the random selection of clients for model training compromised the model accuracy. Furthermore, adversaries try for inference attacks i.e., attack on privacy leads to gradient leakage attacks. We proposed the blockchain-based optimized client selection and privacy-preserved framework in this context. We designed the three kinds of smart contracts such as 1) registration of clients 2) forward bidding to select optimized clients for FL model training 3) payment settlement and reward smart contracts. Moreover, fully homomorphic encryption with Cheon, Kim, Kim, and Song (CKKS) method is implemented before transmitting the local model updates to the server. Finally, we evaluated our proposed method on the benchmark dataset and compared it with state-of-the-art studies. Consequently, we achieved a higher accuracy rate and privacy-preserved FL framework with decentralized nature.
Chatbots to ChatGPT in a Cybersecurity Space: Evolution, Vulnerabilities, Attacks, Challenges, and Future Recommendations
May 29, 2023



Chatbots shifted from rule-based to artificial intelligence techniques and gained traction in medicine, shopping, customer services, food delivery, education, and research. OpenAI developed ChatGPT blizzard on the Internet as it crossed one million users within five days of its launch. However, with the enhanced popularity, chatbots experienced cybersecurity threats and vulnerabilities. This paper discussed the relevant literature, reports, and explanatory incident attacks generated against chatbots. Our initial point is to explore the timeline of chatbots from ELIZA (an early natural language processing computer program) to GPT-4 and provide the working mechanism of ChatGPT. Subsequently, we explored the cybersecurity attacks and vulnerabilities in chatbots. Besides, we investigated the ChatGPT, specifically in the context of creating the malware code, phishing emails, undetectable zero-day attacks, and generation of macros and LOLBINs. Furthermore, the history of cyberattacks and vulnerabilities exploited by cybercriminals are discussed, particularly considering the risk and vulnerabilities in ChatGPT. Addressing these threats and vulnerabilities requires specific strategies and measures to reduce the harmful consequences. Therefore, the future directions to address the challenges were presented.
Challenges on Probabilistic Modeling for Evolving Networks
May 04, 2013With the emerging of new networks, such as wireless sensor networks, vehicle networks, P2P networks, cloud computing, mobile Internet, or social networks, the network dynamics and complexity expands from system design, hardware, software, protocols, structures, integration, evolution, application, even to business goals. Thus the dynamics and uncertainty are unavoidable characteristics, which come from the regular network evolution and unexpected hardware defects, unavoidable software errors, incomplete management information and dependency relationship between the entities among the emerging complex networks. Due to the complexity of emerging networks, it is not always possible to build precise models in modeling and optimization (local and global) for networks. This paper presents a survey on probabilistic modeling for evolving networks and identifies the new challenges which emerge on the probabilistic models and optimization strategies in the potential application areas of network performance, network management and network security for evolving networks.
Probabilistic Inferences in Bayesian Networks
Nov 05, 2010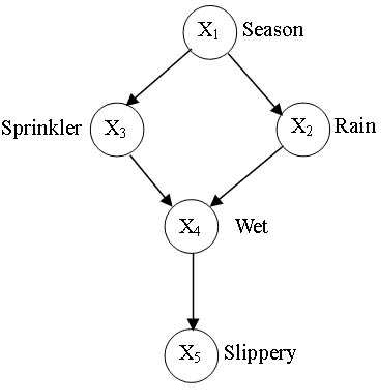
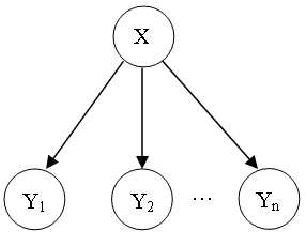
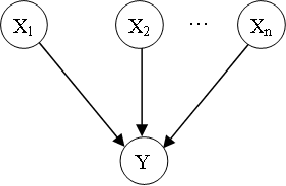
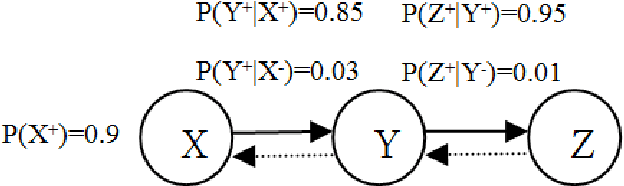
Bayesian network is a complete model for the variables and their relationships, it can be used to answer probabilistic queries about them. A Bayesian network can thus be considered a mechanism for automatically applying Bayes' theorem to complex problems. In the application of Bayesian networks, most of the work is related to probabilistic inferences. Any variable updating in any node of Bayesian networks might result in the evidence propagation across the Bayesian networks. This paper sums up various inference techniques in Bayesian networks and provide guidance for the algorithm calculation in probabilistic inference in Bayesian networks.