 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-shot Face Sketch Synthesis in the Wild via Generative Diffusion Prior and Instruction Tuning
Jun 18, 2025
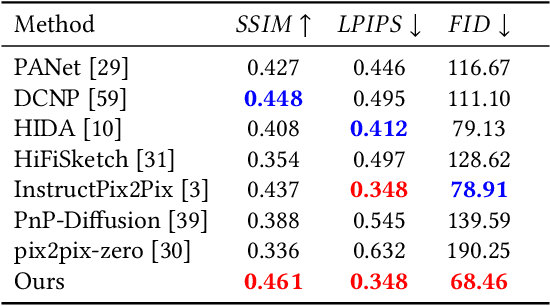


Face sketch synthesis is a technique aimed at converting face photos into sketches. Existing face sketch synthesis research mainly relies on training with numerous photo-sketch sample pairs from existing datasets. However, these large-scale discriminative learning methods will have to face problems such as data scarcity and high human labor costs. Once the training data becomes scarce, their generative performance significantly degrades. In this paper, we propose a one-shot face sketch synthesis method based on diffusion models. We optimize text instructions on a diffusion model using face photo-sketch image pairs. Then, the instructions derived through gradient-based optimization are used for inference. To simulate real-world scenarios more accurately and evaluate method effectiveness more comprehensively, we introduce a new benchmark named One-shot Face Sketch Dataset (OS-Sketch). The benchmark consists of 400 pairs of face photo-sketch images, including sketches with different styles and photos with different backgrounds, ages, sexes, expressions, illumination, etc. For a solid out-of-distribution evaluation, we select only one pair of images for training at each time, with the rest used for inference. Extensive experiments demonstrate that the proposed method can convert various photos into realistic and highly consistent sketches in a one-shot context. Compared to other methods, our approach offers greater convenience and broader applicability. The dataset will be available at: https://github.com/HanWu3125/OS-Sketch
Improving Neural Radiance Fields with Depth-aware Optimization for Novel View Synthesis
Apr 11, 2023



With dense inputs, Neural Radiance Fields (NeRF) is able to render photo-realistic novel views under static conditions. Although the synthesis quality is excellent, existing NeRF-based methods fail to obtain moderate three-dimensional (3D) structures. The novel view synthesis quality drops dramatically given sparse input due to the implicitly reconstructed inaccurate 3D-scene structure. We propose SfMNeRF, a method to better synthesize novel views as well as reconstruct the 3D-scene geometry. SfMNeRF leverages the knowledge from the self-supervised depth estimation methods to constrain the 3D-scene geometry during view synthesis training. Specifically, SfMNeRF employs the epipolar, photometric consistency, depth smoothness, and position-of-matches constraints to explicitly reconstruct the 3D-scene structure. Through these explicit constraints and the implicit constraint from NeRF, our method improves the view synthesis as well as the 3D-scene geometry performance of NeRF at the same time. In addition, SfMNeRF synthesizes novel sub-pixels in which the ground truth is obtained by image interpolation. This strategy enables SfMNeRF to include more samples to improve generalization performance. Experiments on two public datasets demonstrate that SfMNeRF surpasses state-of-the-art approaches. Code is available at https://github.com/XTU-PR-LAB/SfMNeRF