 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Testing Generalization of Deep Networks on Out-of-Distribution Data
Paper and Code
Nov 19, 2021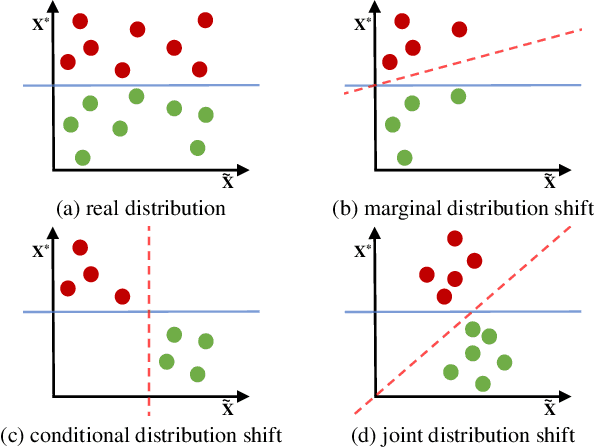
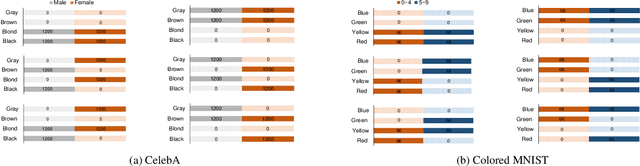


Deep network models perform excellently on In-Distribution (ID) data, but can significantly fail on Out-Of-Distribution (OOD) data. While developing methods focus on improving OOD generalization, few attention has been paid to evaluating the capability of models to handle OOD data. This study is devoted to analyzing the problem of experimental ID test and designing OOD test paradigm to accurately evaluate the practical performance. Our analysis is based on an introduced categorization of three types of distribution shifts to generate OOD data. Main observations include: (1) ID test fails in neither reflecting the actual performance of a single model nor comparing between different models under OOD data. (2) The ID test failure can be ascribed to the learned marginal and conditional spurious correlations resulted from the corresponding distribution shifts. Based on this, we propose novel OOD test paradigms to evaluate the generalization capacity of models to unseen data, and discuss how to use OOD test results to find bugs of models to guide model debugging.