 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative Hamiltonian Variational Autoencoder for Accurate Tumor Segmentation in Data-Scarce Regimes
Jun 17, 2024



Deep learning has gained significant attention in medical image segmentation. However, the limited availability of annotated training data presents a challenge to achieving accurate results. In efforts to overcome this challenge, data augmentation techniques have been proposed. However, the majority of these approaches primarily focus on image generation. For segmentation tasks, providing both images and their corresponding target masks is crucial, and the generation of diverse and realistic samples remains a complex task, especially when working with limited training datasets. To this end, we propose a new end-to-end hybrid architecture based on Hamiltonian Variational Autoencoders (HVAE) and a discriminative regularization to improve the quality of generated images. Our method provides an accuracte estimation of the joint distribution of the images and masks, resulting in the generation of realistic medical images with reduced artifacts and off-distribution instances. As generating 3D volumes requires substantial time and memory, our architecture operates on a slice-by-slice basis to segment 3D volumes, capitilizing on the richly augmented dataset. Experiments conducted on two public datasets, BRATS (MRI modality) and HECKTOR (PET modality), demonstrate the efficacy of our proposed method on different medical imaging modalities with limited data.
3D MRI Synthesis with Slice-Based Latent Diffusion Models: Improving Tumor Segmentation Tasks in Data-Scarce Regimes
Jun 08, 2024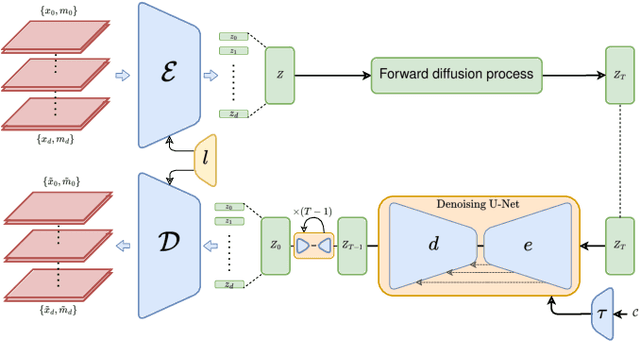
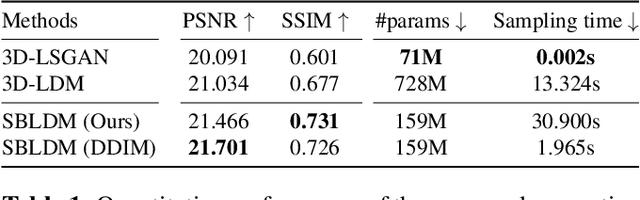
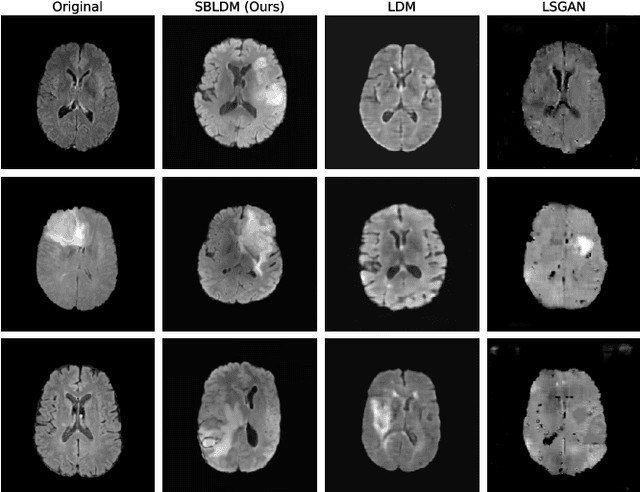
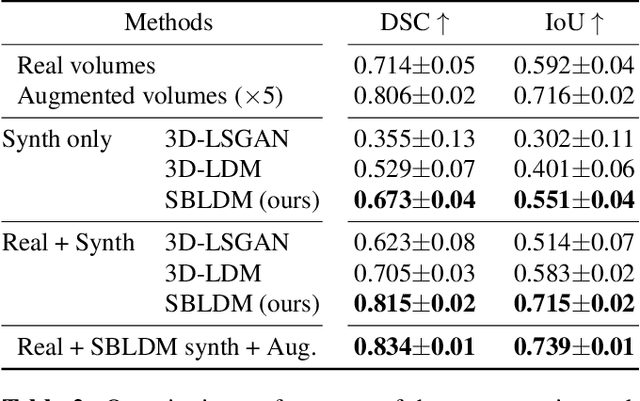
Despite the increasing use of deep learning in medical image segmentation, the limited availability of annotated training data remains a major challenge due to the time-consuming data acquisition and privacy regulations. In the context of segmentation tasks, providing both medical images and their corresponding target masks is essential. However, conventional data augmentation approaches mainly focus on image synthesis. In this study, we propose a novel slice-based latent diffusion architecture designed to address the complexities of volumetric data generation in a slice-by-slice fashion. This approach extends the joint distribution modeling of medical images and their associated masks, allowing a simultaneous generation of both under data-scarce regimes. Our approach mitigates the computational complexity and memory expensiveness typically associated with diffusion models. Furthermore, our architecture can be conditioned by tumor characteristics, including size, shape, and relative position, thereby providing a diverse range of tumor variations. Experiments on a segmentation task using the BRATS2022 confirm the effectiveness of the synthesized volumes and masks for data augmentation.
End-to-end autoencoding architecture for the simultaneous generation of medical images and corresponding segmentation masks
Nov 17, 2023Despite the increasing use of deep learning in medical image segmentation, acquiring sufficient training data remains a challenge in the medical field. In response, data augmentation techniques have been proposed; however, the generation of diverse and realistic medical images and their corresponding masks remains a difficult task, especially when working with insufficient training sets. To address these limitations, we present an end-to-end architecture based on the Hamiltonian Variational Autoencoder (HVAE). This approach yields an improved posterior distribution approximation compared to traditional Variational Autoencoders (VAE), resulting in higher image generation quality. Our method outperforms generative adversarial architectures under data-scarce conditions, showcasing enhancements in image quality and precise tumor mask synthesis. We conduct experiments on two publicly available datasets, MICCAI's Brain Tumor Segmentation Challenge (BRATS), and Head and Neck Tumor Segmentation Challenge (HECKTOR), demonstrating the effectiveness of our method on different medical imaging modalities.
Deep Learning Approaches for Data Augmentation in Medical Imaging: A Review
Jul 24, 2023Deep learning has become a popular tool for medical image analysis, but the limited availability of training data remains a major challenge, particularly in the medical field where data acquisition can be costly and subject to privacy regulations. Data augmentation techniques offer a solution by artificially increasing the number of training samples, but these techniques often produce limited and unconvincing results. To address this issue, a growing number of studies have proposed the use of deep generative models to generate more realistic and diverse data that conform to the true distribution of the data. In this review, we focus on three types of deep generative models for medical image augmentation: variational autoencoders, generative adversarial networks, and diffusion models. We provide an overview of the current state of the art in each of these models and discuss their potential for use in different downstream tasks in medical imaging, including classification, segmentation, and cross-modal translation. We also evaluate the strengths and limitations of each model and suggest directions for future research in this field. Our goal is to provide a comprehensive review about the use of deep generative models for medical image augmentation and to highlight the potential of these models for improving the performance of deep learning algorithms in medical image analysis.