 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSat3DGen: Comprehensive Street-Level 3D Scene Generation from Single Satellite Image
May 14, 2026Generating a street-level 3D scene from a single satellite image is a crucial yet challenging task. Current methods present a stark trade-off: geometry-colorization models achieve high geometric fidelity but are typically building-focused and lack semantic diversity. In contrast, proxy-based models use feed-forward image-to-3D frameworks to generate holistic scenes by jointly learning geometry and texture, a process that yields rich content but coarse and unstable geometry. We attribute these geometric failures to the extreme viewpoint gap and sparse, inconsistent supervision inherent in satellite-to-street data. We introduce Sat3DGen to address these fundamental challenges, which embodies a geometry-first methodology. This methodology enhances the feed-forward paradigm by integrating novel geometric constraints with a perspective-view training strategy, explicitly countering the primary sources of geometric error. This geometry-centric strategy yields a dramatic leap in both 3D accuracy and photorealism. For validation, we first constructed a new benchmark by pairing the VIGOR-OOD test set with high-resolution DSM data. On this benchmark, our method improves geometric RMSE from 6.76m to 5.20m. Crucially, this geometric leap also boosts photorealism, reducing the Fréchet Inception Distance (FID) from $\sim$40 to 19 against the leading method, Sat2Density++, despite using no extra tailored image-quality modules. We demonstrate the versatility of our high-quality 3D assets through diverse downstream applications, including semantic-map-to-3D synthesis, multi-camera video generation, large-scale meshing, and unsupervised single-image Digital Surface Model (DSM) estimation. The code has been released on https://github.com/qianmingduowan/Sat3DGen.
Mem3R: Streaming 3D Reconstruction with Hybrid Memory via Test-Time Training
Apr 08, 2026Streaming 3D perception is well suited to robotics and augmented reality, where long visual streams must be processed efficiently and consistently. Recent recurrent models offer a promising solution by maintaining fixed-size states and enabling linear-time inference, but they often suffer from drift accumulation and temporal forgetting over long sequences due to the limited capacity of compressed latent memories. We propose Mem3R, a streaming 3D reconstruction model with a hybrid memory design that decouples camera tracking from geometric mapping to improve temporal consistency over long sequences. For camera tracking, Mem3R employs an implicit fast-weight memory implemented as a lightweight Multi-Layer Perceptron updated via Test-Time Training. For geometric mapping, Mem3R maintains an explicit token-based fixed-size state. Compared with CUT3R, this design not only significantly improves long-sequence performance but also reduces the model size from 793M to 644M parameters. Mem3R supports existing improved plug-and-play state update strategies developed for CUT3R. Specifically, integrating it with TTT3R decreases Absolute Trajectory Error by up to 39% over the base implementation on 500 to 1000 frame sequences. The resulting improvements also extend to other downstream tasks, including video depth estimation and 3D reconstruction, while preserving constant GPU memory usage and comparable inference throughput. Project page: https://lck666666.github.io/Mem3R/
OpenNavMap: Structure-Free Topometric Mapping via Large-Scale Collaborative Localization
Jan 18, 2026Scalable and maintainable map representations are fundamental to enabling large-scale visual navigation and facilitating the deployment of robots in real-world environments. While collaborative localization across multi-session mapping enhances efficiency, traditional structure-based methods struggle with high maintenance costs and fail in feature-less environments or under significant viewpoint changes typical of crowd-sourced data. To address this, we propose OPENNAVMAP, a lightweight, structure-free topometric system leveraging 3D geometric foundation models for on-demand reconstruction. Our method unifies dynamic programming-based sequence matching, geometric verification, and confidence-calibrated optimization to robust, coarse-to-fine submap alignment without requiring pre-built 3D models. Evaluations on the Map-Free benchmark demonstrate superior accuracy over structure-from-motion and regression baselines, achieving an average translation error of 0.62m. Furthermore, the system maintains global consistency across 15km of multi-session data with an absolute trajectory error below 3m for map merging. Finally, we validate practical utility through 12 successful autonomous image-goal navigation tasks on simulated and physical robots. Code and datasets will be publicly available in https://rpl-cs-ucl.github.io/OpenNavMap_page.
LiteVLoc: Map-Lite Visual Localization for Image Goal Navigation
Oct 06, 2024



This paper presents LiteVLoc, a hierarchical visual localization framework that uses a lightweight topo-metric map to represent the environment. The method consists of three sequential modules that estimate camera poses in a coarse-to-fine manner. Unlike mainstream approaches relying on detailed 3D representations, LiteVLoc reduces storage overhead by leveraging learning-based feature matching and geometric solvers for metric pose estimation. A novel dataset for the map-free relocalization task is also introduced. Extensive experiments including localization and navigation in both simulated and real-world scenarios have validate the system's performance and demonstrated its precision and efficiency for large-scale deployment. Code and data will be made publicly available.
GSLoc: Efficient Camera Pose Refinement via 3D Gaussian Splatting
Aug 20, 2024



We leverage 3D Gaussian Splatting (3DGS) as a scene representation and propose a novel test-time camera pose refinement framework, GSLoc. This framework enhances the localization accuracy of state-of-the-art absolute pose regression and scene coordinate regression methods. The 3DGS model renders high-quality synthetic images and depth maps to facilitate the establishment of 2D-3D correspondences. GSLoc obviates the need for training feature extractors or descriptors by operating directly on RGB images, utilizing the 3D vision foundation model, MASt3R, for precise 2D matching. To improve the robustness of our model in challenging outdoor environments, we incorporate an exposure-adaptive module within the 3DGS framework. Consequently, GSLoc enables efficient pose refinement given a single RGB query and a coarse initial pose estimation. Our proposed approach surpasses leading NeRF-based optimization methods in both accuracy and runtime across indoor and outdoor visual localization benchmarks, achieving state-of-the-art accuracy on two indoor datasets.
AIR-HLoc: Adaptive Image Retrieval for Efficient Visual Localisation
Mar 27, 2024State-of-the-art (SOTA) hierarchical localisation pipelines (HLoc) rely on image retrieval (IR) techniques to establish 2D-3D correspondences by selecting the $k$ most similar images from a reference image database for a given query image. Although higher values of $k$ enhance localisation robustness, the computational cost for feature matching increases linearly with $k$. In this paper, we observe that queries that are the most similar to images in the database result in a higher proportion of feature matches and, thus, more accurate positioning. Thus, a small number of images is sufficient for queries very similar to images in the reference database. We then propose a novel approach, AIR-HLoc, which divides query images into different localisation difficulty levels based on their similarity to the reference image database. We consider an image with high similarity to the reference image as an easy query and an image with low similarity as a hard query. Easy queries show a limited improvement in accuracy when increasing $k$. Conversely, higher values of $k$ significantly improve accuracy for hard queries. Given the limited improvement in accuracy when increasing $k$ for easy queries and the significant improvement for hard queries, we adapt the value of $k$ to the query's difficulty level. Therefore, AIR-HLoc optimizes processing time by adaptively assigning different values of $k$ based on the similarity between the query and reference images without losing accuracy. Our extensive experiments on the Cambridge Landmarks, 7Scenes, and Aachen Day-Night-v1.1 datasets demonstrate our algorithm's efficacy, reducing 30\%, 26\%, and 11\% in computational overhead while maintaining SOTA accuracy compared to HLoc with fixed image retrieval.
HR-APR: APR-agnostic Framework with Uncertainty Estimation and Hierarchical Refinement for Camera Relocalisation
Feb 22, 2024



Absolute Pose Regressors (APRs) directly estimate camera poses from monocular images, but their accuracy is unstable for different queries. Uncertainty-aware APRs provide uncertainty information on the estimated pose, alleviating the impact of these unreliable predictions. However, existing uncertainty modelling techniques are often coupled with a specific APR architecture, resulting in suboptimal performance compared to state-of-the-art (SOTA) APR methods. This work introduces a novel APR-agnostic framework, HR-APR, that formulates uncertainty estimation as cosine similarity estimation between the query and database features. It does not rely on or affect APR network architecture, which is flexible and computationally efficient. In addition, we take advantage of the uncertainty for pose refinement to enhance the performance of APR. The extensive experiments demonstrate the effectiveness of our framework, reducing 27.4\% and 15.2\% of computational overhead on the 7Scenes and Cambridge Landmarks datasets while maintaining the SOTA accuracy in single-image APRs.
MobileARLoc: On-device Robust Absolute Localisation for Pervasive Markerless Mobile AR
Feb 04, 2024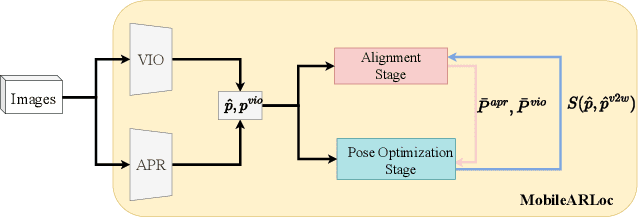

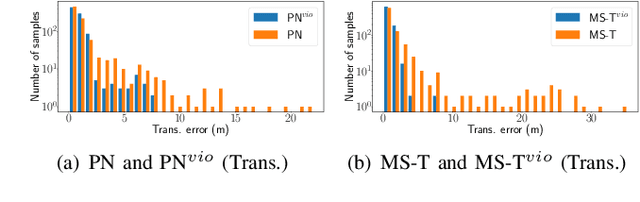

Recent years have seen significant improvement in absolute camera pose estimation, paving the way for pervasive markerless Augmented Reality (AR). However, accurate absolute pose estimation techniques are computation- and storage-heavy, requiring computation offloading. As such, AR systems rely on visual-inertial odometry (VIO) to track the device's relative pose between requests to the server. However, VIO suffers from drift, requiring frequent absolute repositioning. This paper introduces MobileARLoc, a new framework for on-device large-scale markerless mobile AR that combines an absolute pose regressor (APR) with a local VIO tracking system. Absolute pose regressors (APRs) provide fast on-device pose estimation at the cost of reduced accuracy. To address APR accuracy and reduce VIO drift, MobileARLoc creates a feedback loop where VIO pose estimations refine the APR predictions. The VIO system identifies reliable predictions of APR, which are then used to compensate for the VIO drift. We comprehensively evaluate MobileARLoc through dataset simulations. MobileARLoc halves the error compared to the underlying APR and achieve fast (80\,ms) on-device inference speed.
360Loc: A Dataset and Benchmark for Omnidirectional Visual Localization with Cross-device Queries
Nov 29, 2023Portable 360$^\circ$ cameras are becoming a cheap and efficient tool to establish large visual databases. By capturing omnidirectional views of a scene, these cameras could expedite building environment models that are essential for visual localization. However, such an advantage is often overlooked due to the lack of valuable datasets. This paper introduces a new benchmark dataset, 360Loc, composed of 360$^\circ$ images with ground truth poses for visual localization. We present a practical implementation of 360$^\circ$ mapping combining 360$^\circ$ images with lidar data to generate the ground truth 6DoF poses. 360Loc is the first dataset and benchmark that explores the challenge of cross-device visual positioning, involving 360$^\circ$ reference frames, and query frames from pinhole, ultra-wide FoV fisheye, and 360$^\circ$ cameras. We propose a virtual camera approach to generate lower-FoV query frames from 360$^\circ$ images, which ensures a fair comparison of performance among different query types in visual localization tasks. We also extend this virtual camera approach to feature matching-based and pose regression-based methods to alleviate the performance loss caused by the cross-device domain gap, and evaluate its effectiveness against state-of-the-art baselines. We demonstrate that omnidirectional visual localization is more robust in challenging large-scale scenes with symmetries and repetitive structures. These results provide new insights into 360-camera mapping and omnidirectional visual localization with cross-device queries.
VR PreM+ : An Immersive Pre-learning Branching Visualization System for Museum Tours
Nov 01, 2023
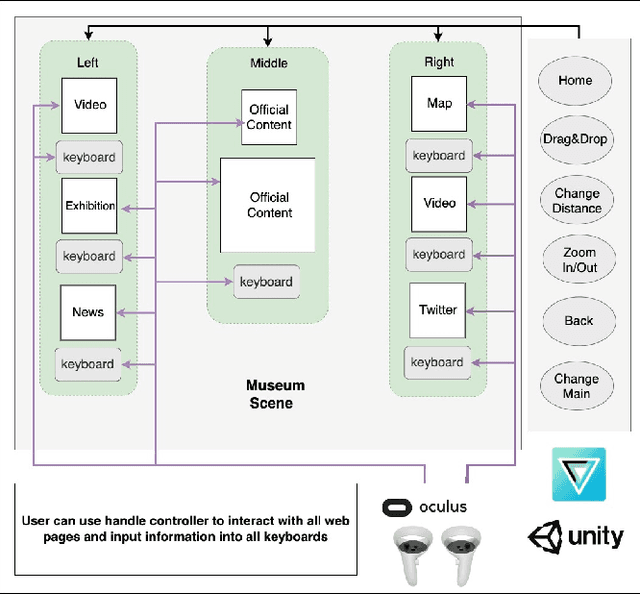

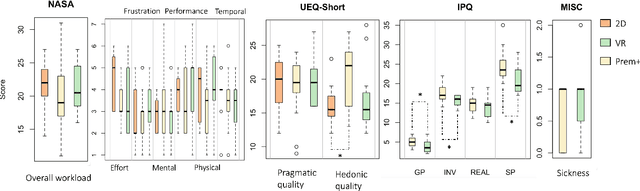
We present VR PreM+, an innovative VR system designed to enhance web exploration beyond traditional computer screens. Unlike static 2D displays, VR PreM+ leverages 3D environments to create an immersive pre-learning experience. Using keyword-based information retrieval allows users to manage and connect various content sources in a dynamic 3D space, improving communication and data comparison. We conducted preliminary and user studies that demonstrated efficient information retrieval, increased user engagement, and a greater sense of presence. These findings yielded three design guidelines for future VR information systems: display, interaction, and user-centric design. VR PreM+ bridges the gap between traditional web browsing and immersive VR, offering an interactive and comprehensive approach to information acquisition. It holds promise for research, education, and beyond.