 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Energy Management and Coordinated AIGC Workload Scheduling for Distributed Data Centers: A Diffusion-Aided Reward Shaping Approach
May 03, 2026Artificial intelligence-generated content (AIGC) has emerged as a transformative paradigm for automating the creation of diverse and customized content, giving rise to rapidly growing computational workloads in cloud data centers. It is imperative for AIGC service providers (ASPs) to strategically schedule AIGC workloads to reduce data center energy costs while guaranteeing high-quality content generation. However, the distinctive characteristics of AIGC services pose critical challenges, including model heterogeneity across ASPs, implicit service quality evaluation, and complex inference process control. To tackle these challenges, we propose a joint energy management and coordinated AIGC workload scheduling framework, which introduces an explicit mathematical characterization of service quality to promote both job transfer among ASPs and fine-grained inference process configuration. Moreover, various energy resources within data centers are jointly considered to enhance power usage flexibility. Subsequently, a system utility maximization problem is formulated to balance AIGC service revenue with operational penalties and costs. Nevertheless, the strong coupling among job scheduling decisions induces severe reward sparsity, which limits the effectiveness of existing deep reinforcement learning (DRL) algorithms. To address this issue, we develop a diffusion model-aided reward shaping approach to synthesize complementary reward signals through a multi-step denoising process. This approach is seamlessly integrated with DRL to enable efficient learning of scheduling policies under sparse environmental feedback. Experiments based on real-world models and datasets demonstrate that our scheme effectively accommodates electricity price fluctuations and AIGC model heterogeneity, while achieving superior learning convergence and system utility compared with benchmark methods.
LiveFact: A Dynamic, Time-Aware Benchmark for LLM-Driven Fake News Detection
Apr 06, 2026The rapid development of Large Language Models (LLMs) has transformed fake news detection and fact-checking tasks from simple classification to complex reasoning. However, evaluation frameworks have not kept pace. Current benchmarks are static, making them vulnerable to benchmark data contamination (BDC) and ineffective at assessing reasoning under temporal uncertainty. To address this, we introduce LiveFact a continuously updated benchmark that simulates the real-world "fog of war" in misinformation detection. LiveFact uses dynamic, temporal evidence sets to evaluate models on their ability to reason with evolving, incomplete information rather than on memorized knowledge. We propose a dual-mode evaluation: Classification Mode for final verification and Inference Mode for evidence-based reasoning, along with a component to monitor BDC explicitly. Tests with 22 LLMs show that open-source Mixture-of-Experts models, such as Qwen3-235B-A22B, now match or outperform proprietary state-of-the-art systems. More importantly, our analysis finds a significant "reasoning gap." Capable models exhibit epistemic humility by recognizing unverifiable claims in early data slices-an aspect traditional static benchmarks overlook. LiveFact sets a sustainable standard for evaluating robust, temporally aware AI verification.
SaPaVe: Towards Active Perception and Manipulation in Vision-Language-Action Models for Robotics
Mar 12, 2026Active perception and manipulation are crucial for robots to interact with complex scenes. Existing methods struggle to unify semantic-driven active perception with robust, viewpoint-invariant execution. We propose SaPaVe, an end-to-end framework that jointly learns these capabilities in a data-efficient manner. Our approach decouples camera and manipulation actions rather than placing them in a shared action space, and follows a bottom-up training strategy: we first train semantic camera control on a large-scale dataset, then jointly optimize both action types using hybrid data. To support this framework, we introduce ActiveViewPose-200K, a dataset of 200k image-language-camera movement pairs for semantic camera movement learning, and a 3D geometry-aware module that improves execution robustness under dynamic viewpoints. We also present ActiveManip-Bench, the first benchmark for evaluating active manipulation beyond fixed-view settings. Extensive experiments in both simulation and real-world environments show that SaPaVe outperforms recent vision-language-action models such as GR00T N1 and \(π_0\), achieving up to 31.25\% higher success rates in real-world tasks. These results show that tightly coupled perception and execution, when trained with decoupled yet coordinated strategies, enable efficient and generalizable active manipulation. Project page: https://lmzpai.github.io/SaPaVe
Spotlighting Task-Relevant Features: Object-Centric Representations for Better Generalization in Robotic Manipulation
Jan 29, 2026The generalization capabilities of robotic manipulation policies are heavily influenced by the choice of visual representations. Existing approaches typically rely on representations extracted from pre-trained encoders, using two dominant types of features: global features, which summarize an entire image via a single pooled vector, and dense features, which preserve a patch-wise embedding from the final encoder layer. While widely used, both feature types mix task-relevant and irrelevant information, leading to poor generalization under distribution shifts, such as changes in lighting, textures, or the presence of distractors. In this work, we explore an intermediate structured alternative: Slot-Based Object-Centric Representations (SBOCR), which group dense features into a finite set of object-like entities. This representation permits to naturally reduce the noise provided to the robotic manipulation policy while keeping enough information to efficiently perform the task. We benchmark a range of global and dense representations against intermediate slot-based representations, across a suite of simulated and real-world manipulation tasks ranging from simple to complex. We evaluate their generalization under diverse visual conditions, including changes in lighting, texture, and the presence of distractors. Our findings reveal that SBOCR-based policies outperform dense and global representation-based policies in generalization settings, even without task-specific pretraining. These insights suggest that SBOCR is a promising direction for designing visual systems that generalize effectively in dynamic, real-world robotic environments.
STORM: Slot-based Task-aware Object-centric Representation for robotic Manipulation
Jan 28, 2026Visual foundation models provide strong perceptual features for robotics, but their dense representations lack explicit object-level structure, limiting robustness and contractility in manipulation tasks. We propose STORM (Slot-based Task-aware Object-centric Representation for robotic Manipulation), a lightweight object-centric adaptation module that augments frozen visual foundation models with a small set of semantic-aware slots for robotic manipulation. Rather than retraining large backbones, STORM employs a multi-phase training strategy: object-centric slots are first stabilized through visual--semantic pretraining using language embeddings, then jointly adapted with a downstream manipulation policy. This staged learning prevents degenerate slot formation and preserves semantic consistency while aligning perception with task objectives. Experiments on object discovery benchmarks and simulated manipulation tasks show that STORM improves generalization to visual distractors, and control performance compared to directly using frozen foundation model features or training object-centric representations end-to-end. Our results highlight multi-phase adaptation as an efficient mechanism for transforming generic foundation model features into task-aware object-centric representations for robotic control.
SOTFormer: A Minimal Transformer for Unified Object Tracking and Trajectory Prediction
Nov 14, 2025Accurate single-object tracking and short-term motion forecasting remain challenging under occlusion, scale variation, and temporal drift, which disrupt the temporal coherence required for real-time perception. We introduce \textbf{SOTFormer}, a minimal constant-memory temporal transformer that unifies object detection, tracking, and short-horizon trajectory prediction within a single end-to-end framework. Unlike prior models with recurrent or stacked temporal encoders, SOTFormer achieves stable identity propagation through a ground-truth-primed memory and a burn-in anchor loss that explicitly stabilizes initialization. A single lightweight temporal-attention layer refines embeddings across frames, enabling real-time inference with fixed GPU memory. On the Mini-LaSOT (20%) benchmark, SOTFormer attains 76.3 AUC and 53.7 FPS (AMP, 4.3 GB VRAM), outperforming transformer baselines such as TrackFormer and MOTRv2 under fast motion, scale change, and occlusion.
Expand Your SCOPE: Semantic Cognition over Potential-Based Exploration for Embodied Visual Navigation
Nov 12, 2025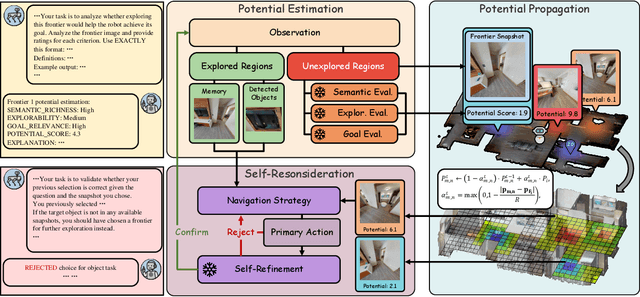
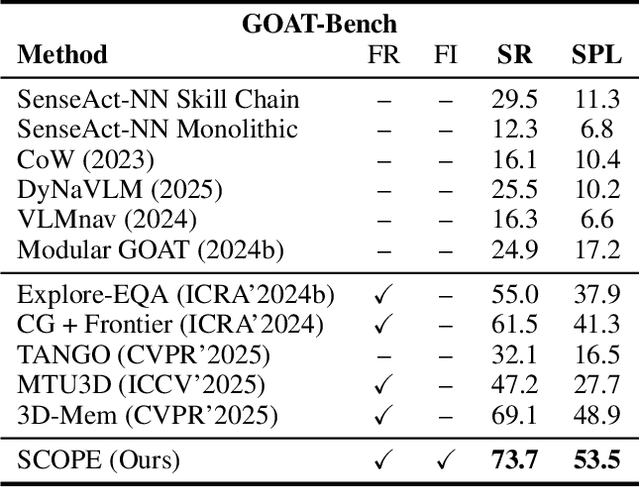
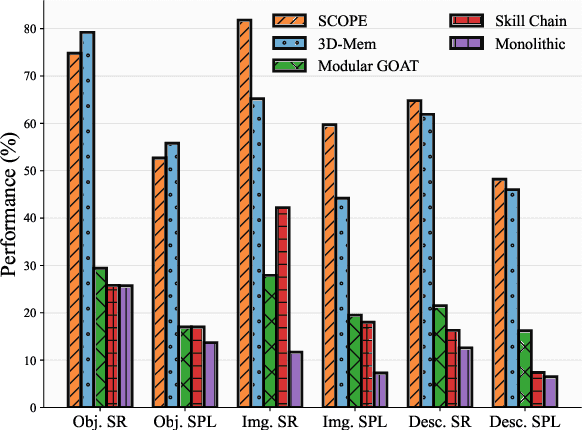
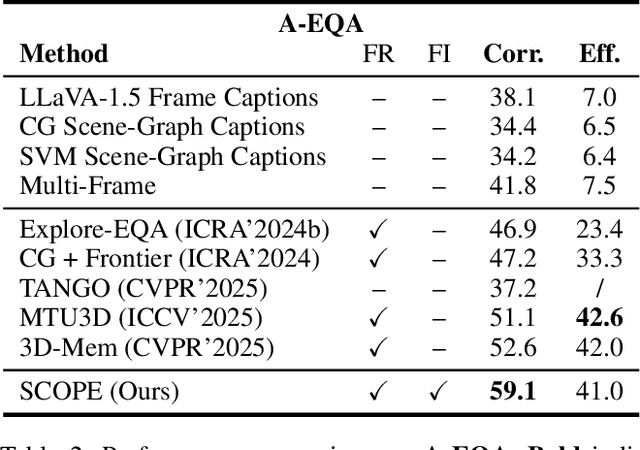
Embodied visual navigation remains a challenging task, as agents must explore unknown environments with limited knowledge. Existing zero-shot studies have shown that incorporating memory mechanisms to support goal-directed behavior can improve long-horizon planning performance. However, they overlook visual frontier boundaries, which fundamentally dictate future trajectories and observations, and fall short of inferring the relationship between partial visual observations and navigation goals. In this paper, we propose Semantic Cognition Over Potential-based Exploration (SCOPE), a zero-shot framework that explicitly leverages frontier information to drive potential-based exploration, enabling more informed and goal-relevant decisions. SCOPE estimates exploration potential with a Vision-Language Model and organizes it into a spatio-temporal potential graph, capturing boundary dynamics to support long-horizon planning. In addition, SCOPE incorporates a self-reconsideration mechanism that revisits and refines prior decisions, enhancing reliability and reducing overconfident errors. Experimental results on two diverse embodied navigation tasks show that SCOPE outperforms state-of-the-art baselines by 4.6\% in accuracy. Further analysis demonstrates that its core components lead to improved calibration, stronger generalization, and higher decision quality.
Robotic Manipulation via Imitation Learning: Taxonomy, Evolution, Benchmark, and Challenges
Aug 24, 2025



Robotic Manipulation (RM) is central to the advancement of autonomous robots, enabling them to interact with and manipulate objects in real-world environments. This survey focuses on RM methodologies that leverage imitation learning, a powerful technique that allows robots to learn complex manipulation skills by mimicking human demonstrations. We identify and analyze the most influential studies in this domain, selected based on community impact and intrinsic quality. For each paper, we provide a structured summary, covering the research purpose, technical implementation, hierarchical classification, input formats, key priors, strengths and limitations, and citation metrics. Additionally, we trace the chronological development of imitation learning techniques within RM policy (RMP), offering a timeline of key technological advancements. Where available, we report benchmark results and perform quantitative evaluations to compare existing methods. By synthesizing these insights, this review provides a comprehensive resource for researchers and practitioners, highlighting both the state of the art and the challenges that lie ahead in the field of robotic manipulation through imitation learning.
ADPro: a Test-time Adaptive Diffusion Policy for Robot Manipulation via Manifold and Initial Noise Constraints
Aug 08, 2025Diffusion policies have recently emerged as a powerful class of visuomotor controllers for robot manipulation, offering stable training and expressive multi-modal action modeling. However, existing approaches typically treat action generation as an unconstrained denoising process, ignoring valuable a priori knowledge about geometry and control structure. In this work, we propose the Adaptive Diffusion Policy (ADP), a test-time adaptation method that introduces two key inductive biases into the diffusion. First, we embed a geometric manifold constraint that aligns denoising updates with task-relevant subspaces, leveraging the fact that the relative pose between the end-effector and target scene provides a natural gradient direction, and guiding denoising along the geodesic path of the manipulation manifold. Then, to reduce unnecessary exploration and accelerate convergence, we propose an analytically guided initialization: rather than sampling from an uninformative prior, we compute a rough registration between the gripper and target scenes to propose a structured initial noisy action. ADP is compatible with pre-trained diffusion policies and requires no retraining, enabling test-time adaptation that tailors the policy to specific tasks, thereby enhancing generalization across novel tasks and environments. Experiments on RLBench, CALVIN, and real-world dataset show that ADPro, an implementation of ADP, improves success rates, generalization, and sampling efficiency, achieving up to 25% faster execution and 9% points over strong diffusion baselines.
Trajectory Prediction in Dynamic Object Tracking: A Critical Study
Jun 24, 2025This study provides a detailed analysis of current advancements in dynamic object tracking (DOT) and trajectory prediction (TP) methodologies, including their applications and challenges. It covers various approaches, such as feature-based, segmentation-based, estimation-based, and learning-based methods, evaluating their effectiveness, deployment, and limitations in real-world scenarios. The study highlights the significant impact of these technologies in automotive and autonomous vehicles, surveillance and security, healthcare, and industrial automation, contributing to safety and efficiency. Despite the progress, challenges such as improved generalization, computational efficiency, reduced data dependency, and ethical considerations still exist. The study suggests future research directions to address these challenges, emphasizing the importance of multimodal data integration, semantic information fusion, and developing context-aware systems, along with ethical and privacy-preserving frameworks.