 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Agents: A Co-Design of Inference Architecture and System
Dec 20, 2025The rapid development of large language model (LLM)-based agents has unlocked new possibilities for autonomous multi-turn reasoning and tool-augmented decision-making. However, their real-world deployment is hindered by severe inefficiencies that arise not from isolated model inference, but from the systemic latency accumulated across reasoning loops, context growth, and heterogeneous tool interactions. This paper presents AgentInfer, a unified framework for end-to-end agent acceleration that bridges inference optimization and architectural design. We decompose the problem into four synergistic components: AgentCollab, a hierarchical dual-model reasoning framework that balances large- and small-model usage through dynamic role assignment; AgentSched, a cache-aware hybrid scheduler that minimizes latency under heterogeneous request patterns; AgentSAM, a suffix-automaton-based speculative decoding method that reuses multi-session semantic memory to achieve low-overhead inference acceleration; and AgentCompress, a semantic compression mechanism that asynchronously distills and reorganizes agent memory without disrupting ongoing reasoning. Together, these modules form a Self-Evolution Engine capable of sustaining efficiency and cognitive stability throughout long-horizon reasoning tasks. Experiments on the BrowseComp-zh and DeepDiver benchmarks demonstrate that through the synergistic collaboration of these methods, AgentInfer reduces ineffective token consumption by over 50%, achieving an overall 1.8-2.5 times speedup with preserved accuracy. These results underscore that optimizing for agentic task completion-rather than merely per-token throughput-is the key to building scalable, efficient, and self-improving intelligent systems.
EditMGT: Unleashing Potentials of Masked Generative Transformers in Image Editing
Dec 12, 2025Recent advances in diffusion models (DMs) have achieved exceptional visual quality in image editing tasks. However, the global denoising dynamics of DMs inherently conflate local editing targets with the full-image context, leading to unintended modifications in non-target regions. In this paper, we shift our attention beyond DMs and turn to Masked Generative Transformers (MGTs) as an alternative approach to tackle this challenge. By predicting multiple masked tokens rather than holistic refinement, MGTs exhibit a localized decoding paradigm that endows them with the inherent capacity to explicitly preserve non-relevant regions during the editing process. Building upon this insight, we introduce the first MGT-based image editing framework, termed EditMGT. We first demonstrate that MGT's cross-attention maps provide informative localization signals for localizing edit-relevant regions and devise a multi-layer attention consolidation scheme that refines these maps to achieve fine-grained and precise localization. On top of these adaptive localization results, we introduce region-hold sampling, which restricts token flipping within low-attention areas to suppress spurious edits, thereby confining modifications to the intended target regions and preserving the integrity of surrounding non-target areas. To train EditMGT, we construct CrispEdit-2M, a high-resolution dataset spanning seven diverse editing categories. Without introducing additional parameters, we adapt a pre-trained text-to-image MGT into an image editing model through attention injection. Extensive experiments across four standard benchmarks demonstrate that, with fewer than 1B parameters, our model achieves similarity performance while enabling 6 times faster editing. Moreover, it delivers comparable or superior editing quality, with improvements of 3.6% and 17.6% on style change and style transfer tasks, respectively.
Valley2: Exploring Multimodal Models with Scalable Vision-Language Design
Jan 13, 2025



Recently, vision-language models have made remarkable progress, demonstrating outstanding capabilities in various tasks such as image captioning and video understanding. We introduce Valley2, a novel multimodal large language model designed to enhance performance across all domains and extend the boundaries of practical applications in e-commerce and short video scenarios. Notably, Valley2 achieves state-of-the-art (SOTA) performance on e-commerce benchmarks, surpassing open-source models of similar size by a large margin (79.66 vs. 72.76). Additionally, Valley2 ranks second on the OpenCompass leaderboard among models with fewer than 10B parameters, with an impressive average score of 67.4. The code and model weights are open-sourced at https://github.com/bytedance/Valley.
LMLPA: Language Model Linguistic Personality Assessment
Oct 23, 2024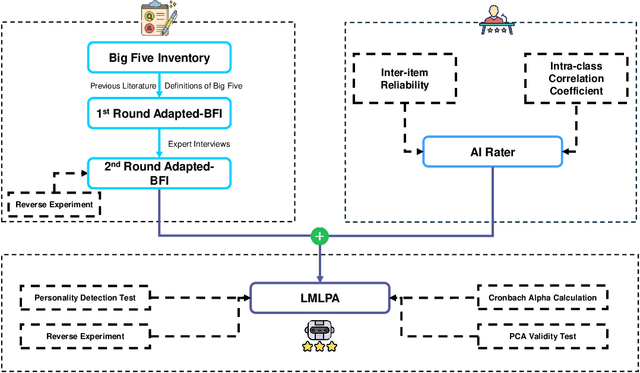


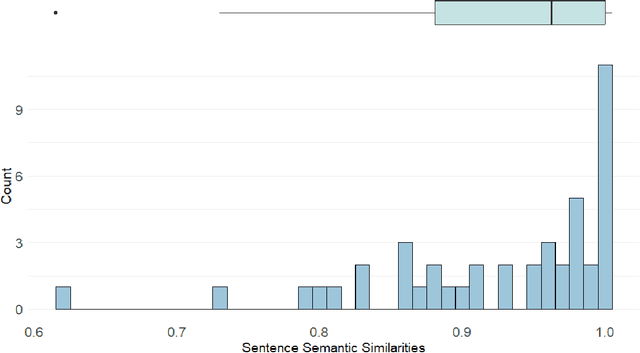
Large Language Models (LLMs) are increasingly used in everyday life and research. One of the most common use cases is conversational interactions, enabled by the language generation capabilities of LLMs. Just as between two humans, a conversation between an LLM-powered entity and a human depends on the personality of the conversants. However, measuring the personality of a given LLM is currently a challenge. This paper introduces the Language Model Linguistic Personality Assessment (LMLPA), a system designed to evaluate the linguistic personalities of LLMs. Our system helps to understand LLMs' language generation capabilities by quantitatively assessing the distinct personality traits reflected in their linguistic outputs. Unlike traditional human-centric psychometrics, the LMLPA adapts a personality assessment questionnaire, specifically the Big Five Inventory, to align with the operational capabilities of LLMs, and also incorporates the findings from previous language-based personality measurement literature. To mitigate sensitivity to the order of options, our questionnaire is designed to be open-ended, resulting in textual answers. Thus, the AI rater is needed to transform ambiguous personality information from text responses into clear numerical indicators of personality traits. Utilising Principal Component Analysis and reliability validations, our findings demonstrate that LLMs possess distinct personality traits that can be effectively quantified by the LMLPA. This research contributes to Human-Computer Interaction and Human-Centered AI, providing a robust framework for future studies to refine AI personality assessments and expand their applications in multiple areas, including education and manufacturing.
Dashing for the Golden Snitch: Multi-Drone Time-Optimal Motion Planning with Multi-Agent Reinforcement Learning
Sep 25, 2024



Recent innovations in autonomous drones have facilitated time-optimal flight in single-drone configurations and enhanced maneuverability in multi-drone systems through the application of optimal control and learning-based methods. However, few studies have achieved time-optimal motion planning for multi-drone systems, particularly during highly agile maneuvers or in dynamic scenarios. This paper presents a decentralized policy network for time-optimal multi-drone flight using multi-agent reinforcement learning. To strike a balance between flight efficiency and collision avoidance, we introduce a soft collision penalty inspired by optimization-based methods. By customizing PPO in a centralized training, decentralized execution (CTDE) fashion, we unlock higher efficiency and stability in training, while ensuring lightweight implementation. Extensive simulations show that, despite slight performance trade-offs compared to single-drone systems, our multi-drone approach maintains near-time-optimal performance with low collision rates. Real-world experiments validate our method, with two quadrotors using the same network as simulation achieving a maximum speed of 13.65 m/s and a maximum body rate of 13.4 rad/s in a 5.5 m * 5.5 m * 2.0 m space across various tracks, relying entirely on onboard computation.
Towards Massive Interaction with Generalist Robotics: A Systematic Review of XR-enabled Remote Human-Robot Interaction Systems
Mar 26, 2024



The rising interest of generalist robots seek to create robots with versatility to handle multiple tasks in a variety of environments, and human will interact with such robots through immersive interfaces. In the context of human-robot interaction (HRI), this survey provides an exhaustive review of the applications of extended reality (XR) technologies in the field of remote HRI. We developed a systematic search strategy based on the PRISMA methodology. From the initial 2,561 articles selected, 100 research papers that met our inclusion criteria were included. We categorized and summarized the domain in detail, delving into XR technologies, including augmented reality (AR), virtual reality (VR), and mixed reality (MR), and their applications in facilitating intuitive and effective remote control and interaction with robotic systems. The survey highlights existing articles on the application of XR technologies, user experience enhancement, and various interaction designs for XR in remote HRI, providing insights into current trends and future directions. We also identified potential gaps and opportunities for future research to improve remote HRI systems through XR technology to guide and inform future XR and robotics research.
VR PreM+ : An Immersive Pre-learning Branching Visualization System for Museum Tours
Nov 01, 2023
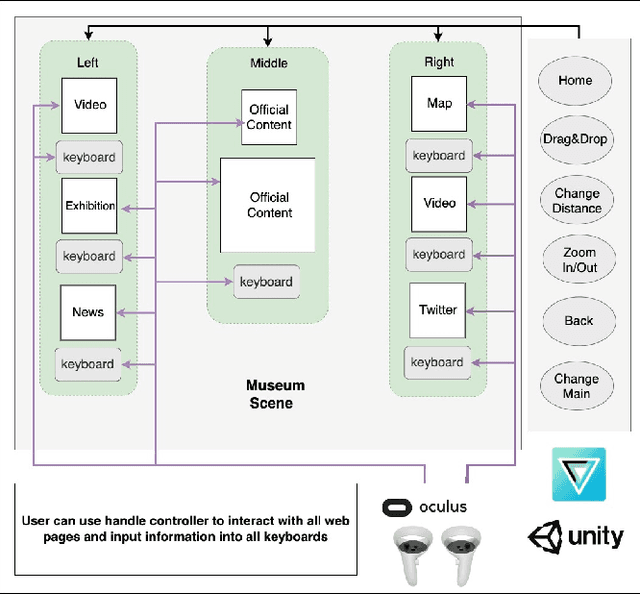

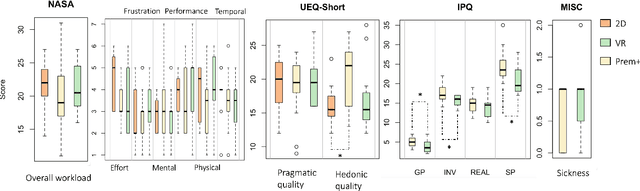
We present VR PreM+, an innovative VR system designed to enhance web exploration beyond traditional computer screens. Unlike static 2D displays, VR PreM+ leverages 3D environments to create an immersive pre-learning experience. Using keyword-based information retrieval allows users to manage and connect various content sources in a dynamic 3D space, improving communication and data comparison. We conducted preliminary and user studies that demonstrated efficient information retrieval, increased user engagement, and a greater sense of presence. These findings yielded three design guidelines for future VR information systems: display, interaction, and user-centric design. VR PreM+ bridges the gap between traditional web browsing and immersive VR, offering an interactive and comprehensive approach to information acquisition. It holds promise for research, education, and beyond.
Real-time Image Enhancer via Learnable Spatial-aware 3D Lookup Tables
Aug 19, 2021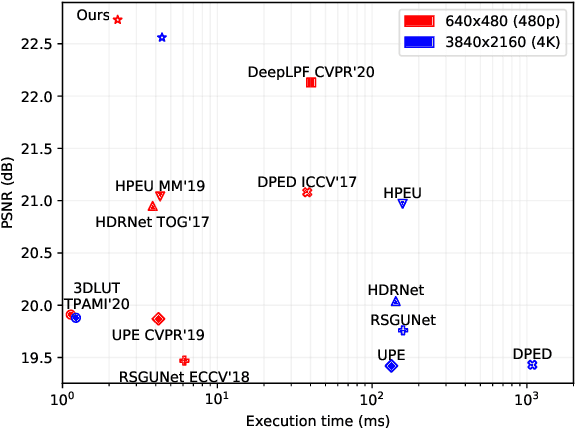
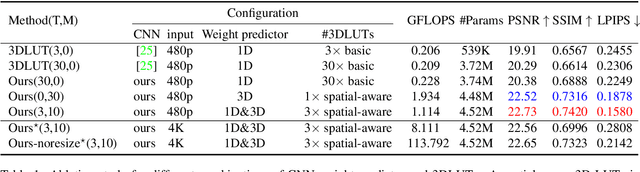
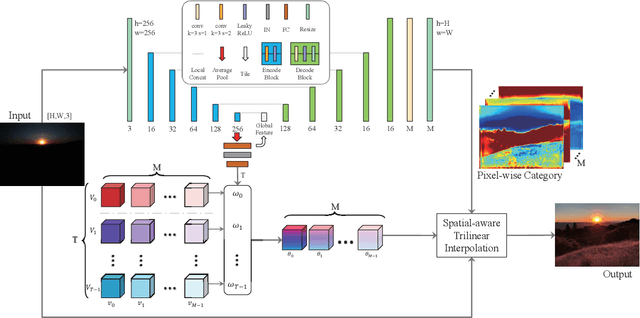
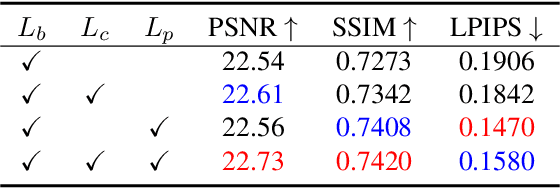
Recently, deep learning-based image enhancement algorithms achieved state-of-the-art (SOTA) performance on several publicly available datasets. However, most existing methods fail to meet practical requirements either for visual perception or for computation efficiency, especially for high-resolution images. In this paper, we propose a novel real-time image enhancer via learnable spatial-aware 3-dimentional lookup tables(3D LUTs), which well considers global scenario and local spatial information. Specifically, we introduce a light weight two-head weight predictor that has two outputs. One is a 1D weight vector used for image-level scenario adaptation, the other is a 3D weight map aimed for pixel-wise category fusion. We learn the spatial-aware 3D LUTs and fuse them according to the aforementioned weights in an end-to-end manner. The fused LUT is then used to transform the source image into the target tone in an efficient way. Extensive results show that our model outperforms SOTA image enhancement methods on public datasets both subjectively and objectively, and that our model only takes about 4ms to process a 4K resolution image on one NVIDIA V100 GPU.
Robust Image Captioning
Dec 06, 2020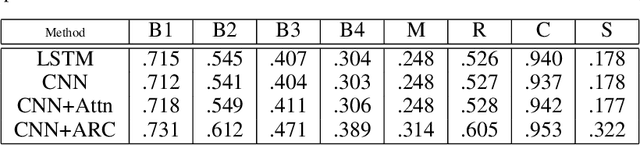
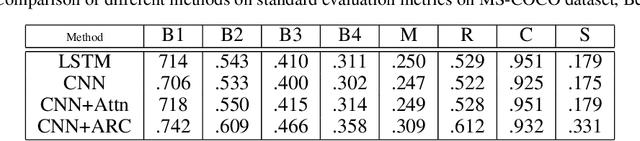
Automated captioning of photos is a mission that incorporates the difficulties of photo analysis and text generation. One essential feature of captioning is the concept of attention: how to determine what to specify and in which sequence. In this study, we leverage the Object Relation using adversarial robust cut algorithm, that grows upon this method by specifically embedding knowledge about the spatial association between input data through graph representation. Our experimental study represent the promising performance of our proposed method for image captioning.
Image Super-Resolution Using VDSR-ResNeXt and SRCGAN
Oct 10, 2018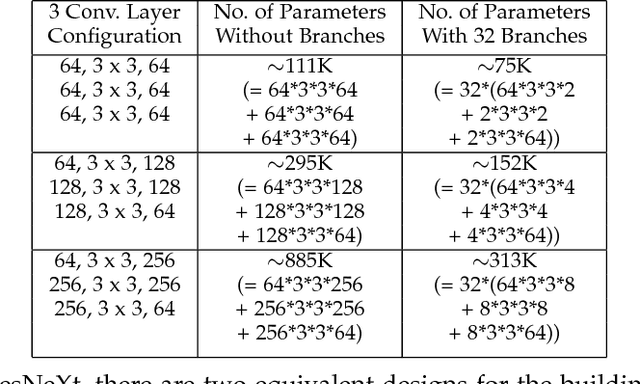
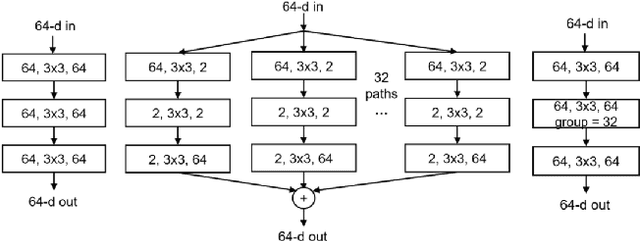
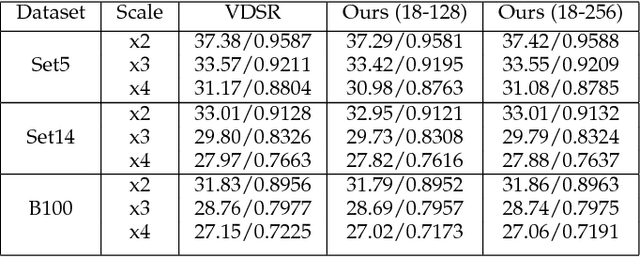
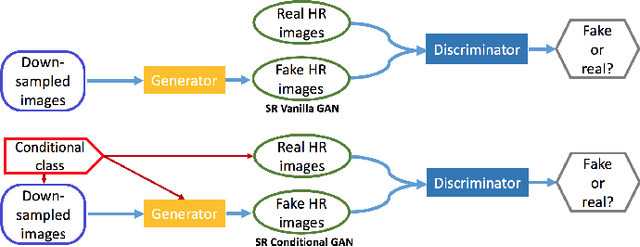
Over the past decade, many Super Resolution techniques have been developed using deep learning. Among those, generative adversarial networks (GAN) and very deep convolutional networks (VDSR) have shown promising results in terms of HR image quality and computational speed. In this paper, we propose two approaches based on these two algorithms: VDSR-ResNeXt, which is a deep multi-branch convolutional network inspired by VDSR and ResNeXt; and SRCGAN, which is a conditional GAN that explicitly passes class labels as input to the GAN. The two methods were implemented on common SR benchmark datasets for both quantitative and qualitative assessment.