 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data Synthesis Method Driven by Large Language Models for Proactive Mining of Implicit User Intentions in Tourism
May 14, 2025



In the tourism domain, Large Language Models (LLMs) often struggle to mine implicit user intentions from tourists' ambiguous inquiries and lack the capacity to proactively guide users toward clarifying their needs. A critical bottleneck is the scarcity of high-quality training datasets that facilitate proactive questioning and implicit intention mining. While recent advances leverage LLM-driven data synthesis to generate such datasets and transfer specialized knowledge to downstream models, existing approaches suffer from several shortcomings: (1) lack of adaptation to the tourism domain, (2) skewed distributions of detail levels in initial inquiries, (3) contextual redundancy in the implicit intention mining module, and (4) lack of explicit thinking about tourists' emotions and intention values. Therefore, we propose SynPT (A Data Synthesis Method Driven by LLMs for Proactive Mining of Implicit User Intentions in the Tourism), which constructs an LLM-driven user agent and assistant agent to simulate dialogues based on seed data collected from Chinese tourism websites. This approach addresses the aforementioned limitations and generates SynPT-Dialog, a training dataset containing explicit reasoning. The dataset is utilized to fine-tune a general LLM, enabling it to proactively mine implicit user intentions. Experimental evaluations, conducted from both human and LLM perspectives, demonstrate the superiority of SynPT compared to existing methods. Furthermore, we analyze key hyperparameters and present case studies to illustrate the practical applicability of our method, including discussions on its adaptability to English-language scenarios. All code and data are publicly available.
Language-assisted Vision Model Debugger: A Sample-Free Approach to Finding Bugs
Dec 09, 2023Vision models with high overall accuracy often exhibit systematic errors in specific scenarios, posing potential serious safety concerns. Diagnosing bugs of vision models is gaining increased attention, however traditional diagnostic approaches require annotation efforts (\eg rich metadata accompanying each samples of CelebA). To address this issue,We propose a language-assisted diagnostic method that uses texts instead of images to diagnose bugs in vision models based on multi-modal models (\eg CLIP). Our approach connects the embedding space of CLIP with the buggy vision model to be diagnosed; meanwhile, utilizing a shared classifier and the cross-modal transferability of embedding space from CLIP, the text-branch of CLIP become a proxy model to find bugs in the buggy model. The proxy model can classify texts paired with images. During the diagnosis, a Large Language Model (LLM) is employed to obtain task-relevant corpora, and this corpora is used to extract keywords. Descriptions constructed with templates containing these keywords serve as input text to probe errors in the proxy model. Finally, we validate the ability to diagnose existing visual models using language on the Waterbirds and CelebA datasets, we can identify bugs comprehensible to human experts, uncovering not only known bugs but also previously unknown ones.
A Multi-Task Deep Learning Approach for Sensor-based Human Activity Recognition and Segmentation
Mar 20, 2023



Sensor-based human activity segmentation and recognition are two important and challenging problems in many real-world applications and they have drawn increasing attention from the deep learning community in recent years. Most of the existing deep learning works were designed based on pre-segmented sensor streams and they have treated activity segmentation and recognition as two separate tasks. In practice, performing data stream segmentation is very challenging. We believe that both activity segmentation and recognition may convey unique information which can complement each other to improve the performance of the two tasks. In this paper, we firstly proposes a new multitask deep neural network to solve the two tasks simultaneously. The proposed neural network adopts selective convolution and features multiscale windows to segment activities of long or short time durations. First, multiple windows of different scales are generated to center on each unit of the feature sequence. Then, the model is trained to predict, for each window, the activity class and the offset to the true activity boundaries. Finally, overlapping windows are filtered out by non-maximum suppression, and adjacent windows of the same activity are concatenated to complete the segmentation task. Extensive experiments were conducted on eight popular benchmarking datasets, and the results show that our proposed method outperforms the state-of-the-art methods both for activity recognition and segmentation.
Negative Selection by Clustering for Contrastive Learning in Human Activity Recognition
Mar 23, 2022
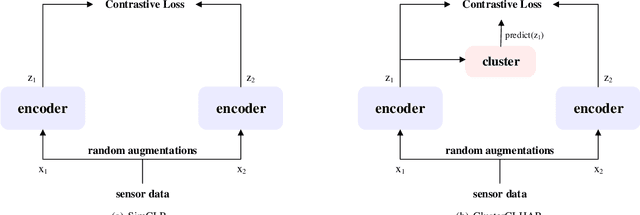
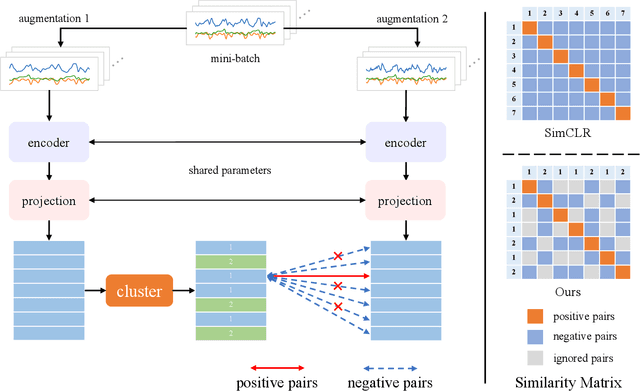
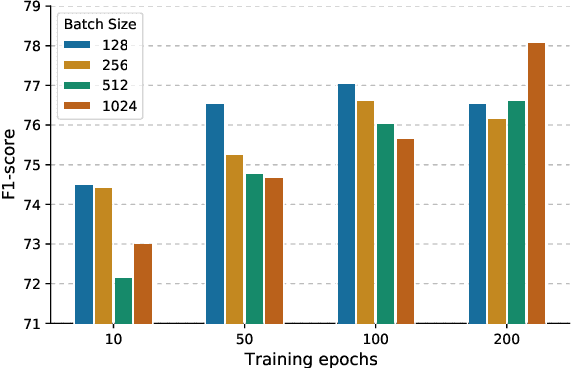
Contrastive learning has been applied to Human Activity Recognition (HAR) based on sensor data owing to its ability to achieve performance comparable to supervised learning with a large amount of unlabeled data and a small amount of labeled data. The pre-training task for contrastive learning is generally instance discrimination, which specifies that each instance belongs to a single class, but this will consider the same class of samples as negative examples. Such a pre-training task is not conducive to human activity recognition tasks, which are mainly classification tasks. To address this problem, we follow SimCLR to propose a new contrastive learning framework that negative selection by clustering in HAR, which is called ClusterCLHAR. Compared with SimCLR, it redefines the negative pairs in the contrastive loss function by using unsupervised clustering methods to generate soft labels that mask other samples of the same cluster to avoid regarding them as negative samples. We evaluate ClusterCLHAR on three benchmark datasets, USC-HAD, MotionSense, and UCI-HAR, using mean F1-score as the evaluation metric. The experiment results show that it outperforms all the state-of-the-art methods applied to HAR in self-supervised learning and semi-supervised learning.
Understanding and Testing Generalization of Deep Networks on Out-of-Distribution Data
Nov 19, 2021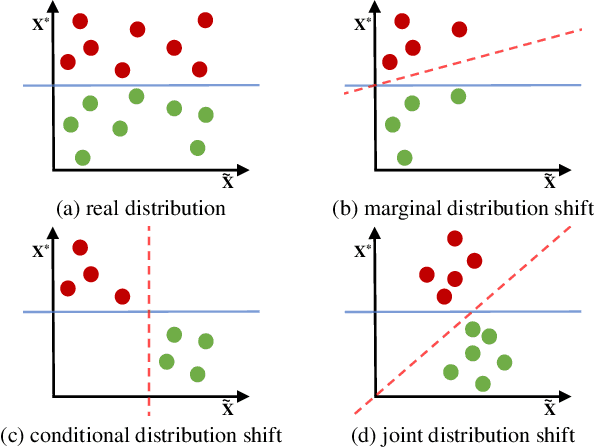
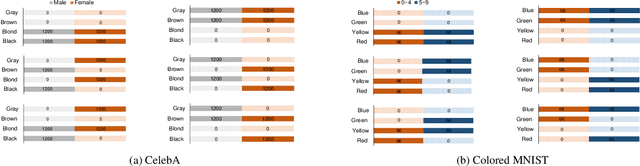


Deep network models perform excellently on In-Distribution (ID) data, but can significantly fail on Out-Of-Distribution (OOD) data. While developing methods focus on improving OOD generalization, few attention has been paid to evaluating the capability of models to handle OOD data. This study is devoted to analyzing the problem of experimental ID test and designing OOD test paradigm to accurately evaluate the practical performance. Our analysis is based on an introduced categorization of three types of distribution shifts to generate OOD data. Main observations include: (1) ID test fails in neither reflecting the actual performance of a single model nor comparing between different models under OOD data. (2) The ID test failure can be ascribed to the learned marginal and conditional spurious correlations resulted from the corresponding distribution shifts. Based on this, we propose novel OOD test paradigms to evaluate the generalization capacity of models to unseen data, and discuss how to use OOD test results to find bugs of models to guide model debugging.
Sensor Data Augmentation with Resampling for Contrastive Learning in Human Activity Recognition
Sep 05, 2021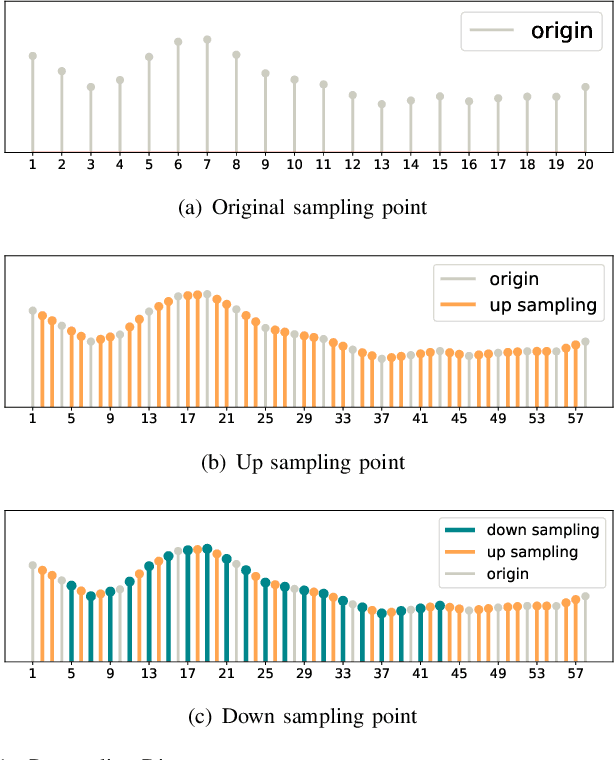
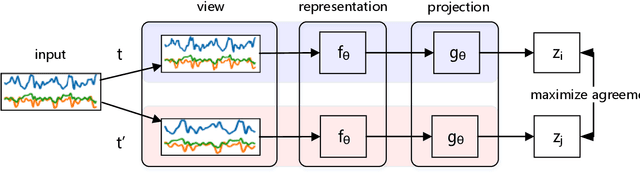
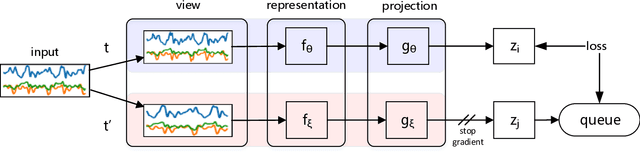
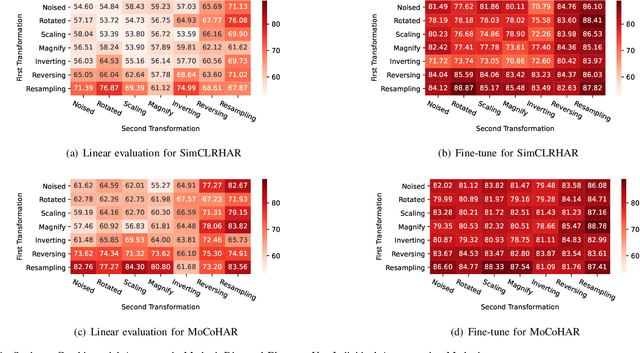
Human activity recognition plays an increasingly important role not only in our daily lives, but also in the medical and rehabilitation fields. The development of deep learning has also contributed to the advancement of human activity recognition, but the large amount of data annotation work required to train deep learning models is a major obstacle to the development of human activity recognition. Contrastive learning has started to be used in the field of sensor-based human activity recognition due to its ability to avoid the cost of labeling large datasets and its ability to better distinguish between sample representations of different instances. Among them, data augmentation, an important part of contrast learning, has a significant impact on model effectiveness, but current data augmentation methods do not perform too successfully in contrast learning frameworks for wearable sensor-based activity recognition. To optimize the effect of contrast learning models, in this paper, we investigate the sampling frequency of sensors and propose a resampling data augmentation method. In addition, we also propose a contrast learning framework based on human activity recognition and apply the resampling augmentation method to the data augmentation phase of contrast learning. The experimental results show that the resampling augmentation method outperforms supervised learning by 9.88% on UCI HAR and 7.69% on Motion Sensor in the fine-tuning evaluation of contrast learning with a small amount of labeled data, and also reveal that not all data augmentation methods will have positive effects in the contrast learning framework. Finally, we explored the influence of the combination of different augmentation methods on contrastive learning, and the experimental results showed that the effect of most combination augmentation methods was better than that of single augmentation.