 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Bias Assessment in AI-Generated Educational Content Using CEAT Framework
May 19, 2025Recent advances in Generative Artificial Intelligence (GenAI) have transformed educational content creation, particularly in developing tutor training materials. However, biases embedded in AI-generated content--such as gender, racial, or national stereotypes--raise significant ethical and educational concerns. Despite the growing use of GenAI, systematic methods for detecting and evaluating such biases in educational materials remain limited. This study proposes an automated bias assessment approach that integrates the Contextualized Embedding Association Test with a prompt-engineered word extraction method within a Retrieval-Augmented Generation framework. We applied this method to AI-generated texts used in tutor training lessons. Results show a high alignment between the automated and manually curated word sets, with a Pearson correlation coefficient of r = 0.993, indicating reliable and consistent bias assessment. Our method reduces human subjectivity and enhances fairness, scalability, and reproducibility in auditing GenAI-produced educational content.
DI-Retinex: Digital-Imaging Retinex Theory for Low-Light Image Enhancement
Apr 04, 2024



Many existing methods for low-light image enhancement (LLIE) based on Retinex theory ignore important factors that affect the validity of this theory in digital imaging, such as noise, quantization error, non-linearity, and dynamic range overflow. In this paper, we propose a new expression called Digital-Imaging Retinex theory (DI-Retinex) through theoretical and experimental analysis of Retinex theory in digital imaging. Our new expression includes an offset term in the enhancement model, which allows for pixel-wise brightness contrast adjustment with a non-linear mapping function. In addition, to solve the lowlight enhancement problem in an unsupervised manner, we propose an image-adaptive masked reverse degradation loss in Gamma space. We also design a variance suppression loss for regulating the additional offset term. Extensive experiments show that our proposed method outperforms all existing unsupervised methods in terms of visual quality, model size, and speed. Our algorithm can also assist downstream face detectors in low-light, as it shows the most performance gain after the low-light enhancement compared to other methods.
Reversed Image Signal Processing and RAW Reconstruction. AIM 2022 Challenge Report
Oct 20, 2022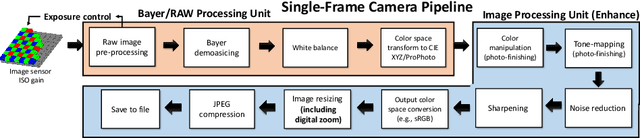
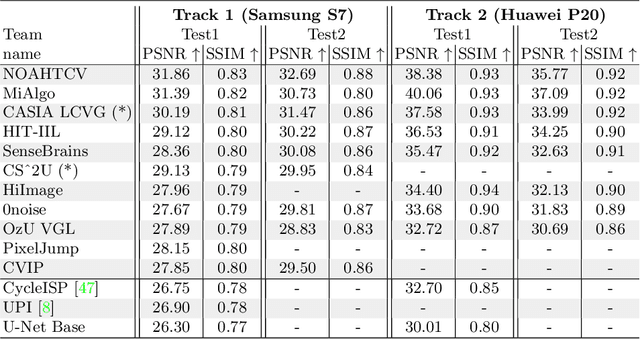
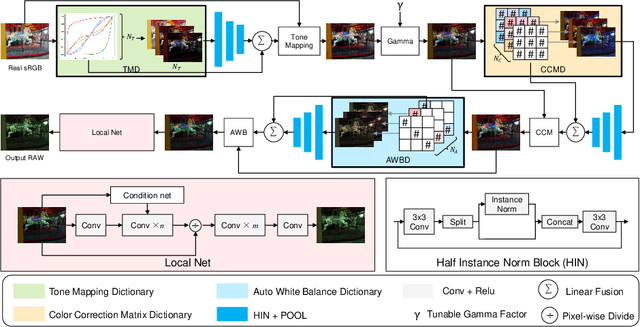
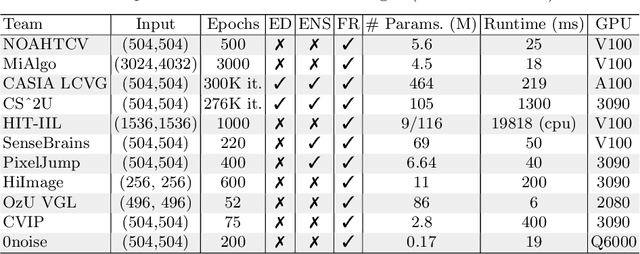
Cameras capture sensor RAW images and transform them into pleasant RGB images, suitable for the human eyes, using their integrated Image Signal Processor (ISP). Numerous low-level vision tasks operate in the RAW domain (e.g. image denoising, white balance) due to its linear relationship with the scene irradiance, wide-range of information at 12bits, and sensor designs. Despite this, RAW image datasets are scarce and more expensive to collect than the already large and public RGB datasets. This paper introduces the AIM 2022 Challenge on Reversed Image Signal Processing and RAW Reconstruction. We aim to recover raw sensor images from the corresponding RGBs without metadata and, by doing this, "reverse" the ISP transformation. The proposed methods and benchmark establish the state-of-the-art for this low-level vision inverse problem, and generating realistic raw sensor readings can potentially benefit other tasks such as denoising and super-resolution.
Real-time Image Enhancer via Learnable Spatial-aware 3D Lookup Tables
Aug 19, 2021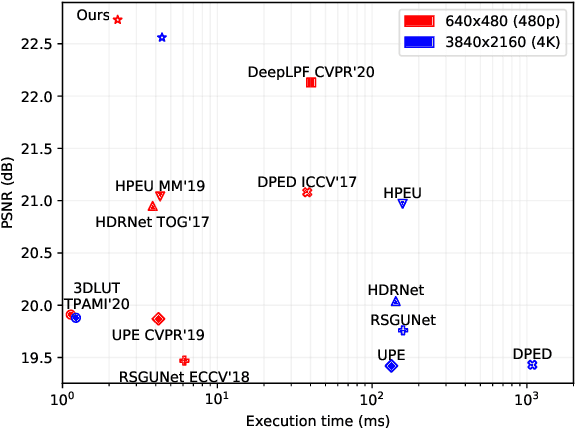
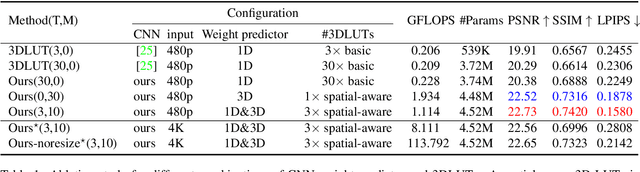
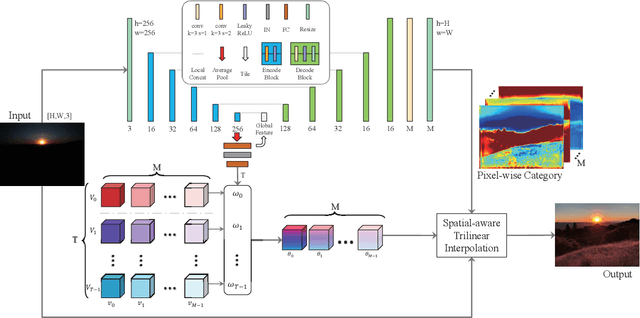
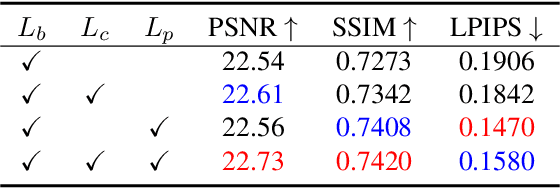
Recently, deep learning-based image enhancement algorithms achieved state-of-the-art (SOTA) performance on several publicly available datasets. However, most existing methods fail to meet practical requirements either for visual perception or for computation efficiency, especially for high-resolution images. In this paper, we propose a novel real-time image enhancer via learnable spatial-aware 3-dimentional lookup tables(3D LUTs), which well considers global scenario and local spatial information. Specifically, we introduce a light weight two-head weight predictor that has two outputs. One is a 1D weight vector used for image-level scenario adaptation, the other is a 3D weight map aimed for pixel-wise category fusion. We learn the spatial-aware 3D LUTs and fuse them according to the aforementioned weights in an end-to-end manner. The fused LUT is then used to transform the source image into the target tone in an efficient way. Extensive results show that our model outperforms SOTA image enhancement methods on public datasets both subjectively and objectively, and that our model only takes about 4ms to process a 4K resolution image on one NVIDIA V100 GPU.
Learned Smartphone ISP on Mobile NPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021
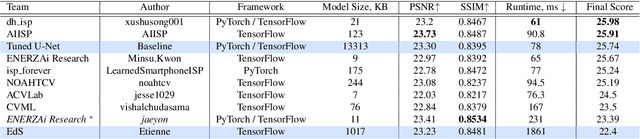
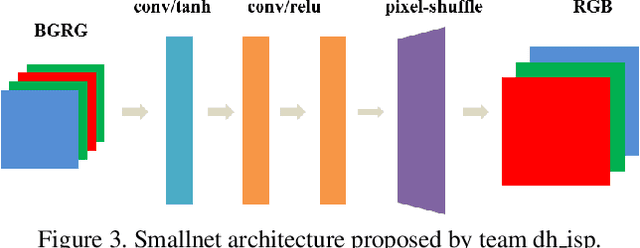
As the quality of mobile cameras starts to play a crucial role in modern smartphones, more and more attention is now being paid to ISP algorithms used to improve various perceptual aspects of mobile photos. In this Mobile AI challenge, the target was to develop an end-to-end deep learning-based image signal processing (ISP) pipeline that can replace classical hand-crafted ISPs and achieve nearly real-time performance on smartphone NPUs. For this, the participants were provided with a novel learned ISP dataset consisting of RAW-RGB image pairs captured with the Sony IMX586 Quad Bayer mobile sensor and a professional 102-megapixel medium format camera. The runtime of all models was evaluated on the MediaTek Dimensity 1000+ platform with a dedicated AI processing unit capable of accelerating both floating-point and quantized neural networks. The proposed solutions are fully compatible with the above NPU and are capable of processing Full HD photos under 60-100 milliseconds while achieving high fidelity results. A detailed description of all models developed in this challenge is provided in this paper.