 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Double Pruning method for Imbalanced Data using Information Entropy and Roulette Wheel Selection for Breast Cancer Diagnosis
Mar 15, 2025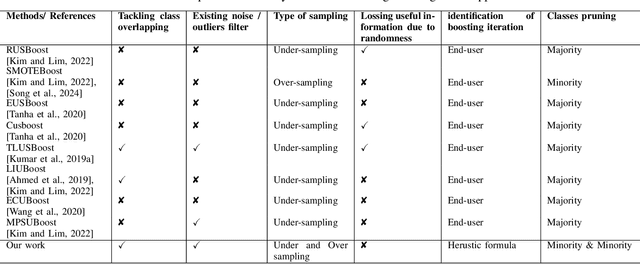
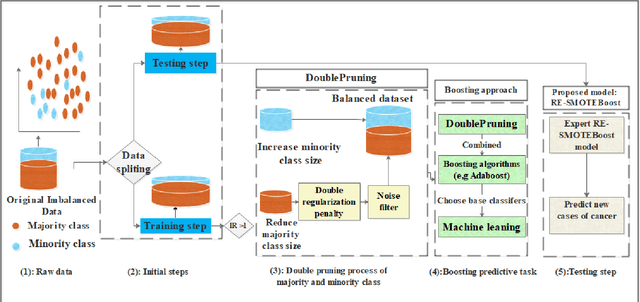

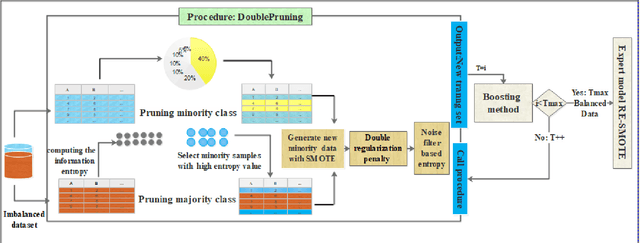
Accurate illness diagnosis is vital for effective treatment and patient safety. Machine learning models are widely used for cancer diagnosis based on historical medical data. However, data imbalance remains a major challenge, leading to hindering classifier performance and reliability. The SMOTEBoost method addresses this issue by generating synthetic data to balance the dataset, but it may overlook crucial overlapping regions near the decision boundary and can produce noisy samples. This paper proposes RE-SMOTEBoost, an enhanced version of SMOTEBoost, designed to overcome these limitations. Firstly, RE-SMOTEBoost focuses on generating synthetic samples in overlapping regions to better capture the decision boundary using roulette wheel selection. Secondly, it incorporates a filtering mechanism based on information entropy to reduce noise, and borderline cases and improve the quality of generated data. Thirdly, we introduce a double regularization penalty to control the synthetic samples proximity to the decision boundary and avoid class overlap. These enhancements enable higher-quality oversampling of the minority class, resulting in a more balanced and effective training dataset. The proposed method outperforms existing state-of-the-art techniques when evaluated on imbalanced datasets. Compared to the top-performing sampling algorithms, RE-SMOTEBoost demonstrates a notable improvement of 3.22\% in accuracy and a variance reduction of 88.8\%. These results indicate that the proposed model offers a solid solution for medical settings, effectively overcoming data scarcity and severe imbalance caused by limited samples, data collection difficulties, and privacy constraints.