 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeform-Mamba Network for MRI Super-Resolution
Paper and Code
Jul 08, 2024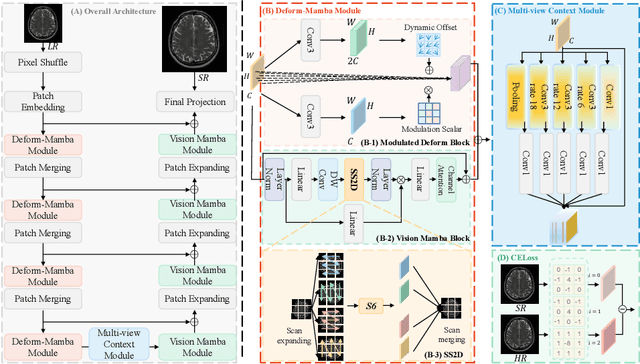
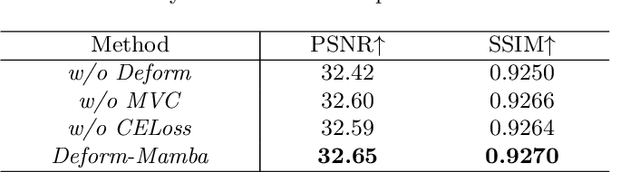
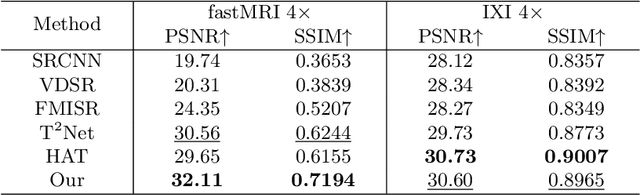
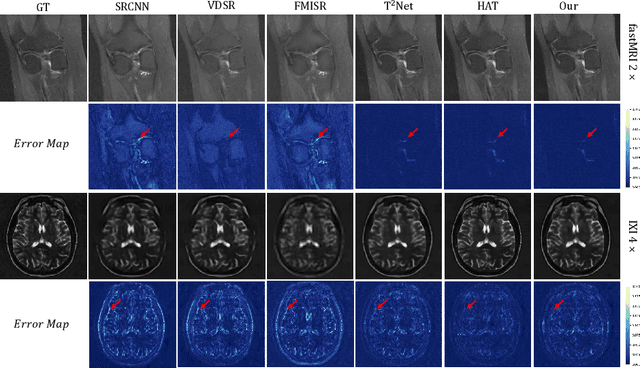
In this paper, we propose a new architecture, called Deform-Mamba, for MR image super-resolution. Unlike conventional CNN or Transformer-based super-resolution approaches which encounter challenges related to the local respective field or heavy computational cost, our approach aims to effectively explore the local and global information of images. Specifically, we develop a Deform-Mamba encoder which is composed of two branches, modulated deform block and vision Mamba block. We also design a multi-view context module in the bottleneck layer to explore the multi-view contextual content. Thanks to the extracted features of the encoder, which include content-adaptive local and efficient global information, the vision Mamba decoder finally generates high-quality MR images. Moreover, we introduce a contrastive edge loss to promote the reconstruction of edge and contrast related content. Quantitative and qualitative experimental results indicate that our approach on IXI and fastMRI datasets achieves competitive performance.