 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Onto-Relational-Sophic Framework for Governing Synthetic Minds
Mar 19, 2026The rapid evolution of artificial intelligence, from task-specific systems to foundation models exhibiting broad, flexible competence across reasoning, creative synthesis, and social interaction, has outpaced the conceptual and governance frameworks designed to manage it. Current regulatory paradigms, anchored in a tool-centric worldview, address algorithmic bias and transparency but leave unanswered foundational questions about what increasingly capable synthetic minds are, how societies should relate to them, and the normative principles that should guide their development. Here we introduce the Onto-Relational-Sophic (ORS) framework, grounded in Cyberism philosophy, which offers integrated answers to these challenges through three pillars: (1) a Cyber-Physical-Social-Thinking (CPST) ontology that defines the mode of being for synthetic minds as irreducibly multi-dimensional rather than purely computational; (2) a graded spectrum of digital personhood providing a pragmatic relational taxonomy beyond binary person-or-tool classifications; and (3) Cybersophy, a wisdom-oriented axiology synthesizing virtue ethics, consequentialism, and relational approaches to guide governance. We apply the framework to emergent scenarios including autonomous research agents, AI-mediated healthcare, and agentic AI ecosystems, demonstrating its capacity to generate proportionate, adaptive governance recommendations. The ORS framework charts a path from narrow technical alignment toward comprehensive philosophical foundations for the synthetic minds already among us.
IMOVNO+: A Regional Partitioning and Meta-Heuristic Ensemble Framework for Imbalanced Multi-Class Learning
Feb 22, 2026Class imbalance, overlap, and noise degrade data quality, reduce model reliability, and limit generalization. Although widely studied in binary classification, these issues remain underexplored in multi-class settings, where complex inter-class relationships make minority-majority structures unclear and traditional clustering fails to capture distribution shape. Approaches that rely only on geometric distances risk removing informative samples and generating low-quality synthetic data, while binarization approaches treat imbalance locally and ignore global inter-class dependencies. At the algorithmic level, ensembles struggle to integrate weak classifiers, leading to limited robustness. This paper proposes IMOVNO+ (IMbalance-OVerlap-NOise+ Algorithm-Level Optimization), a two-level framework designed to jointly enhance data quality and algorithmic robustness for binary and multi-class tasks. At the data level, first, conditional probability is used to quantify the informativeness of each sample. Second, the dataset is partitioned into core, overlapping, and noisy regions. Third, an overlapping-cleaning algorithm is introduced that combines Z-score metrics with a big-jump gap distance. Fourth, a smart oversampling algorithm based on multi-regularization controls synthetic sample proximity, preventing new overlaps. At the algorithmic level, a meta-heuristic prunes ensemble classifiers to reduce weak-learner influence. IMOVNO+ was evaluated on 35 datasets (13 multi-class, 22 binary). Results show consistent superiority over state-of-the-art methods, approaching 100% in several cases. For multi-class data, IMOVNO+ achieves gains of 37-57% in G-mean, 25-44% in F1-score, 25-39% in precision, and 26-43% in recall. In binary tasks, it attains near-perfect performance with improvements of 14-39%. The framework handles data scarcity and imbalance from collection and privacy limits.
A Data Synthesis Method Driven by Large Language Models for Proactive Mining of Implicit User Intentions in Tourism
May 14, 2025



In the tourism domain, Large Language Models (LLMs) often struggle to mine implicit user intentions from tourists' ambiguous inquiries and lack the capacity to proactively guide users toward clarifying their needs. A critical bottleneck is the scarcity of high-quality training datasets that facilitate proactive questioning and implicit intention mining. While recent advances leverage LLM-driven data synthesis to generate such datasets and transfer specialized knowledge to downstream models, existing approaches suffer from several shortcomings: (1) lack of adaptation to the tourism domain, (2) skewed distributions of detail levels in initial inquiries, (3) contextual redundancy in the implicit intention mining module, and (4) lack of explicit thinking about tourists' emotions and intention values. Therefore, we propose SynPT (A Data Synthesis Method Driven by LLMs for Proactive Mining of Implicit User Intentions in the Tourism), which constructs an LLM-driven user agent and assistant agent to simulate dialogues based on seed data collected from Chinese tourism websites. This approach addresses the aforementioned limitations and generates SynPT-Dialog, a training dataset containing explicit reasoning. The dataset is utilized to fine-tune a general LLM, enabling it to proactively mine implicit user intentions. Experimental evaluations, conducted from both human and LLM perspectives, demonstrate the superiority of SynPT compared to existing methods. Furthermore, we analyze key hyperparameters and present case studies to illustrate the practical applicability of our method, including discussions on its adaptability to English-language scenarios. All code and data are publicly available.
LayoutCoT: Unleashing the Deep Reasoning Potential of Large Language Models for Layout Generation
Apr 15, 2025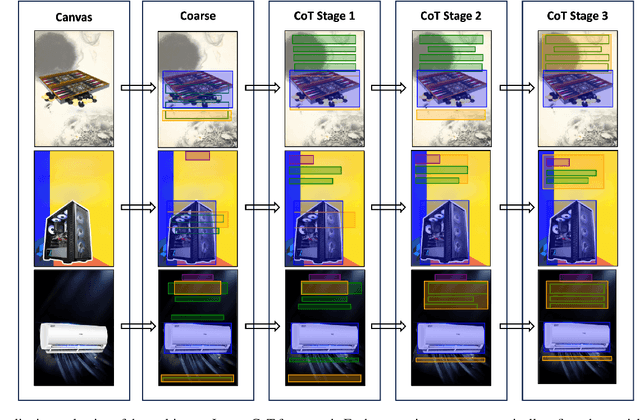
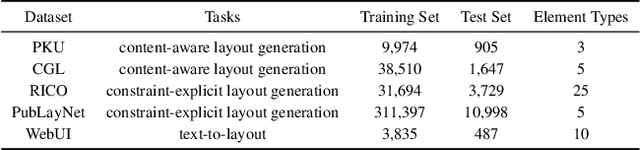
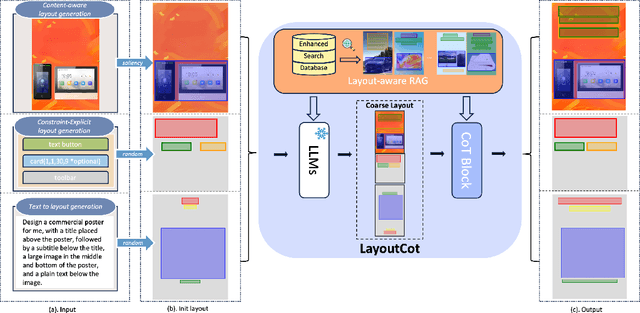
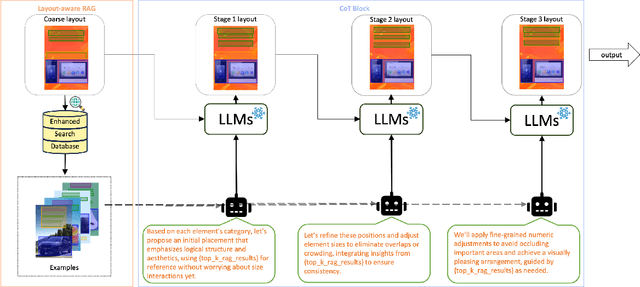
Conditional layout generation aims to automatically generate visually appealing and semantically coherent layouts from user-defined constraints. While recent methods based on generative models have shown promising results, they typically require substantial amounts of training data or extensive fine-tuning, limiting their versatility and practical applicability. Alternatively, some training-free approaches leveraging in-context learning with Large Language Models (LLMs) have emerged, but they often suffer from limited reasoning capabilities and overly simplistic ranking mechanisms, which restrict their ability to generate consistently high-quality layouts. To this end, we propose LayoutCoT, a novel approach that leverages the reasoning capabilities of LLMs through a combination of Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) techniques. Specifically, LayoutCoT transforms layout representations into a standardized serialized format suitable for processing by LLMs. A Layout-aware RAG is used to facilitate effective retrieval and generate a coarse layout by LLMs. This preliminary layout, together with the selected exemplars, is then fed into a specially designed CoT reasoning module for iterative refinement, significantly enhancing both semantic coherence and visual quality. We conduct extensive experiments on five public datasets spanning three conditional layout generation tasks. Experimental results demonstrate that LayoutCoT achieves state-of-the-art performance without requiring training or fine-tuning. Notably, our CoT reasoning module enables standard LLMs, even those without explicit deep reasoning abilities, to outperform specialized deep-reasoning models such as deepseek-R1, highlighting the potential of our approach in unleashing the deep reasoning capabilities of LLMs for layout generation tasks.
A Novel Double Pruning method for Imbalanced Data using Information Entropy and Roulette Wheel Selection for Breast Cancer Diagnosis
Mar 15, 2025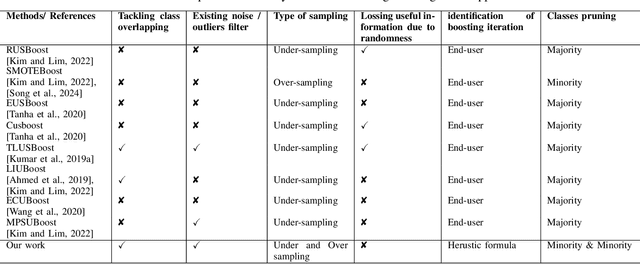
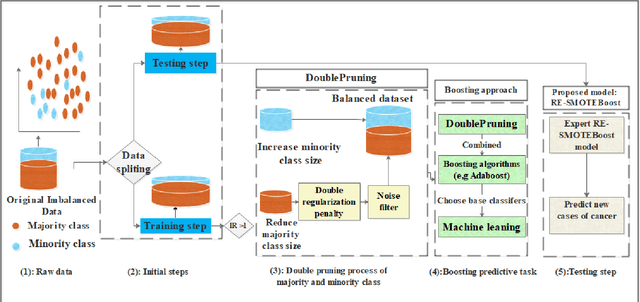

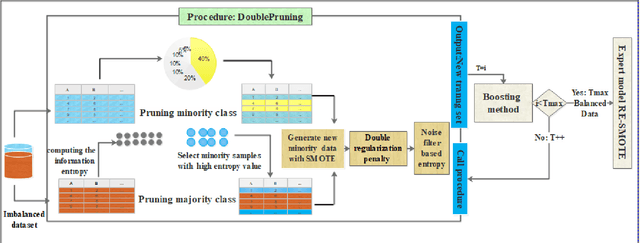
Accurate illness diagnosis is vital for effective treatment and patient safety. Machine learning models are widely used for cancer diagnosis based on historical medical data. However, data imbalance remains a major challenge, leading to hindering classifier performance and reliability. The SMOTEBoost method addresses this issue by generating synthetic data to balance the dataset, but it may overlook crucial overlapping regions near the decision boundary and can produce noisy samples. This paper proposes RE-SMOTEBoost, an enhanced version of SMOTEBoost, designed to overcome these limitations. Firstly, RE-SMOTEBoost focuses on generating synthetic samples in overlapping regions to better capture the decision boundary using roulette wheel selection. Secondly, it incorporates a filtering mechanism based on information entropy to reduce noise, and borderline cases and improve the quality of generated data. Thirdly, we introduce a double regularization penalty to control the synthetic samples proximity to the decision boundary and avoid class overlap. These enhancements enable higher-quality oversampling of the minority class, resulting in a more balanced and effective training dataset. The proposed method outperforms existing state-of-the-art techniques when evaluated on imbalanced datasets. Compared to the top-performing sampling algorithms, RE-SMOTEBoost demonstrates a notable improvement of 3.22\% in accuracy and a variance reduction of 88.8\%. These results indicate that the proposed model offers a solid solution for medical settings, effectively overcoming data scarcity and severe imbalance caused by limited samples, data collection difficulties, and privacy constraints.
PTMs-TSCIL Pre-Trained Models Based Class-Incremental Learning
Mar 10, 2025Class-incremental learning (CIL) for time series data faces critical challenges in balancing stability against catastrophic forgetting and plasticity for new knowledge acquisition, particularly under real-world constraints where historical data access is restricted. While pre-trained models (PTMs) have shown promise in CIL for vision and NLP domains, their potential in time series class-incremental learning (TSCIL) remains underexplored due to the scarcity of large-scale time series pre-trained models. Prompted by the recent emergence of large-scale pre-trained models (PTMs) for time series data, we present the first exploration of PTM-based Time Series Class-Incremental Learning (TSCIL). Our approach leverages frozen PTM backbones coupled with incrementally tuning the shared adapter, preserving generalization capabilities while mitigating feature drift through knowledge distillation. Furthermore, we introduce a Feature Drift Compensation Network (DCN), designed with a novel two-stage training strategy to precisely model feature space transformations across incremental tasks. This allows for accurate projection of old class prototypes into the new feature space. By employing DCN-corrected prototypes, we effectively enhance the unified classifier retraining, mitigating model feature drift and alleviating catastrophic forgetting. Extensive experiments on five real-world datasets demonstrate state-of-the-art performance, with our method yielding final accuracy gains of 1.4%-6.1% across all datasets compared to existing PTM-based approaches. Our work establishes a new paradigm for TSCIL, providing insights into stability-plasticity optimization for continual learning systems.
Assessing Text Classification Methods for Cyberbullying Detection on Social Media Platforms
Dec 27, 2024
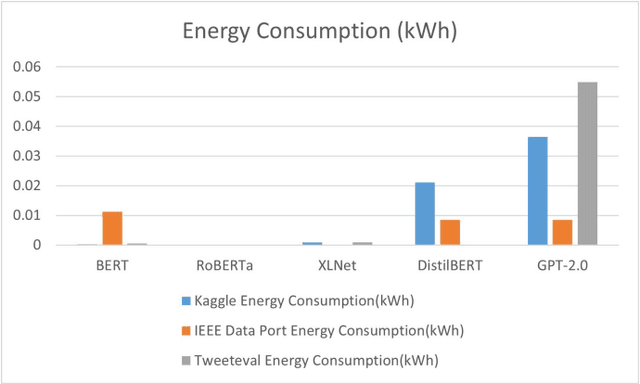
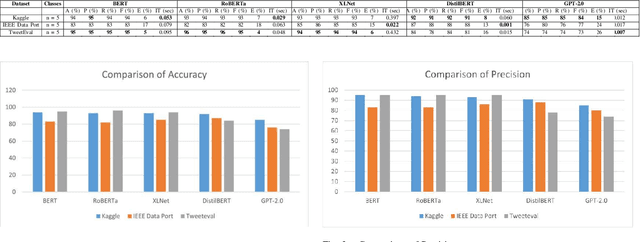
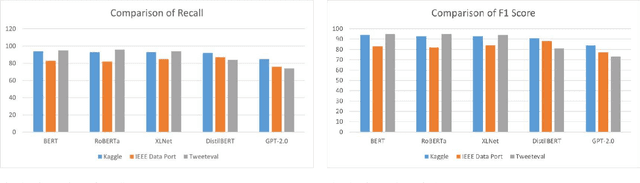
Cyberbullying significantly contributes to mental health issues in communities by negatively impacting the psychology of victims. It is a prevalent problem on social media platforms, necessitating effective, real-time detection and monitoring systems to identify harmful messages. However, current cyberbullying detection systems face challenges related to performance, dataset quality, time efficiency, and computational costs. This research aims to conduct a comparative study by adapting and evaluating existing text classification techniques within the cyberbullying detection domain. The study specifically evaluates the effectiveness and performance of these techniques in identifying cyberbullying instances on social media platforms. It focuses on leveraging and assessing large language models, including BERT, RoBERTa, XLNet, DistilBERT, and GPT-2.0, for their suitability in this domain. The results show that BERT strikes a balance between performance, time efficiency, and computational resources: Accuracy of 95%, Precision of 95%, Recall of 95%, F1 Score of 95%, Error Rate of 5%, Inference Time of 0.053 seconds, RAM Usage of 35.28 MB, CPU/GPU Usage of 0.4%, and Energy Consumption of 0.000263 kWh. The findings demonstrate that generative AI models, while powerful, do not consistently outperform fine-tuned models on the tested benchmarks. However, state-of-the-art performance can still be achieved through strategic adaptation and fine-tuning of existing models for specific datasets and tasks.
ReLU-KAN: New Kolmogorov-Arnold Networks that Only Need Matrix Addition, Dot Multiplication, and ReLU
Jun 04, 2024

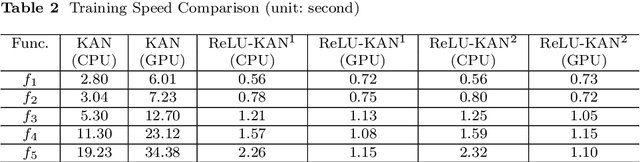
Limited by the complexity of basis function (B-spline) calculations, Kolmogorov-Arnold Networks (KAN) suffer from restricted parallel computing capability on GPUs. This paper proposes a novel ReLU-KAN implementation that inherits the core idea of KAN. By adopting ReLU (Rectified Linear Unit) and point-wise multiplication, we simplify the design of KAN's basis function and optimize the computation process for efficient CUDA computing. The proposed ReLU-KAN architecture can be readily implemented on existing deep learning frameworks (e.g., PyTorch) for both inference and training. Experimental results demonstrate that ReLU-KAN achieves a 20x speedup compared to traditional KAN with 4-layer networks. Furthermore, ReLU-KAN exhibits a more stable training process with superior fitting ability while preserving the "catastrophic forgetting avoidance" property of KAN. You can get the code in https://github.com/quiqi/relu_kan
Social Force Embedded Mixed Graph Convolutional Network for Multi-class Trajectory Prediction
Apr 20, 2024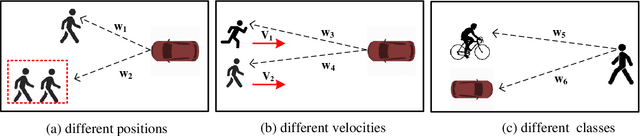
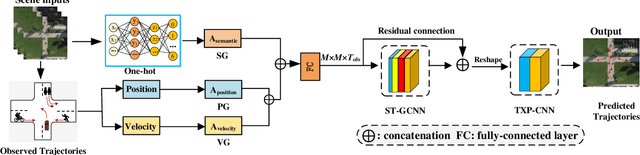
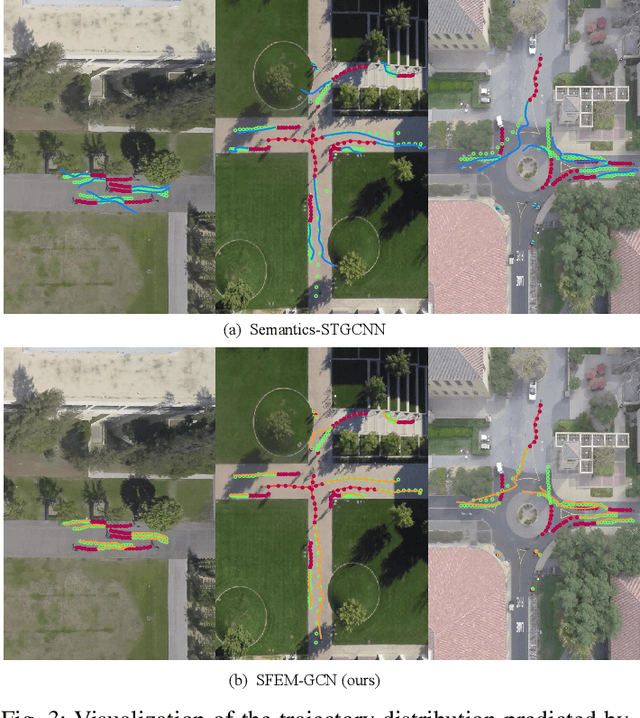

Accurate prediction of agent motion trajectories is crucial for autonomous driving, contributing to the reduction of collision risks in human-vehicle interactions and ensuring ample response time for other traffic participants. Current research predominantly focuses on traditional deep learning methods, including convolutional neural networks (CNNs) and recurrent neural networks (RNNs). These methods leverage relative distances to forecast the motion trajectories of a single class of agents. However, in complex traffic scenarios, the motion patterns of various types of traffic participants exhibit inherent randomness and uncertainty. Relying solely on relative distances may not adequately capture the nuanced interaction patterns between different classes of road users. In this paper, we propose a novel multi-class trajectory prediction method named the social force embedded mixed graph convolutional network (SFEM-GCN). SFEM-GCN comprises three graph topologies: the semantic graph (SG), position graph (PG), and velocity graph (VG). These graphs encode various of social force relationships among different classes of agents in complex scenes. Specifically, SG utilizes one-hot encoding of agent-class information to guide the construction of graph adjacency matrices based on semantic information. PG and VG create adjacency matrices to capture motion interaction relationships between different classes agents. These graph structures are then integrated into a mixed graph, where learning is conducted using a spatiotemporal graph convolutional neural network (ST-GCNN). To further enhance prediction performance, we adopt temporal convolutional networks (TCNs) to generate the predicted trajectory with fewer parameters. Experimental results on publicly available datasets demonstrate that SFEM-GCN surpasses state-of-the-art methods in terms of accuracy and robustness.
Evaluation of Machine Translation Based on Semantic Dependencies and Keywords
Apr 20, 2024



In view of the fact that most of the existing machine translation evaluation algorithms only consider the lexical and syntactic information, but ignore the deep semantic information contained in the sentence, this paper proposes a computational method for evaluating the semantic correctness of machine translations based on reference translations and incorporating semantic dependencies and sentence keyword information. Use the language technology platform developed by the Social Computing and Information Retrieval Research Center of Harbin Institute of Technology to conduct semantic dependency analysis and keyword analysis on sentences, and obtain semantic dependency graphs, keywords, and weight information corresponding to keywords. It includes all word information with semantic dependencies in the sentence and keyword information that affects semantic information. Construct semantic association pairs including word and dependency multi-features. The key semantics of the sentence cannot be highlighted in the semantic information extracted through semantic dependence, resulting in vague semantics analysis. Therefore, the sentence keyword information is also included in the scope of machine translation semantic evaluation. To achieve a comprehensive and in-depth evaluation of the semantic correctness of sentences, the experimental results show that the accuracy of the evaluation algorithm has been improved compared with similar methods, and it can more accurately measure the semantic correctness of machine translation.