 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Discovery for Cross-Sectional Data Based on Super-Structure and Divide-and-Conquer
Feb 03, 2026This paper tackles a critical bottleneck in Super-Structure-based divide-and-conquer causal discovery: the high computational cost of constructing accurate Super-Structures--particularly when conditional independence (CI) tests are expensive and domain knowledge is unavailable. We propose a novel, lightweight framework that relaxes the strict requirements on Super-Structure construction while preserving the algorithmic benefits of divide-and-conquer. By integrating weakly constrained Super-Structures with efficient graph partitioning and merging strategies, our approach substantially lowers CI test overhead without sacrificing accuracy. We instantiate the framework in a concrete causal discovery algorithm and rigorously evaluate its components on synthetic data. Comprehensive experiments on Gaussian Bayesian networks, including magic-NIAB, ECOLI70, and magic-IRRI, demonstrate that our method matches or closely approximates the structural accuracy of PC and FCI while drastically reducing the number of CI tests. Further validation on the real-world China Health and Retirement Longitudinal Study (CHARLS) dataset confirms its practical applicability. Our results establish that accurate, scalable causal discovery is achievable even under minimal assumptions about the initial Super-Structure, opening new avenues for applying divide-and-conquer methods to large-scale, knowledge-scarce domains such as biomedical and social science research.
HAR-DoReMi: Optimizing Data Mixture for Self-Supervised Human Activity Recognition Across Heterogeneous IMU Datasets
Mar 16, 2025Cross-dataset Human Activity Recognition (HAR) suffers from limited model generalization, hindering its practical deployment. To address this critical challenge, inspired by the success of DoReMi in Large Language Models (LLMs), we introduce a data mixture optimization strategy for pre-training HAR models, aiming to improve the recognition performance across heterogeneous datasets. However, directly applying DoReMi to the HAR field encounters new challenges due to the continuous, multi-channel and intrinsic heterogeneous characteristics of IMU sensor data. To overcome these limitations, we propose a novel framework HAR-DoReMi, which introduces a masked reconstruction task based on Mean Squared Error (MSE) loss. By raplacing the discrete language sequence prediction task, which relies on the Negative Log-Likelihood (NLL) loss, in the original DoReMi framework, the proposed framework is inherently more appropriate for handling the continuous and multi-channel characteristics of IMU data. In addition, HAR-DoReMi integrates the Mahony fusion algorithm into the self-supervised HAR pre-training, aiming to mitigate the heterogeneity of varying sensor orientation. This is achieved by estimating the sensor orientation within each dataset and facilitating alignment with a unified coordinate system, thereby improving the cross-dataset generalization ability of the HAR model. Experimental evaluation on multiple cross-dataset HAR transfer tasks demonstrates that HAR-DoReMi improves the accuracy by an average of 6.51%, compared to the current state-of-the-art method with only approximately 30% to 50% of the data usage. These results confirm the effectiveness of HAR-DoReMi in improving the generalization and data efficiency of pre-training HAR models, underscoring its significant potential to facilitate the practical deployment of HAR technology.
PTMs-TSCIL Pre-Trained Models Based Class-Incremental Learning
Mar 10, 2025Class-incremental learning (CIL) for time series data faces critical challenges in balancing stability against catastrophic forgetting and plasticity for new knowledge acquisition, particularly under real-world constraints where historical data access is restricted. While pre-trained models (PTMs) have shown promise in CIL for vision and NLP domains, their potential in time series class-incremental learning (TSCIL) remains underexplored due to the scarcity of large-scale time series pre-trained models. Prompted by the recent emergence of large-scale pre-trained models (PTMs) for time series data, we present the first exploration of PTM-based Time Series Class-Incremental Learning (TSCIL). Our approach leverages frozen PTM backbones coupled with incrementally tuning the shared adapter, preserving generalization capabilities while mitigating feature drift through knowledge distillation. Furthermore, we introduce a Feature Drift Compensation Network (DCN), designed with a novel two-stage training strategy to precisely model feature space transformations across incremental tasks. This allows for accurate projection of old class prototypes into the new feature space. By employing DCN-corrected prototypes, we effectively enhance the unified classifier retraining, mitigating model feature drift and alleviating catastrophic forgetting. Extensive experiments on five real-world datasets demonstrate state-of-the-art performance, with our method yielding final accuracy gains of 1.4%-6.1% across all datasets compared to existing PTM-based approaches. Our work establishes a new paradigm for TSCIL, providing insights into stability-plasticity optimization for continual learning systems.
HARMamba: Efficient Wearable Sensor Human Activity Recognition Based on Bidirectional Selective SSM
Mar 29, 2024



Wearable sensor human activity recognition (HAR) is a crucial area of research in activity sensing. While transformer-based temporal deep learning models have been extensively studied and implemented, their large number of parameters present significant challenges in terms of system computing load and memory usage, rendering them unsuitable for real-time mobile activity recognition applications. Recently, an efficient hardware-aware state space model (SSM) called Mamba has emerged as a promising alternative. Mamba demonstrates strong potential in long sequence modeling, boasts a simpler network architecture, and offers an efficient hardware-aware design. Leveraging SSM for activity recognition represents an appealing avenue for exploration. In this study, we introduce HARMamba, which employs a more lightweight selective SSM as the foundational model architecture for activity recognition. The goal is to address the computational resource constraints encountered in real-time activity recognition scenarios. Our approach involves processing sensor data flow by independently learning each channel and segmenting the data into "patches". The marked sensor sequence's position embedding serves as the input token for the bidirectional state space model, ultimately leading to activity categorization through the classification head. Compared to established activity recognition frameworks like Transformer-based models, HARMamba achieves superior performance while also reducing computational and memory overhead. Furthermore, our proposed method has been extensively tested on four public activity datasets: PAMAP2, WISDM, UNIMIB, and UCI, demonstrating impressive performance in activity recognition tasks.
MCformer: Multivariate Time Series Forecasting with Mixed-Channels Transformer
Mar 14, 2024



The massive generation of time-series data by largescale Internet of Things (IoT) devices necessitates the exploration of more effective models for multivariate time-series forecasting. In previous models, there was a predominant use of the Channel Dependence (CD) strategy (where each channel represents a univariate sequence). Current state-of-the-art (SOTA) models primarily rely on the Channel Independence (CI) strategy. The CI strategy treats all channels as a single channel, expanding the dataset to improve generalization performance and avoiding inter-channel correlation that disrupts long-term features. However, the CI strategy faces the challenge of interchannel correlation forgetting. To address this issue, we propose an innovative Mixed Channels strategy, combining the data expansion advantages of the CI strategy with the ability to counteract inter-channel correlation forgetting. Based on this strategy, we introduce MCformer, a multivariate time-series forecasting model with mixed channel features. The model blends a specific number of channels, leveraging an attention mechanism to effectively capture inter-channel correlation information when modeling long-term features. Experimental results demonstrate that the Mixed Channels strategy outperforms pure CI strategy in multivariate time-series forecasting tasks.
A Multi-Task Deep Learning Approach for Sensor-based Human Activity Recognition and Segmentation
Mar 20, 2023



Sensor-based human activity segmentation and recognition are two important and challenging problems in many real-world applications and they have drawn increasing attention from the deep learning community in recent years. Most of the existing deep learning works were designed based on pre-segmented sensor streams and they have treated activity segmentation and recognition as two separate tasks. In practice, performing data stream segmentation is very challenging. We believe that both activity segmentation and recognition may convey unique information which can complement each other to improve the performance of the two tasks. In this paper, we firstly proposes a new multitask deep neural network to solve the two tasks simultaneously. The proposed neural network adopts selective convolution and features multiscale windows to segment activities of long or short time durations. First, multiple windows of different scales are generated to center on each unit of the feature sequence. Then, the model is trained to predict, for each window, the activity class and the offset to the true activity boundaries. Finally, overlapping windows are filtered out by non-maximum suppression, and adjacent windows of the same activity are concatenated to complete the segmentation task. Extensive experiments were conducted on eight popular benchmarking datasets, and the results show that our proposed method outperforms the state-of-the-art methods both for activity recognition and segmentation.
Negative Selection by Clustering for Contrastive Learning in Human Activity Recognition
Mar 23, 2022
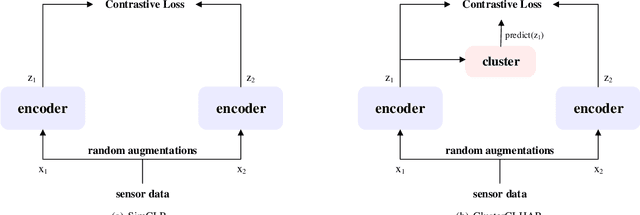
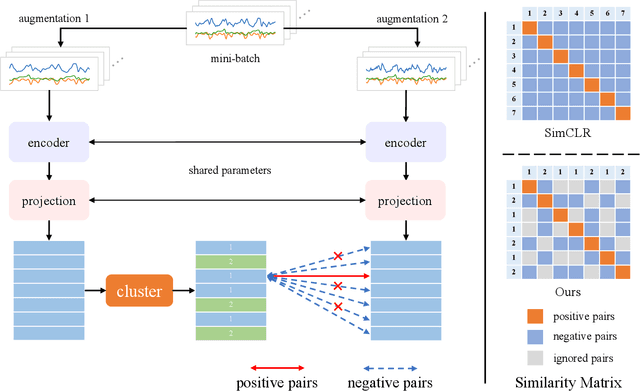
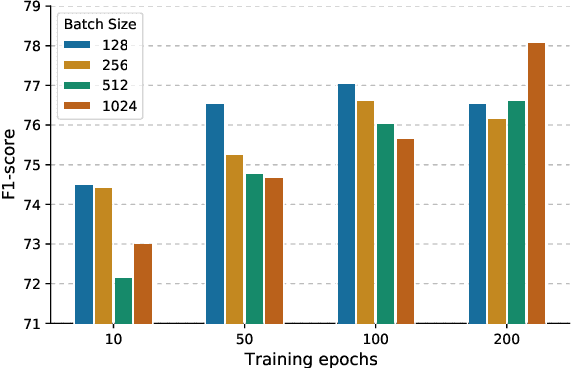
Contrastive learning has been applied to Human Activity Recognition (HAR) based on sensor data owing to its ability to achieve performance comparable to supervised learning with a large amount of unlabeled data and a small amount of labeled data. The pre-training task for contrastive learning is generally instance discrimination, which specifies that each instance belongs to a single class, but this will consider the same class of samples as negative examples. Such a pre-training task is not conducive to human activity recognition tasks, which are mainly classification tasks. To address this problem, we follow SimCLR to propose a new contrastive learning framework that negative selection by clustering in HAR, which is called ClusterCLHAR. Compared with SimCLR, it redefines the negative pairs in the contrastive loss function by using unsupervised clustering methods to generate soft labels that mask other samples of the same cluster to avoid regarding them as negative samples. We evaluate ClusterCLHAR on three benchmark datasets, USC-HAD, MotionSense, and UCI-HAR, using mean F1-score as the evaluation metric. The experiment results show that it outperforms all the state-of-the-art methods applied to HAR in self-supervised learning and semi-supervised learning.
Sensor Data Augmentation with Resampling for Contrastive Learning in Human Activity Recognition
Sep 05, 2021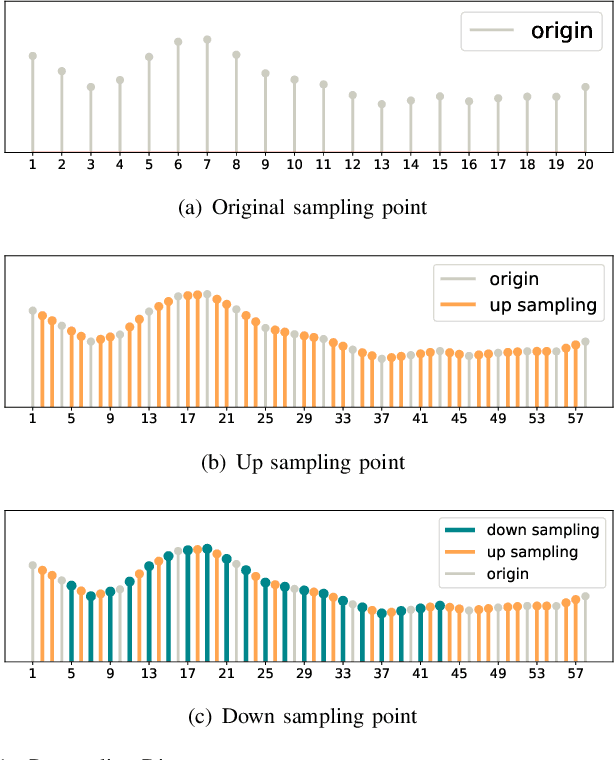
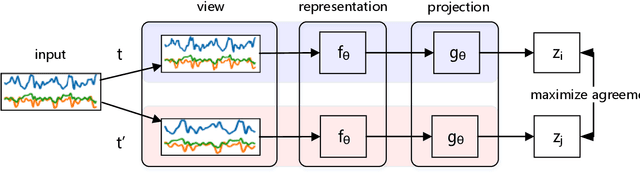
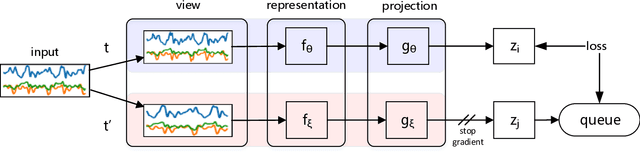
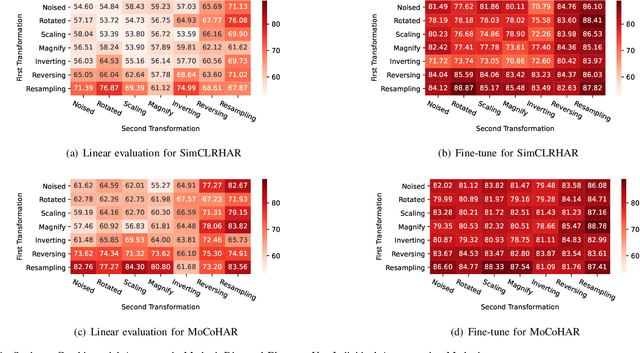
Human activity recognition plays an increasingly important role not only in our daily lives, but also in the medical and rehabilitation fields. The development of deep learning has also contributed to the advancement of human activity recognition, but the large amount of data annotation work required to train deep learning models is a major obstacle to the development of human activity recognition. Contrastive learning has started to be used in the field of sensor-based human activity recognition due to its ability to avoid the cost of labeling large datasets and its ability to better distinguish between sample representations of different instances. Among them, data augmentation, an important part of contrast learning, has a significant impact on model effectiveness, but current data augmentation methods do not perform too successfully in contrast learning frameworks for wearable sensor-based activity recognition. To optimize the effect of contrast learning models, in this paper, we investigate the sampling frequency of sensors and propose a resampling data augmentation method. In addition, we also propose a contrast learning framework based on human activity recognition and apply the resampling augmentation method to the data augmentation phase of contrast learning. The experimental results show that the resampling augmentation method outperforms supervised learning by 9.88% on UCI HAR and 7.69% on Motion Sensor in the fine-tuning evaluation of contrast learning with a small amount of labeled data, and also reveal that not all data augmentation methods will have positive effects in the contrast learning framework. Finally, we explored the influence of the combination of different augmentation methods on contrastive learning, and the experimental results showed that the effect of most combination augmentation methods was better than that of single augmentation.