 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAS-Mamba: Phase-Amplitude-Spatial State Space Model for MRI Reconstruction
Jan 20, 2026Joint feature modeling in both the spatial and frequency domains has become a mainstream approach in MRI reconstruction. However, existing methods generally treat the frequency domain as a whole, neglecting the differences in the information carried by its internal components. According to Fourier transform theory, phase and amplitude represent different types of information in the image. Our spectrum swapping experiments show that magnitude mainly reflects pixel-level intensity, while phase predominantly governs image structure. To prevent interference between phase and magnitude feature learning caused by unified frequency-domain modeling, we propose the Phase-Amplitude-Spatial State Space Model (PAS-Mamba) for MRI Reconstruction, a framework that decouples phase and magnitude modeling in the frequency domain and combines it with image-domain features for better reconstruction. In the image domain, LocalMamba preserves spatial locality to sharpen fine anatomical details. In frequency domain, we disentangle amplitude and phase into two specialized branches to avoid representational coupling. To respect the concentric geometry of frequency information, we propose Circular Frequency Domain Scanning (CFDS) to serialize features from low to high frequencies. Finally, a Dual-Domain Complementary Fusion Module (DDCFM) adaptively fuses amplitude phase representations and enables bidirectional exchange between frequency and image domains, delivering superior reconstruction. Extensive experiments on the IXI and fastMRI knee datasets show that PAS-Mamba consistently outperforms state of the art reconstruction methods.
TFKAN: Time-Frequency KAN for Long-Term Time Series Forecasting
Jun 15, 2025Kolmogorov-Arnold Networks (KANs) are highly effective in long-term time series forecasting due to their ability to efficiently represent nonlinear relationships and exhibit local plasticity. However, prior research on KANs has predominantly focused on the time domain, neglecting the potential of the frequency domain. The frequency domain of time series data reveals recurring patterns and periodic behaviors, which complement the temporal information captured in the time domain. To address this gap, we explore the application of KANs in the frequency domain for long-term time series forecasting. By leveraging KANs' adaptive activation functions and their comprehensive representation of signals in the frequency domain, we can more effectively learn global dependencies and periodic patterns. To integrate information from both time and frequency domains, we propose the $\textbf{T}$ime-$\textbf{F}$requency KAN (TFKAN). TFKAN employs a dual-branch architecture that independently processes features from each domain, ensuring that the distinct characteristics of each domain are fully utilized without interference. Additionally, to account for the heterogeneity between domains, we introduce a dimension-adjustment strategy that selectively upscales only in the frequency domain, enhancing efficiency while capturing richer frequency information. Experimental results demonstrate that TFKAN consistently outperforms state-of-the-art (SOTA) methods across multiple datasets. The code is available at https://github.com/LcWave/TFKAN.
Mamba Based Feature Extraction And Adaptive Multilevel Feature Fusion For 3D Tumor Segmentation From Multi-modal Medical Image
Apr 30, 2025Multi-modal 3D medical image segmentation aims to accurately identify tumor regions across different modalities, facing challenges from variations in image intensity and tumor morphology. Traditional convolutional neural network (CNN)-based methods struggle with capturing global features, while Transformers-based methods, despite effectively capturing global context, encounter high computational costs in 3D medical image segmentation. The Mamba model combines linear scalability with long-distance modeling, making it a promising approach for visual representation learning. However, Mamba-based 3D multi-modal segmentation still struggles to leverage modality-specific features and fuse complementary information effectively. In this paper, we propose a Mamba based feature extraction and adaptive multilevel feature fusion for 3D tumor segmentation using multi-modal medical image. We first develop the specific modality Mamba encoder to efficiently extract long-range relevant features that represent anatomical and pathological structures present in each modality. Moreover, we design an bi-level synergistic integration block that dynamically merges multi-modal and multi-level complementary features by the modality attention and channel attention learning. Lastly, the decoder combines deep semantic information with fine-grained details to generate the tumor segmentation map. Experimental results on medical image datasets (PET/CT and MRI multi-sequence) show that our approach achieve competitive performance compared to the state-of-the-art CNN, Transformer, and Mamba-based approaches.
Iterative Collaboration Network Guided By Reconstruction Prior for Medical Image Super-Resolution
Apr 23, 2025High-resolution medical images can provide more detailed information for better diagnosis. Conventional medical image super-resolution relies on a single task which first performs the extraction of the features and then upscaling based on the features. The features extracted may not be complete for super-resolution. Recent multi-task learning,including reconstruction and super-resolution, is a good solution to obtain additional relevant information. The interaction between the two tasks is often insufficient, which still leads to incomplete and less relevant deep features. To address above limitations, we propose an iterative collaboration network (ICONet) to improve communications between tasks by progressively incorporating reconstruction prior to the super-resolution learning procedure in an iterative collaboration way. It consists of a reconstruction branch, a super-resolution branch, and a SR-Rec fusion module. The reconstruction branch generates the artifact-free image as prior, which is followed by a super-resolution branch for prior knowledge-guided super-resolution. Unlike the widely-used convolutional neural networks for extracting local features and Transformers with quadratic computational complexity for modeling long-range dependencies, we develop a new residual spatial-channel feature learning (RSCFL) module of two branches to efficiently establish feature relationships in spatial and channel dimensions. Moreover, the designed SR-Rec fusion module fuses the reconstruction prior and super-resolution features with each other in an adaptive manner. Our ICONet is built with multi-stage models to iteratively upscale the low-resolution images using steps of 2x and simultaneously interact between two branches in multi-stage supervisions.
Global and Local Mamba Network for Multi-Modality Medical Image Super-Resolution
Apr 14, 2025Convolutional neural networks and Transformer have made significant progresses in multi-modality medical image super-resolution. However, these methods either have a fixed receptive field for local learning or significant computational burdens for global learning, limiting the super-resolution performance. To solve this problem, State Space Models, notably Mamba, is introduced to efficiently model long-range dependencies in images with linear computational complexity. Relying on the Mamba and the fact that low-resolution images rely on global information to compensate for missing details, while high-resolution reference images need to provide more local details for accurate super-resolution, we propose a global and local Mamba network (GLMamba) for multi-modality medical image super-resolution. To be specific, our GLMamba is a two-branch network equipped with a global Mamba branch and a local Mamba branch. The global Mamba branch captures long-range relationships in low-resolution inputs, and the local Mamba branch focuses more on short-range details in high-resolution reference images. We also use the deform block to adaptively extract features of both branches to enhance the representation ability. A modulator is designed to further enhance deformable features in both global and local Mamba blocks. To fully integrate the reference image for low-resolution image super-resolution, we further develop a multi-modality feature fusion block to adaptively fuse features by considering similarities, differences, and complementary aspects between modalities. In addition, a contrastive edge loss (CELoss) is developed for sufficient enhancement of edge textures and contrast in medical images.
A Comprehensive Survey on Magnetic Resonance Image Reconstruction
Mar 10, 2025

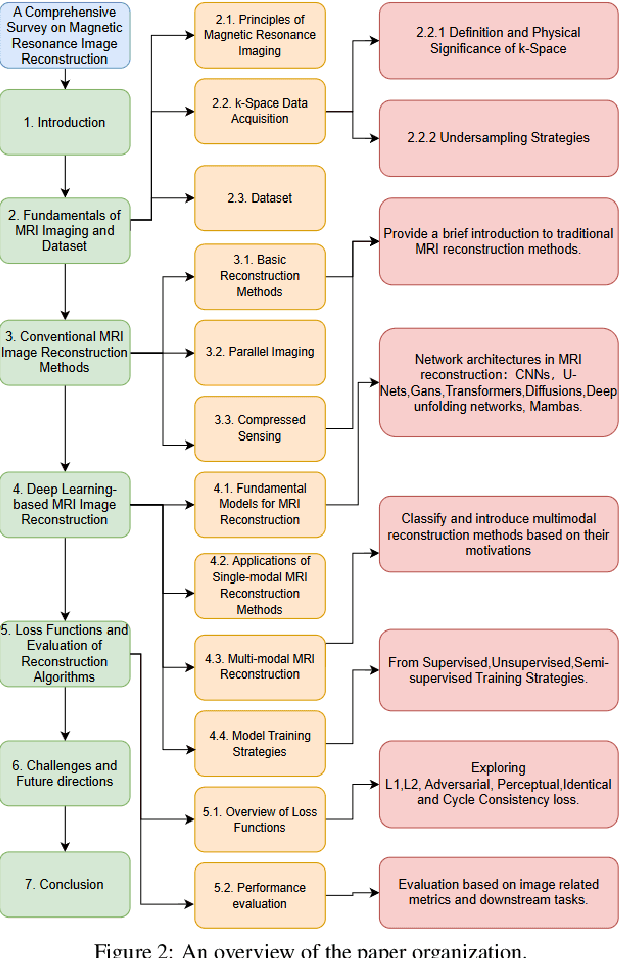

Magnetic resonance imaging (MRI) reconstruction is a fundamental task aimed at recovering high-quality images from undersampled or low-quality MRI data. This process enhances diagnostic accuracy and optimizes clinical applications. In recent years, deep learning-based MRI reconstruction has made significant progress. Advancements include single-modality feature extraction using different network architectures, the integration of multimodal information, and the adoption of unsupervised or semi-supervised learning strategies. However, despite extensive research, MRI reconstruction remains a challenging problem that has yet to be fully resolved. This survey provides a systematic review of MRI reconstruction methods, covering key aspects such as data acquisition and preprocessing, publicly available datasets, single and multi-modal reconstruction models, training strategies, and evaluation metrics based on image reconstruction and downstream tasks. Additionally, we analyze the major challenges in this field and explore potential future directions.
Self-Prior Guided Mamba-UNet Networks for Medical Image Super-Resolution
Jul 08, 2024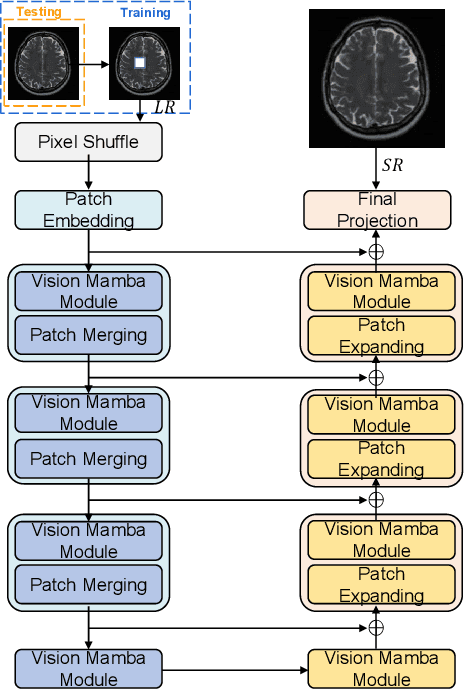
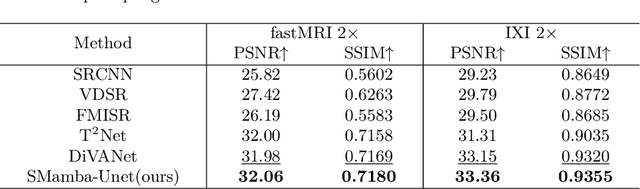
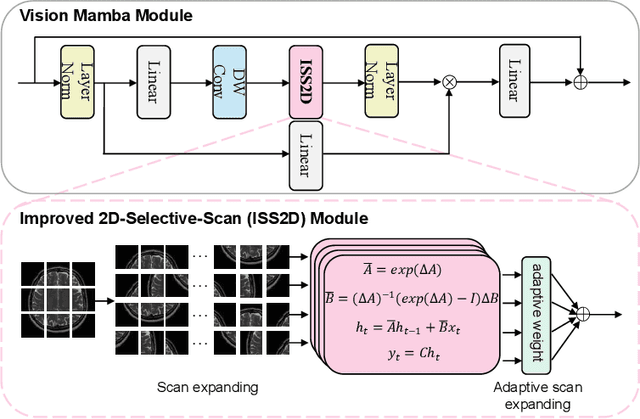
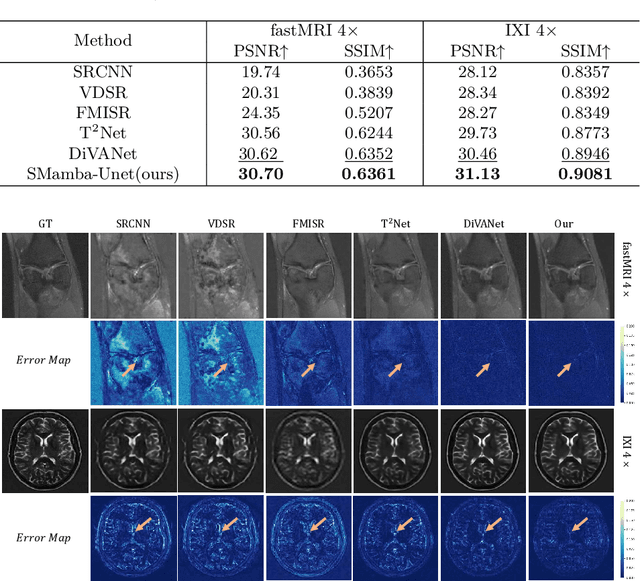
In this paper, we propose a self-prior guided Mamba-UNet network (SMamba-UNet) for medical image super-resolution. Existing methods are primarily based on convolutional neural networks (CNNs) or Transformers. CNNs-based methods fail to capture long-range dependencies, while Transformer-based approaches face heavy calculation challenges due to their quadratic computational complexity. Recently, State Space Models (SSMs) especially Mamba have emerged, capable of modeling long-range dependencies with linear computational complexity. Inspired by Mamba, our approach aims to learn the self-prior multi-scale contextual features under Mamba-UNet networks, which may help to super-resolve low-resolution medical images in an efficient way. Specifically, we obtain self-priors by perturbing the brightness inpainting of the input image during network training, which can learn detailed texture and brightness information that is beneficial for super-resolution. Furthermore, we combine Mamba with Unet network to mine global features at different levels. We also design an improved 2D-Selective-Scan (ISS2D) module to divide image features into different directional sequences to learn long-range dependencies in multiple directions, and adaptively fuse sequence information to enhance super-resolved feature representation. Both qualitative and quantitative experimental results demonstrate that our approach outperforms current state-of-the-art methods on two public medical datasets: the IXI and fastMRI.
Deform-Mamba Network for MRI Super-Resolution
Jul 08, 2024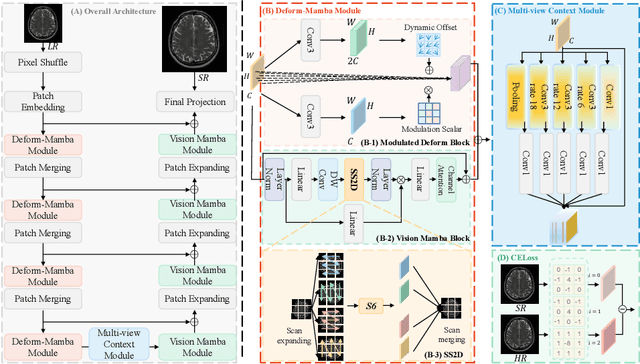
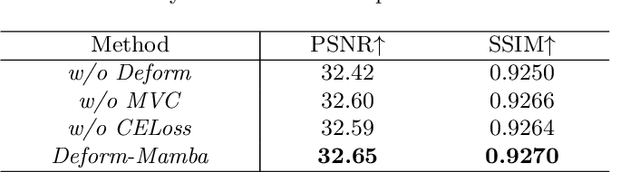
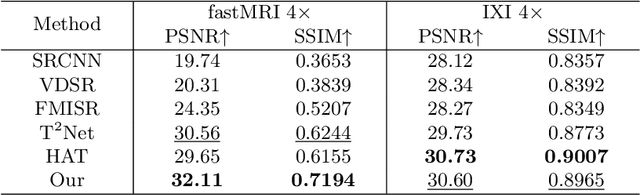
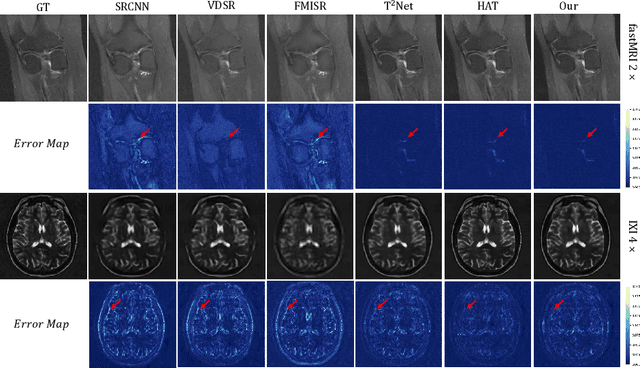
In this paper, we propose a new architecture, called Deform-Mamba, for MR image super-resolution. Unlike conventional CNN or Transformer-based super-resolution approaches which encounter challenges related to the local respective field or heavy computational cost, our approach aims to effectively explore the local and global information of images. Specifically, we develop a Deform-Mamba encoder which is composed of two branches, modulated deform block and vision Mamba block. We also design a multi-view context module in the bottleneck layer to explore the multi-view contextual content. Thanks to the extracted features of the encoder, which include content-adaptive local and efficient global information, the vision Mamba decoder finally generates high-quality MR images. Moreover, we introduce a contrastive edge loss to promote the reconstruction of edge and contrast related content. Quantitative and qualitative experimental results indicate that our approach on IXI and fastMRI datasets achieves competitive performance.
ChebMixer: Efficient Graph Representation Learning with MLP Mixer
Mar 25, 2024Graph neural networks have achieved remarkable success in learning graph representations, especially graph Transformer, which has recently shown superior performance on various graph mining tasks. However, graph Transformer generally treats nodes as tokens, which results in quadratic complexity regarding the number of nodes during self-attention computation. The graph MLP Mixer addresses this challenge by using the efficient MLP Mixer technique from computer vision. However, the time-consuming process of extracting graph tokens limits its performance. In this paper, we present a novel architecture named ChebMixer, a newly graph MLP Mixer that uses fast Chebyshev polynomials-based spectral filtering to extract a sequence of tokens. Firstly, we produce multiscale representations of graph nodes via fast Chebyshev polynomial-based spectral filtering. Next, we consider each node's multiscale representations as a sequence of tokens and refine the node representation with an effective MLP Mixer. Finally, we aggregate the multiscale representations of nodes through Chebyshev interpolation. Owing to the powerful representation capabilities and fast computational properties of MLP Mixer, we can quickly extract more informative node representations to improve the performance of downstream tasks. The experimental results prove our significant improvements in a variety of scenarios ranging from graph node classification to medical image segmentation.
Improving Neural Radiance Fields with Depth-aware Optimization for Novel View Synthesis
Apr 11, 2023



With dense inputs, Neural Radiance Fields (NeRF) is able to render photo-realistic novel views under static conditions. Although the synthesis quality is excellent, existing NeRF-based methods fail to obtain moderate three-dimensional (3D) structures. The novel view synthesis quality drops dramatically given sparse input due to the implicitly reconstructed inaccurate 3D-scene structure. We propose SfMNeRF, a method to better synthesize novel views as well as reconstruct the 3D-scene geometry. SfMNeRF leverages the knowledge from the self-supervised depth estimation methods to constrain the 3D-scene geometry during view synthesis training. Specifically, SfMNeRF employs the epipolar, photometric consistency, depth smoothness, and position-of-matches constraints to explicitly reconstruct the 3D-scene structure. Through these explicit constraints and the implicit constraint from NeRF, our method improves the view synthesis as well as the 3D-scene geometry performance of NeRF at the same time. In addition, SfMNeRF synthesizes novel sub-pixels in which the ground truth is obtained by image interpolation. This strategy enables SfMNeRF to include more samples to improve generalization performance. Experiments on two public datasets demonstrate that SfMNeRF surpasses state-of-the-art approaches. Code is available at https://github.com/XTU-PR-LAB/SfMNeRF