 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMamba Based Feature Extraction And Adaptive Multilevel Feature Fusion For 3D Tumor Segmentation From Multi-modal Medical Image
Apr 30, 2025Multi-modal 3D medical image segmentation aims to accurately identify tumor regions across different modalities, facing challenges from variations in image intensity and tumor morphology. Traditional convolutional neural network (CNN)-based methods struggle with capturing global features, while Transformers-based methods, despite effectively capturing global context, encounter high computational costs in 3D medical image segmentation. The Mamba model combines linear scalability with long-distance modeling, making it a promising approach for visual representation learning. However, Mamba-based 3D multi-modal segmentation still struggles to leverage modality-specific features and fuse complementary information effectively. In this paper, we propose a Mamba based feature extraction and adaptive multilevel feature fusion for 3D tumor segmentation using multi-modal medical image. We first develop the specific modality Mamba encoder to efficiently extract long-range relevant features that represent anatomical and pathological structures present in each modality. Moreover, we design an bi-level synergistic integration block that dynamically merges multi-modal and multi-level complementary features by the modality attention and channel attention learning. Lastly, the decoder combines deep semantic information with fine-grained details to generate the tumor segmentation map. Experimental results on medical image datasets (PET/CT and MRI multi-sequence) show that our approach achieve competitive performance compared to the state-of-the-art CNN, Transformer, and Mamba-based approaches.
Iterative Collaboration Network Guided By Reconstruction Prior for Medical Image Super-Resolution
Apr 23, 2025High-resolution medical images can provide more detailed information for better diagnosis. Conventional medical image super-resolution relies on a single task which first performs the extraction of the features and then upscaling based on the features. The features extracted may not be complete for super-resolution. Recent multi-task learning,including reconstruction and super-resolution, is a good solution to obtain additional relevant information. The interaction between the two tasks is often insufficient, which still leads to incomplete and less relevant deep features. To address above limitations, we propose an iterative collaboration network (ICONet) to improve communications between tasks by progressively incorporating reconstruction prior to the super-resolution learning procedure in an iterative collaboration way. It consists of a reconstruction branch, a super-resolution branch, and a SR-Rec fusion module. The reconstruction branch generates the artifact-free image as prior, which is followed by a super-resolution branch for prior knowledge-guided super-resolution. Unlike the widely-used convolutional neural networks for extracting local features and Transformers with quadratic computational complexity for modeling long-range dependencies, we develop a new residual spatial-channel feature learning (RSCFL) module of two branches to efficiently establish feature relationships in spatial and channel dimensions. Moreover, the designed SR-Rec fusion module fuses the reconstruction prior and super-resolution features with each other in an adaptive manner. Our ICONet is built with multi-stage models to iteratively upscale the low-resolution images using steps of 2x and simultaneously interact between two branches in multi-stage supervisions.
Global and Local Mamba Network for Multi-Modality Medical Image Super-Resolution
Apr 14, 2025Convolutional neural networks and Transformer have made significant progresses in multi-modality medical image super-resolution. However, these methods either have a fixed receptive field for local learning or significant computational burdens for global learning, limiting the super-resolution performance. To solve this problem, State Space Models, notably Mamba, is introduced to efficiently model long-range dependencies in images with linear computational complexity. Relying on the Mamba and the fact that low-resolution images rely on global information to compensate for missing details, while high-resolution reference images need to provide more local details for accurate super-resolution, we propose a global and local Mamba network (GLMamba) for multi-modality medical image super-resolution. To be specific, our GLMamba is a two-branch network equipped with a global Mamba branch and a local Mamba branch. The global Mamba branch captures long-range relationships in low-resolution inputs, and the local Mamba branch focuses more on short-range details in high-resolution reference images. We also use the deform block to adaptively extract features of both branches to enhance the representation ability. A modulator is designed to further enhance deformable features in both global and local Mamba blocks. To fully integrate the reference image for low-resolution image super-resolution, we further develop a multi-modality feature fusion block to adaptively fuse features by considering similarities, differences, and complementary aspects between modalities. In addition, a contrastive edge loss (CELoss) is developed for sufficient enhancement of edge textures and contrast in medical images.
EsurvFusion: An evidential multimodal survival fusion model based on Gaussian random fuzzy numbers
Dec 02, 2024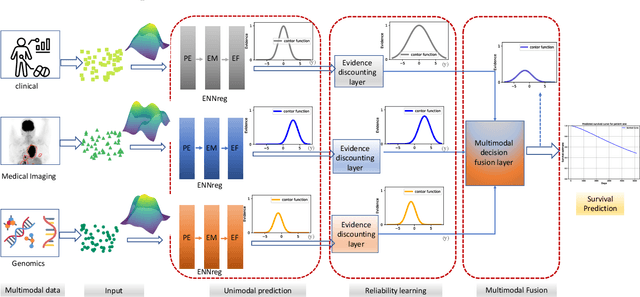
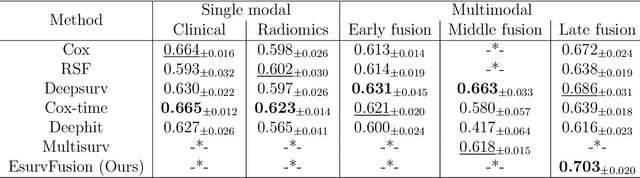
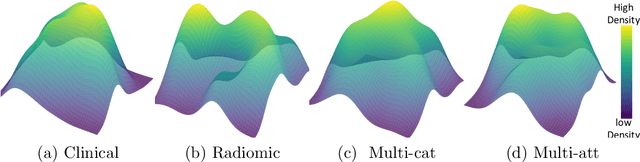
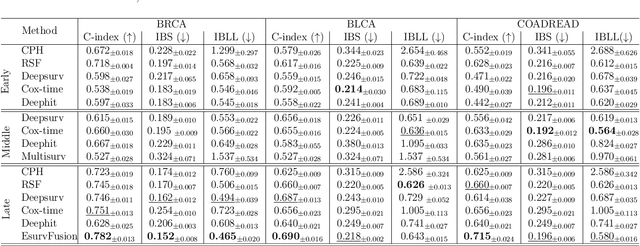
Multimodal survival analysis aims to combine heterogeneous data sources (e.g., clinical, imaging, text, genomics) to improve the prediction quality of survival outcomes. However, this task is particularly challenging due to high heterogeneity and noise across data sources, which vary in structure, distribution, and context. Additionally, the ground truth is often censored (uncertain) due to incomplete follow-up data. In this paper, we propose a novel evidential multimodal survival fusion model, EsurvFusion, designed to combine multimodal data at the decision level through an evidence-based decision fusion layer that jointly addresses both data and model uncertainty while incorporating modality-level reliability. Specifically, EsurvFusion first models unimodal data with newly introduced Gaussian random fuzzy numbers, producing unimodal survival predictions along with corresponding aleatoric and epistemic uncertainties. It then estimates modality-level reliability through a reliability discounting layer to correct the misleading impact of noisy data modalities. Finally, a multimodal evidence-based fusion layer is introduced to combine the discounted predictions to form a unified, interpretable multimodal survival analysis model, revealing each modality's influence based on the learned reliability coefficients. This is the first work that studies multimodal survival analysis with both uncertainty and reliability. Extensive experiments on four multimodal survival datasets demonstrate the effectiveness of our model in handling high heterogeneity data, establishing new state-of-the-art on several benchmarks.
Self-Prior Guided Mamba-UNet Networks for Medical Image Super-Resolution
Jul 08, 2024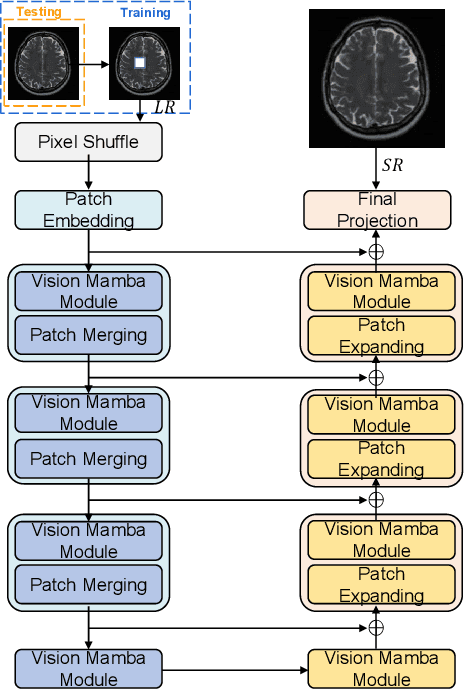
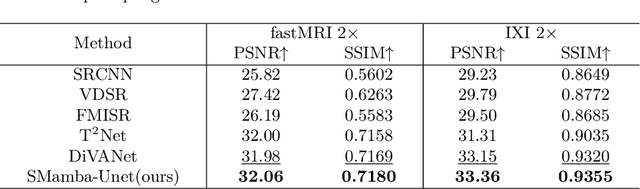
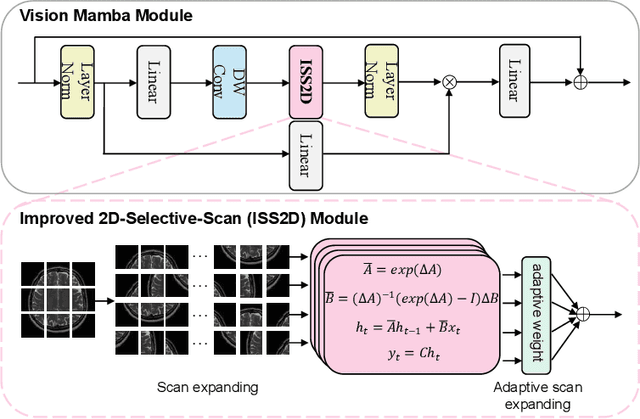
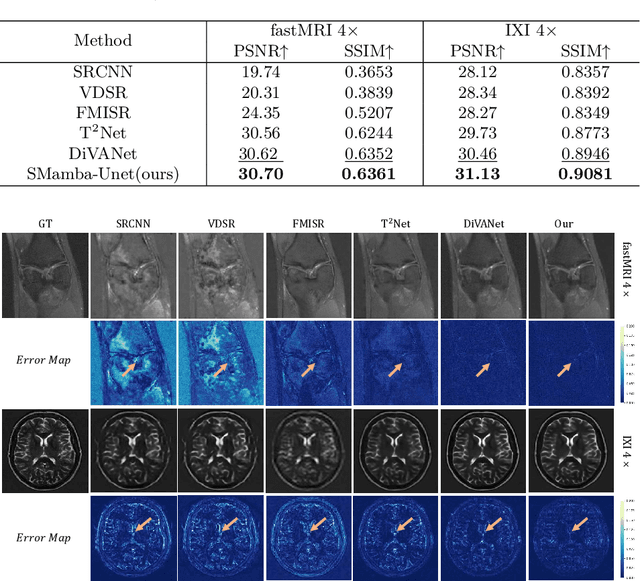
In this paper, we propose a self-prior guided Mamba-UNet network (SMamba-UNet) for medical image super-resolution. Existing methods are primarily based on convolutional neural networks (CNNs) or Transformers. CNNs-based methods fail to capture long-range dependencies, while Transformer-based approaches face heavy calculation challenges due to their quadratic computational complexity. Recently, State Space Models (SSMs) especially Mamba have emerged, capable of modeling long-range dependencies with linear computational complexity. Inspired by Mamba, our approach aims to learn the self-prior multi-scale contextual features under Mamba-UNet networks, which may help to super-resolve low-resolution medical images in an efficient way. Specifically, we obtain self-priors by perturbing the brightness inpainting of the input image during network training, which can learn detailed texture and brightness information that is beneficial for super-resolution. Furthermore, we combine Mamba with Unet network to mine global features at different levels. We also design an improved 2D-Selective-Scan (ISS2D) module to divide image features into different directional sequences to learn long-range dependencies in multiple directions, and adaptively fuse sequence information to enhance super-resolved feature representation. Both qualitative and quantitative experimental results demonstrate that our approach outperforms current state-of-the-art methods on two public medical datasets: the IXI and fastMRI.
Deform-Mamba Network for MRI Super-Resolution
Jul 08, 2024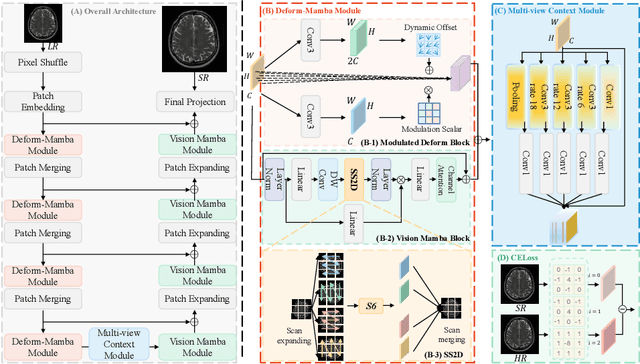
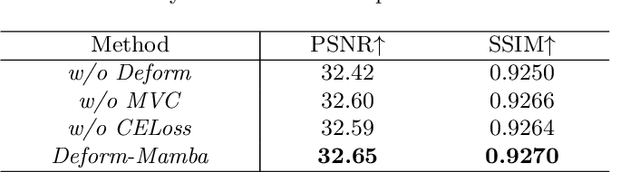
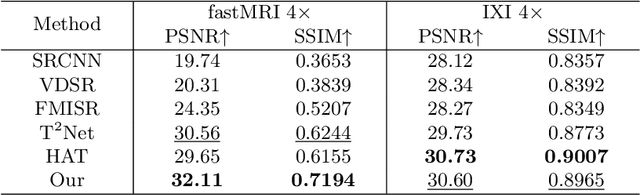
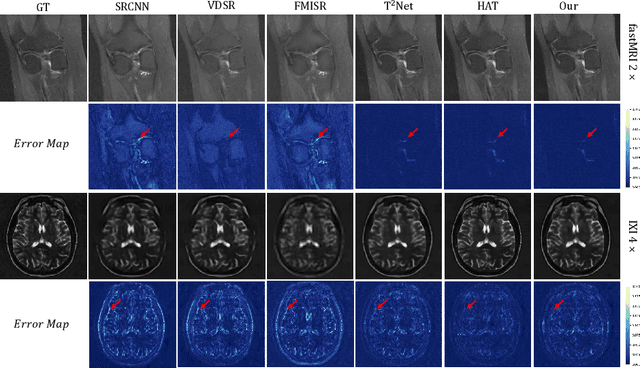
In this paper, we propose a new architecture, called Deform-Mamba, for MR image super-resolution. Unlike conventional CNN or Transformer-based super-resolution approaches which encounter challenges related to the local respective field or heavy computational cost, our approach aims to effectively explore the local and global information of images. Specifically, we develop a Deform-Mamba encoder which is composed of two branches, modulated deform block and vision Mamba block. We also design a multi-view context module in the bottleneck layer to explore the multi-view contextual content. Thanks to the extracted features of the encoder, which include content-adaptive local and efficient global information, the vision Mamba decoder finally generates high-quality MR images. Moreover, we introduce a contrastive edge loss to promote the reconstruction of edge and contrast related content. Quantitative and qualitative experimental results indicate that our approach on IXI and fastMRI datasets achieves competitive performance.
Discriminative Hamiltonian Variational Autoencoder for Accurate Tumor Segmentation in Data-Scarce Regimes
Jun 17, 2024



Deep learning has gained significant attention in medical image segmentation. However, the limited availability of annotated training data presents a challenge to achieving accurate results. In efforts to overcome this challenge, data augmentation techniques have been proposed. However, the majority of these approaches primarily focus on image generation. For segmentation tasks, providing both images and their corresponding target masks is crucial, and the generation of diverse and realistic samples remains a complex task, especially when working with limited training datasets. To this end, we propose a new end-to-end hybrid architecture based on Hamiltonian Variational Autoencoders (HVAE) and a discriminative regularization to improve the quality of generated images. Our method provides an accuracte estimation of the joint distribution of the images and masks, resulting in the generation of realistic medical images with reduced artifacts and off-distribution instances. As generating 3D volumes requires substantial time and memory, our architecture operates on a slice-by-slice basis to segment 3D volumes, capitilizing on the richly augmented dataset. Experiments conducted on two public datasets, BRATS (MRI modality) and HECKTOR (PET modality), demonstrate the efficacy of our proposed method on different medical imaging modalities with limited data.
3D MRI Synthesis with Slice-Based Latent Diffusion Models: Improving Tumor Segmentation Tasks in Data-Scarce Regimes
Jun 08, 2024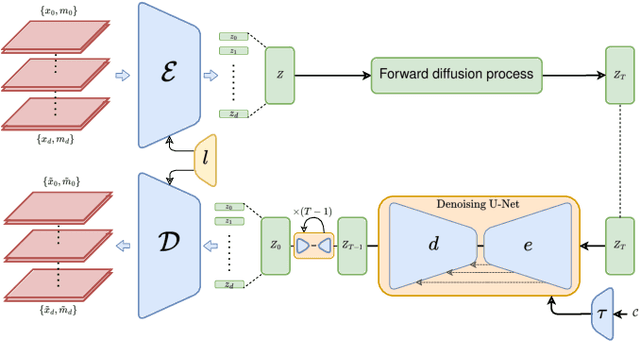
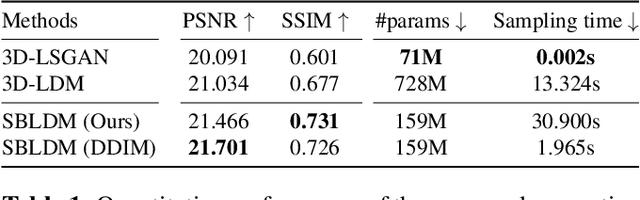
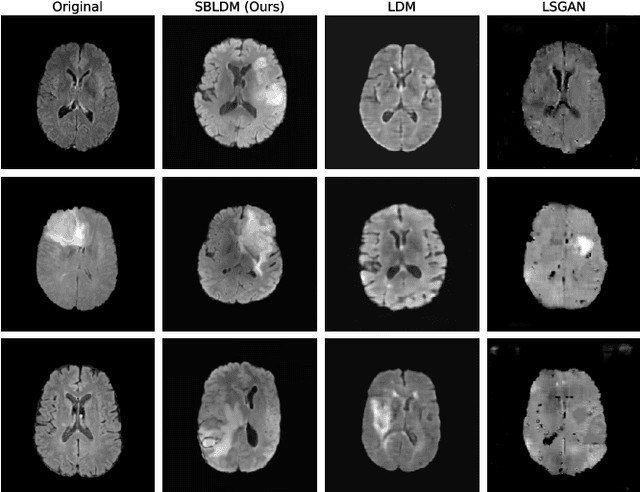
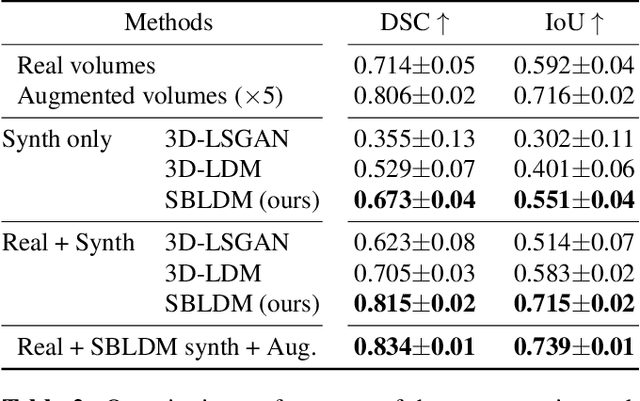
Despite the increasing use of deep learning in medical image segmentation, the limited availability of annotated training data remains a major challenge due to the time-consuming data acquisition and privacy regulations. In the context of segmentation tasks, providing both medical images and their corresponding target masks is essential. However, conventional data augmentation approaches mainly focus on image synthesis. In this study, we propose a novel slice-based latent diffusion architecture designed to address the complexities of volumetric data generation in a slice-by-slice fashion. This approach extends the joint distribution modeling of medical images and their associated masks, allowing a simultaneous generation of both under data-scarce regimes. Our approach mitigates the computational complexity and memory expensiveness typically associated with diffusion models. Furthermore, our architecture can be conditioned by tumor characteristics, including size, shape, and relative position, thereby providing a diverse range of tumor variations. Experiments on a segmentation task using the BRATS2022 confirm the effectiveness of the synthesized volumes and masks for data augmentation.
End-to-end autoencoding architecture for the simultaneous generation of medical images and corresponding segmentation masks
Nov 17, 2023Despite the increasing use of deep learning in medical image segmentation, acquiring sufficient training data remains a challenge in the medical field. In response, data augmentation techniques have been proposed; however, the generation of diverse and realistic medical images and their corresponding masks remains a difficult task, especially when working with insufficient training sets. To address these limitations, we present an end-to-end architecture based on the Hamiltonian Variational Autoencoder (HVAE). This approach yields an improved posterior distribution approximation compared to traditional Variational Autoencoders (VAE), resulting in higher image generation quality. Our method outperforms generative adversarial architectures under data-scarce conditions, showcasing enhancements in image quality and precise tumor mask synthesis. We conduct experiments on two publicly available datasets, MICCAI's Brain Tumor Segmentation Challenge (BRATS), and Head and Neck Tumor Segmentation Challenge (HECKTOR), demonstrating the effectiveness of our method on different medical imaging modalities.
A review of uncertainty quantification in medical image analysis: probabilistic and non-probabilistic methods
Oct 09, 2023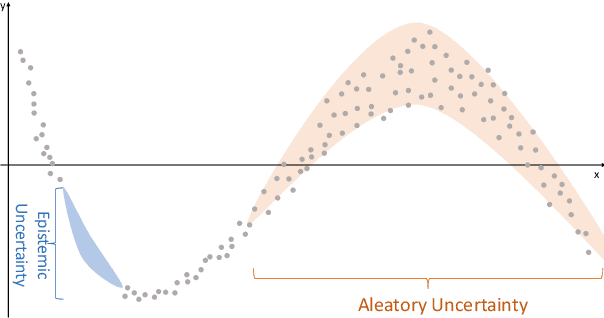
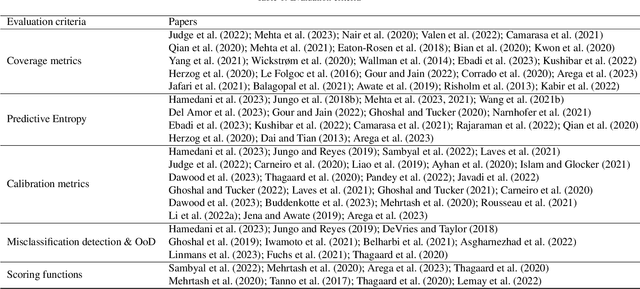
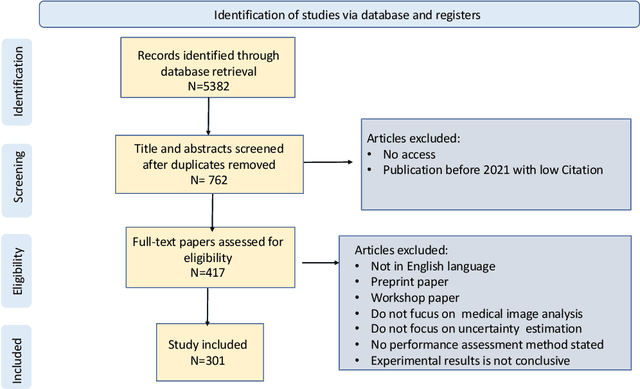
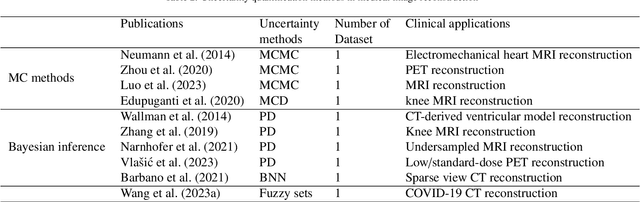
The comprehensive integration of machine learning healthcare models within clinical practice remains suboptimal, notwithstanding the proliferation of high-performing solutions reported in the literature. A predominant factor hindering widespread adoption pertains to an insufficiency of evidence affirming the reliability of the aforementioned models. Recently, uncertainty quantification methods have been proposed as a potential solution to quantify the reliability of machine learning models and thus increase the interpretability and acceptability of the result. In this review, we offer a comprehensive overview of prevailing methods proposed to quantify uncertainty inherent in machine learning models developed for various medical image tasks. Contrary to earlier reviews that exclusively focused on probabilistic methods, this review also explores non-probabilistic approaches, thereby furnishing a more holistic survey of research pertaining to uncertainty quantification for machine learning models. Analysis of medical images with the summary and discussion on medical applications and the corresponding uncertainty evaluation protocols are presented, which focus on the specific challenges of uncertainty in medical image analysis. We also highlight some potential future research work at the end. Generally, this review aims to allow researchers from both clinical and technical backgrounds to gain a quick and yet in-depth understanding of the research in uncertainty quantification for medical image analysis machine learning models.