 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Optimized Conditional Diffusion for Domain Adaptation
May 12, 2025Pseudo-labeling is a cornerstone of Unsupervised Domain Adaptation (UDA), yet the scarcity of High-Confidence Pseudo-Labeled Target Domain Samples (\textbf{hcpl-tds}) often leads to inaccurate cross-domain statistical alignment, causing DA failures. To address this challenge, we propose \textbf{N}oise \textbf{O}ptimized \textbf{C}onditional \textbf{D}iffusion for \textbf{D}omain \textbf{A}daptation (\textbf{NOCDDA}), which seamlessly integrates the generative capabilities of conditional diffusion models with the decision-making requirements of DA to achieve task-coupled optimization for efficient adaptation. For robust cross-domain consistency, we modify the DA classifier to align with the conditional diffusion classifier within a unified optimization framework, enabling forward training on noise-varying cross-domain samples. Furthermore, we argue that the conventional \( \mathcal{N}(\mathbf{0}, \mathbf{I}) \) initialization in diffusion models often generates class-confused hcpl-tds, compromising discriminative DA. To resolve this, we introduce a class-aware noise optimization strategy that refines sampling regions for reverse class-specific hcpl-tds generation, effectively enhancing cross-domain alignment. Extensive experiments across 5 benchmark datasets and 29 DA tasks demonstrate significant performance gains of \textbf{NOCDDA} over 31 state-of-the-art methods, validating its robustness and effectiveness.
* 9 pages, 4 figures This work has been accepted by the International Joint Conference on Artificial Intelligence (IJCAI 2025)
Beyond Batch Learning: Global Awareness Enhanced Domain Adaptation
Feb 10, 2025In domain adaptation (DA), the effectiveness of deep learning-based models is often constrained by batch learning strategies that fail to fully apprehend the global statistical and geometric characteristics of data distributions. Addressing this gap, we introduce 'Global Awareness Enhanced Domain Adaptation' (GAN-DA), a novel approach that transcends traditional batch-based limitations. GAN-DA integrates a unique predefined feature representation (PFR) to facilitate the alignment of cross-domain distributions, thereby achieving a comprehensive global statistical awareness. This representation is innovatively expanded to encompass orthogonal and common feature aspects, which enhances the unification of global manifold structures and refines decision boundaries for more effective DA. Our extensive experiments, encompassing 27 diverse cross-domain image classification tasks, demonstrate GAN-DA's remarkable superiority, outperforming 24 established DA methods by a significant margin. Furthermore, our in-depth analyses shed light on the decision-making processes, revealing insights into the adaptability and efficiency of GAN-DA. This approach not only addresses the limitations of existing DA methodologies but also sets a new benchmark in the realm of domain adaptation, offering broad implications for future research and applications in this field.
Decision Boundary Optimization-Informed Domain Adaptation
Feb 10, 2025



Maximum Mean Discrepancy (MMD) is widely used in a number of domain adaptation (DA) methods and shows its effectiveness in aligning data distributions across domains. However, in previous DA research, MMD-based DA methods focus mostly on distribution alignment, and ignore to optimize the decision boundary for classification-aware DA, thereby falling short in reducing the DA upper error bound. In this paper, we propose a strengthened MMD measurement, namely, Decision Boundary optimization-informed MMD (DB-MMD), which enables MMD to carefully take into account the decision boundaries, thereby simultaneously optimizing the distribution alignment and cross-domain classifier within a hybrid framework, and leading to a theoretical bound guided DA. We further seamlessly embed the proposed DB-MMD measurement into several popular DA methods, e.g., MEDA, DGA-DA, to demonstrate its effectiveness w.r.t different experimental settings. We carry out comprehensive experiments using 8 standard DA datasets. The experimental results show that the DB-MMD enforced DA methods improve their baseline models using plain vanilla MMD, with a margin that can be as high as 9.5.
Attention Regularized Laplace Graph for Domain Adaptation
Oct 15, 2022


In leveraging manifold learning in domain adaptation (DA), graph embedding-based DA methods have shown their effectiveness in preserving data manifold through the Laplace graph. However, current graph embedding DA methods suffer from two issues: 1). they are only concerned with preservation of the underlying data structures in the embedding and ignore sub-domain adaptation, which requires taking into account intra-class similarity and inter-class dissimilarity, thereby leading to negative transfer; 2). manifold learning is proposed across different feature/label spaces separately, thereby hindering unified comprehensive manifold learning. In this paper, starting from our previous DGA-DA, we propose a novel DA method, namely Attention Regularized Laplace Graph-based Domain Adaptation (ARG-DA), to remedy the aforementioned issues. Specifically, by weighting the importance across different sub-domain adaptation tasks, we propose the Attention Regularized Laplace Graph for class-aware DA, thereby generating the attention regularized DA. Furthermore, using a specifically designed FEEL strategy, our approach dynamically unifies alignment of the manifold structures across different feature/label spaces, thus leading to comprehensive manifold learning. Comprehensive experiments are carried out to verify the effectiveness of the proposed DA method, which consistently outperforms the state-of-the-art DA methods on 7 standard DA benchmarks, i.e., 37 cross-domain image classification tasks including object, face, and digit images. An in-depth analysis of the proposed DA method is also discussed, including sensitivity, convergence, and robustness.
Discriminative Noise Robust Sparse Orthogonal Label Regression-based Domain Adaptation
Jan 09, 2021


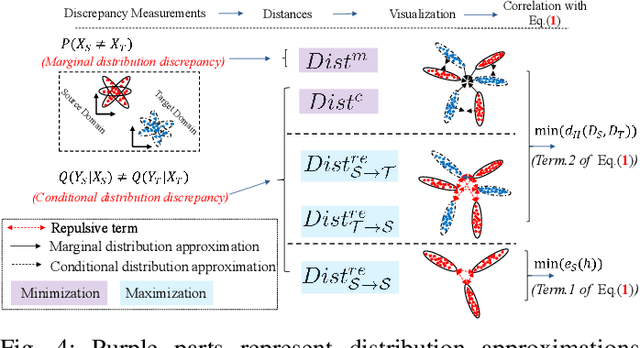
Domain adaptation (DA) aims to enable a learning model trained from a source domain to generalize well on a target domain, despite the mismatch of data distributions between the two domains. State-of-the-art DA methods have so far focused on the search of a latent shared feature space where source and target domain data can be aligned either statistically and/or geometrically. In this paper, we propose a novel unsupervised DA method, namely Discriminative Noise Robust Sparse Orthogonal Label Regression-based Domain Adaptation (DOLL-DA). The proposed DOLL-DA derives from a novel integrated model which searches a shared feature subspace where source and target domain data are, through optimization of some repulse force terms, discriminatively aligned statistically, while at same time regresses orthogonally data labels thereof using a label embedding trick. Furthermore, in minimizing a novel Noise Robust Sparse Orthogonal Label Regression(NRS_OLR) term, the proposed model explicitly accounts for data outliers to avoid negative transfer and introduces the property of sparsity when regressing data labels. Due to the character restriction. Please read our detailed abstract in our paper.
Discriminative Label Consistent Domain Adaptation
Feb 21, 2018


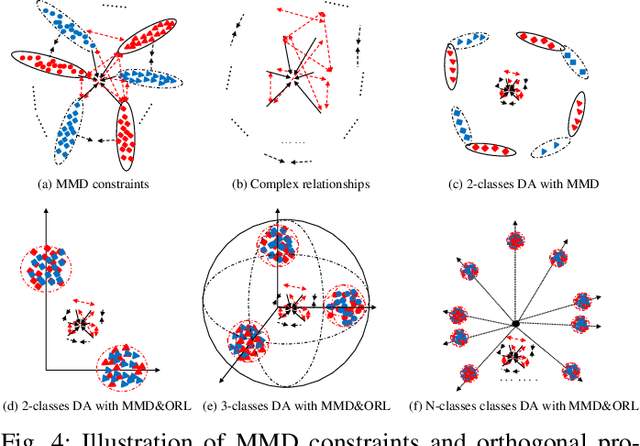
Domain adaptation (DA) is transfer learning which aims to learn an effective predictor on target data from source data despite data distribution mismatch between source and target. We present in this paper a novel unsupervised DA method for cross-domain visual recognition which simultaneously optimizes the three terms of a theoretically established error bound. Specifically, the proposed DA method iteratively searches a latent shared feature subspace where not only the divergence of data distributions between the source domain and the target domain is decreased as most state-of-the-art DA methods do, but also the inter-class distances are increased to facilitate discriminative learning. Moreover, the proposed DA method sparsely regresses class labels from the features achieved in the shared subspace while minimizing the prediction errors on the source data and ensuring label consistency between source and target. Data outliers are also accounted for to further avoid negative knowledge transfer. Comprehensive experiments and in-depth analysis verify the effectiveness of the proposed DA method which consistently outperforms the state-of-the-art DA methods on standard DA benchmarks, i.e., 12 cross-domain image classification tasks.
Discriminative and Geometry Aware Unsupervised Domain Adaptation
Dec 28, 2017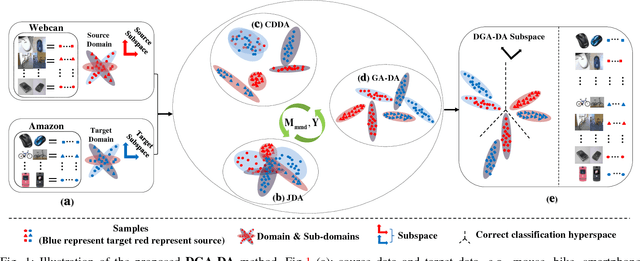


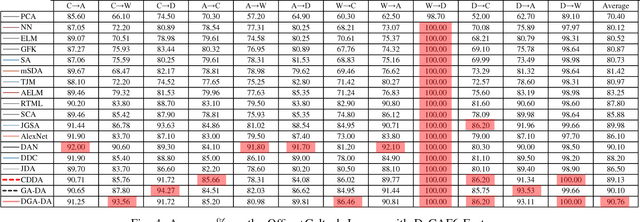
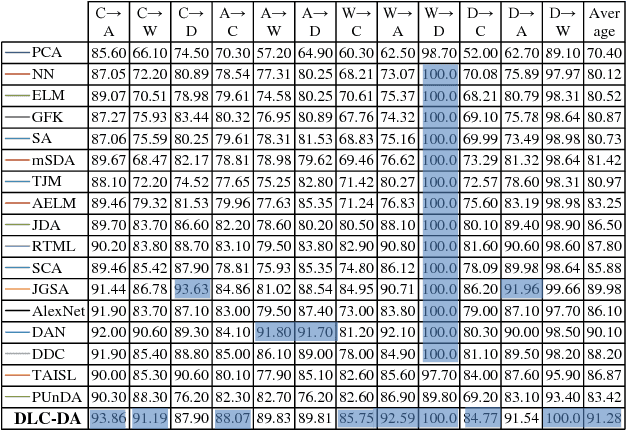
Domain adaptation (DA) aims to generalize a learning model across training and testing data despite the mismatch of their data distributions. In light of a theoretical estimation of upper error bound, we argue in this paper that an effective DA method should 1) search a shared feature subspace where source and target data are not only aligned in terms of distributions as most state of the art DA methods do, but also discriminative in that instances of different classes are well separated; 2) account for the geometric structure of the underlying data manifold when inferring data labels on the target domain. In comparison with a baseline DA method which only cares about data distribution alignment between source and target, we derive three different DA models, namely CDDA, GA-DA, and DGA-DA, to highlight the contribution of Close yet Discriminative DA(CDDA) based on 1), Geometry Aware DA (GA-DA) based on 2), and finally Discriminative and Geometry Aware DA (DGA-DA) implementing jointly 1) and 2). Using both synthetic and real data, we show the effectiveness of the proposed approach which consistently outperforms state of the art DA methods over 36 image classification DA tasks through 6 popular benchmarks. We further carry out in-depth analysis of the proposed DA method in quantifying the contribution of each term of our DA model and provide insights into the proposed DA methods in visualizing both real and synthetic data.
Robust Data Geometric Structure Aligned Close yet Discriminative Domain Adaptation
May 24, 2017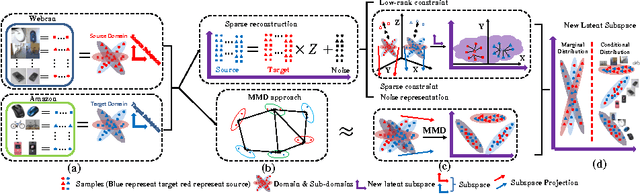

Domain adaptation (DA) is transfer learning which aims to leverage labeled data in a related source domain to achieve informed knowledge transfer and help the classification of unlabeled data in a target domain. In this paper, we propose a novel DA method, namely Robust Data Geometric Structure Aligned, Close yet Discriminative Domain Adaptation (RSA-CDDA), which brings closer, in a latent joint subspace, both source and target data distributions, and aligns inherent hidden source and target data geometric structures while performing discriminative DA in repulsing both interclass source and target data. The proposed method performs domain adaptation between source and target in solving a unified model, which incorporates data distribution constraints, in particular via a nonparametric distance, i.e., Maximum Mean Discrepancy (MMD), as well as constraints on inherent hidden data geometric structure segmentation and alignment between source and target, through low rank and sparse representation. RSA-CDDA achieves the search of a joint subspace in solving the proposed unified model through iterative optimization, alternating Rayleigh quotient algorithm and inexact augmented Lagrange multiplier algorithm. Extensive experiments carried out on standard DA benchmarks, i.e., 16 cross-domain image classification tasks, verify the effectiveness of the proposed method, which consistently outperforms the state-of-the-art methods.
Close Yet Distinctive Domain Adaptation
Apr 13, 2017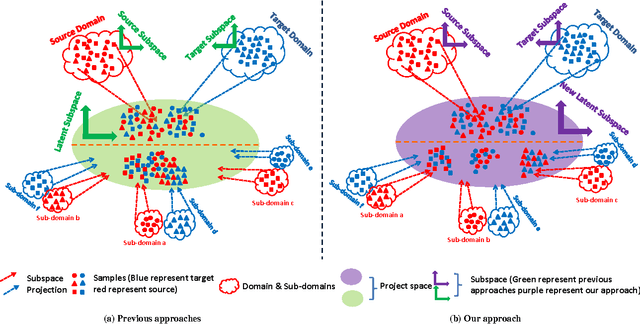



Domain adaptation is transfer learning which aims to generalize a learning model across training and testing data with different distributions. Most previous research tackle this problem in seeking a shared feature representation between source and target domains while reducing the mismatch of their data distributions. In this paper, we propose a close yet discriminative domain adaptation method, namely CDDA, which generates a latent feature representation with two interesting properties. First, the discrepancy between the source and target domain, measured in terms of both marginal and conditional probability distribution via Maximum Mean Discrepancy is minimized so as to attract two domains close to each other. More importantly, we also design a repulsive force term, which maximizes the distances between each label dependent sub-domain to all others so as to drag different class dependent sub-domains far away from each other and thereby increase the discriminative power of the adapted domain. Moreover, given the fact that the underlying data manifold could have complex geometric structure, we further propose the constraints of label smoothness and geometric structure consistency for label propagation. Extensive experiments are conducted on 36 cross-domain image classification tasks over four public datasets. The comprehensive results show that the proposed method consistently outperforms the state-of-the-art methods with significant margins.