 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Aware NeRF without Posed Camera via Epipolar Constraint
Paper and Code
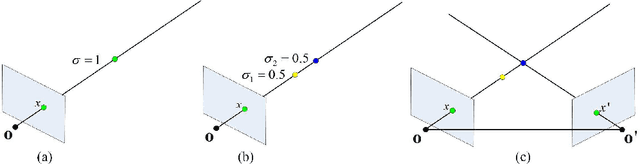
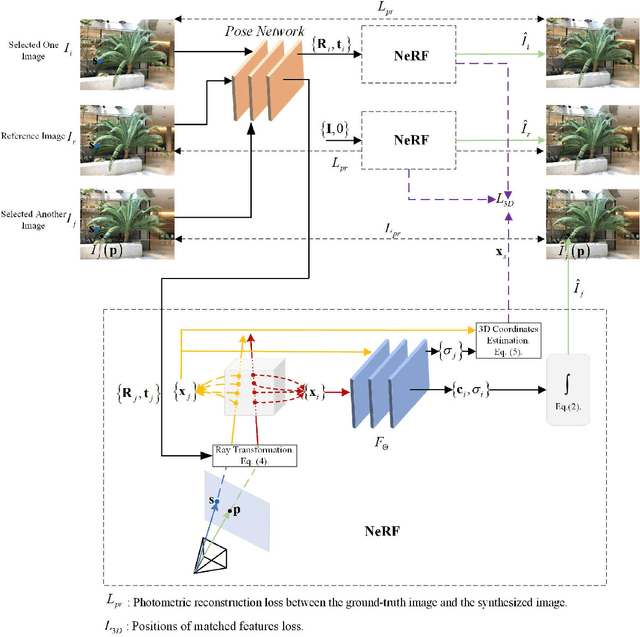


The neural radiance field (NeRF) for realistic novel view synthesis requires camera poses to be pre-acquired by a structure-from-motion (SfM) approach. This two-stage strategy is not convenient to use and degrades the performance because the error in the pose extraction can propagate to the view synthesis. We integrate the pose extraction and view synthesis into a single end-to-end procedure so they can benefit from each other. For training NeRF models, only RGB images are given, without pre-known camera poses. The camera poses are obtained by the epipolar constraint in which the identical feature in different views has the same world coordinates transformed from the local camera coordinates according to the extracted poses. The epipolar constraint is jointly optimized with pixel color constraint. The poses are represented by a CNN-based deep network, whose input is the related frames. This joint optimization enables NeRF to be aware of the scene's structure that has an improved generalization performance. Extensive experiments on a variety of scenes demonstrate the effectiveness of the proposed approach. Code is available at https://github.com/XTU-PR-LAB/SaNerf.