 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFF-Grasp: Energy-Field Flow Matching for Physics-Aware Dexterous Grasp Generation
Mar 17, 2026Denoising generative models have recently become the dominant paradigm for dexterous grasp generation, owing to their ability to model complex grasp distributions from large-scale data. However, existing diffusion-based methods typically formulate generation as a stochastic differential equation (SDE), which often requires many sequential denoising steps and introduces trajectory instability that can lead to physically infeasible grasps. In this paper, we propose EFF-Grasp, a novel Flow-Matching-based framework for physics-aware dexterous grasp generation. Specifically, we reformulate grasp synthesis as a deterministic ordinary differential equation (ODE) process, which enables efficient and stable generation through smooth probability flows. To further enforce physical feasibility, we introduce a training-free physics-aware energy guidance strategy. Our method defines an energy-guided target distribution using adapted explicit physical energy functions that capture key grasp constraints, and estimates the corresponding guidance term via a local Monte Carlo approximation during inference. In this way, EFF-Grasp dynamically steers the generation trajectory toward physically feasible regions without requiring additional physics-based training or simulation feedback. Extensive experiments on five benchmark datasets show that EFF-Grasp achieves superior performance in grasp quality and physical feasibility, while requiring substantially fewer sampling steps than diffusion-based baselines.
Riemannian MeanFlow for One-Step Generation on Manifolds
Mar 11, 2026Flow Matching enables simulation-free training of generative models on Riemannian manifolds, yet sampling typically still relies on numerically integrating a probability-flow ODE. We propose Riemannian MeanFlow (RMF), extending MeanFlow to manifold-valued generation where velocities lie in location-dependent tangent spaces. RMF defines an average-velocity field via parallel transport and derives a Riemannian MeanFlow identity that links average and instantaneous velocities for intrinsic supervision. We make this identity practical in a log-map tangent representation, avoiding trajectory simulation and heavy geometric computations. For stable optimization, we decompose the RMF objective into two terms and apply conflict-aware multi-task learning to mitigate gradient interference. RMF also supports conditional generation via classifier-free guidance. Experiments on spheres, tori, and SO(3) demonstrate competitive one-step sampling with improved quality-efficiency trade-offs and substantially reduced sampling cost.
Beyond Instrumental and Substitutive Paradigms: Introducing Machine Culture as an Emergent Phenomenon in Large Language Models
Jan 23, 2026Recent scholarship typically characterizes Large Language Models (LLMs) through either an \textit{Instrumental Paradigm} (viewing models as reflections of their developers' culture) or a \textit{Substitutive Paradigm} (viewing models as bilingual proxies that switch cultural frames based on language). This study challenges these anthropomorphic frameworks by proposing \textbf{Machine Culture} as an emergent, distinct phenomenon. We employed a 2 (Model Origin: US vs. China) $\times$ 2 (Prompt Language: English vs. Chinese) factorial design across eight multimodal tasks, uniquely incorporating image generation and interpretation to extend analysis beyond textual boundaries. Results revealed inconsistencies with both dominant paradigms: Model origin did not predict cultural alignment, with US models frequently exhibiting ``holistic'' traits typically associated with East Asian data. Similarly, prompt language did not trigger stable cultural frame-switching; instead, we observed \textbf{Cultural Reversal}, where English prompts paradoxically elicited higher contextual attention than Chinese prompts. Crucially, we identified a novel phenomenon termed \textbf{Service Persona Camouflage}: Reinforcement Learning from Human Feedback (RLHF) collapsed cultural variance in affective tasks into a hyper-positive, zero-variance ``helpful assistant'' persona. We conclude that LLMs do not simulate human culture but exhibit an emergent Machine Culture -- a probabilistic phenomenon shaped by \textit{superposition} in high-dimensional space and \textit{mode collapse} from safety alignment.
DiffuGR: Generative Document Retrieval with Diffusion Language Models
Nov 19, 2025Generative retrieval (GR) re-frames document retrieval as a sequence-based document identifier (DocID) generation task, memorizing documents with model parameters and enabling end-to-end retrieval without explicit indexing. Existing GR methods are based on auto-regressive generative models, i.e., the token generation is performed from left to right. However, such auto-regressive methods suffer from: (1) mismatch between DocID generation and natural language generation, e.g., an incorrect DocID token generated in early left steps would lead to totally erroneous retrieval; and (2) failure to balance the trade-off between retrieval efficiency and accuracy dynamically, which is crucial for practical applications. To address these limitations, we propose generative document retrieval with diffusion language models, dubbed DiffuGR. It models DocID generation as a discrete diffusion process: during training, DocIDs are corrupted through a stochastic masking process, and a diffusion language model is learned to recover them under a retrieval-aware objective. For inference, DiffuGR attempts to generate DocID tokens in parallel and refines them through a controllable number of denoising steps. In contrast to conventional left-to-right auto-regressive decoding, DiffuGR provides a novel mechanism to first generate more confident DocID tokens and refine the generation through diffusion-based denoising. Moreover, DiffuGR also offers explicit runtime control over the qualitylatency tradeoff. Extensive experiments on benchmark retrieval datasets show that DiffuGR is competitive with strong auto-regressive generative retrievers, while offering flexible speed and accuracy tradeoffs through variable denoising budgets. Overall, our results indicate that non-autoregressive diffusion models are a practical and effective alternative for generative document retrieval.
Joint Flashback Adaptation for Forgetting-Resistant Instruction Tuning
May 21, 2025Large language models have achieved remarkable success in various tasks. However, it is challenging for them to learn new tasks incrementally due to catastrophic forgetting. Existing approaches rely on experience replay, optimization constraints, or task differentiation, which encounter strict limitations in real-world scenarios. To address these issues, we propose Joint Flashback Adaptation. We first introduce flashbacks -- a limited number of prompts from old tasks -- when adapting to new tasks and constrain the deviations of the model outputs compared to the original one. We then interpolate latent tasks between flashbacks and new tasks to enable jointly learning relevant latent tasks, new tasks, and flashbacks, alleviating data sparsity in flashbacks and facilitating knowledge sharing for smooth adaptation. Our method requires only a limited number of flashbacks without access to the replay data and is task-agnostic. We conduct extensive experiments on state-of-the-art large language models across 1000+ instruction-following tasks, arithmetic reasoning tasks, and general reasoning tasks. The results demonstrate the superior performance of our method in improving generalization on new tasks and reducing forgetting in old tasks.
Improving the Robustness of Large Language Models via Consistency Alignment
Mar 22, 2024



Large language models (LLMs) have shown tremendous success in following user instructions and generating helpful responses. Nevertheless, their robustness is still far from optimal, as they may generate significantly inconsistent responses due to minor changes in the verbalized instructions. Recent literature has explored this inconsistency issue, highlighting the importance of continued improvement in the robustness of response generation. However, systematic analysis and solutions are still lacking. In this paper, we quantitatively define the inconsistency problem and propose a two-stage training framework consisting of instruction-augmented supervised fine-tuning and consistency alignment training. The first stage helps a model generalize on following instructions via similar instruction augmentations. In the second stage, we improve the diversity and help the model understand which responses are more aligned with human expectations by differentiating subtle differences in similar responses. The training process is accomplished by self-rewards inferred from the trained model at the first stage without referring to external human preference resources. We conduct extensive experiments on recent publicly available LLMs on instruction-following tasks and demonstrate the effectiveness of our training framework.
HR-APR: APR-agnostic Framework with Uncertainty Estimation and Hierarchical Refinement for Camera Relocalisation
Feb 22, 2024



Absolute Pose Regressors (APRs) directly estimate camera poses from monocular images, but their accuracy is unstable for different queries. Uncertainty-aware APRs provide uncertainty information on the estimated pose, alleviating the impact of these unreliable predictions. However, existing uncertainty modelling techniques are often coupled with a specific APR architecture, resulting in suboptimal performance compared to state-of-the-art (SOTA) APR methods. This work introduces a novel APR-agnostic framework, HR-APR, that formulates uncertainty estimation as cosine similarity estimation between the query and database features. It does not rely on or affect APR network architecture, which is flexible and computationally efficient. In addition, we take advantage of the uncertainty for pose refinement to enhance the performance of APR. The extensive experiments demonstrate the effectiveness of our framework, reducing 27.4\% and 15.2\% of computational overhead on the 7Scenes and Cambridge Landmarks datasets while maintaining the SOTA accuracy in single-image APRs.
Automating Psychological Hypothesis Generation with AI: Large Language Models Meet Causal Graph
Feb 22, 2024Leveraging the synergy between causal knowledge graphs and a large language model (LLM), our study introduces a groundbreaking approach for computational hypothesis generation in psychology. We analyzed 43,312 psychology articles using a LLM to extract causal relation pairs. This analysis produced a specialized causal graph for psychology. Applying link prediction algorithms, we generated 130 potential psychological hypotheses focusing on `well-being', then compared them against research ideas conceived by doctoral scholars and those produced solely by the LLM. Interestingly, our combined approach of a LLM and causal graphs mirrored the expert-level insights in terms of novelty, clearly surpassing the LLM-only hypotheses (t(59) = 3.34, p=0.007 and t(59) = 4.32, p<0.001, respectively). This alignment was further corroborated using deep semantic analysis. Our results show that combining LLM with machine learning techniques such as causal knowledge graphs can revolutionize automated discovery in psychology, extracting novel insights from the extensive literature. This work stands at the crossroads of psychology and artificial intelligence, championing a new enriched paradigm for data-driven hypothesis generation in psychological research.
VisLingInstruct: Elevating Zero-Shot Learning in Multi-Modal Language Models with Autonomous Instruction Optimization
Feb 12, 2024This paper presents VisLingInstruct, a novel approach to advancing Multi-Modal Language Models (MMLMs) in zero-shot learning. Current MMLMs show impressive zero-shot abilities in multi-modal tasks, but their performance depends heavily on the quality of instructions. VisLingInstruct tackles this by autonomously evaluating and optimizing instructional texts through In-Context Learning, improving the synergy between visual perception and linguistic expression in MMLMs. Alongside this instructional advancement, we have also optimized the visual feature extraction modules in MMLMs, further augmenting their responsiveness to textual cues. Our comprehensive experiments on MMLMs, based on FlanT5 and Vicuna, show that VisLingInstruct significantly improves zero-shot performance in visual multi-modal tasks. Notably, it achieves a 13.1% and 9% increase in accuracy over the prior state-of-the-art on the TextVQA and HatefulMemes datasets.
MobileARLoc: On-device Robust Absolute Localisation for Pervasive Markerless Mobile AR
Feb 04, 2024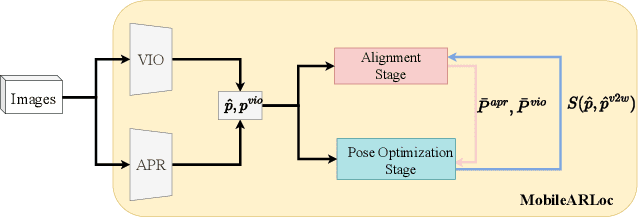

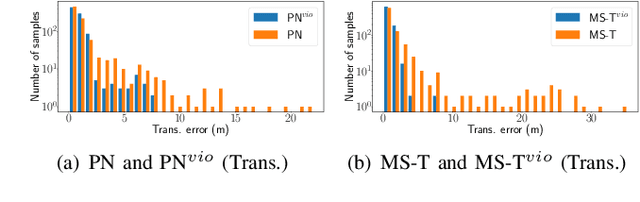

Recent years have seen significant improvement in absolute camera pose estimation, paving the way for pervasive markerless Augmented Reality (AR). However, accurate absolute pose estimation techniques are computation- and storage-heavy, requiring computation offloading. As such, AR systems rely on visual-inertial odometry (VIO) to track the device's relative pose between requests to the server. However, VIO suffers from drift, requiring frequent absolute repositioning. This paper introduces MobileARLoc, a new framework for on-device large-scale markerless mobile AR that combines an absolute pose regressor (APR) with a local VIO tracking system. Absolute pose regressors (APRs) provide fast on-device pose estimation at the cost of reduced accuracy. To address APR accuracy and reduce VIO drift, MobileARLoc creates a feedback loop where VIO pose estimations refine the APR predictions. The VIO system identifies reliable predictions of APR, which are then used to compensate for the VIO drift. We comprehensively evaluate MobileARLoc through dataset simulations. MobileARLoc halves the error compared to the underlying APR and achieve fast (80\,ms) on-device inference speed.