 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPiRi: Channel Permutation-Invariant Relational Interaction for Multivariate Time Series Forecasting
Jan 28, 2026Current methods for multivariate time series forecasting can be classified into channel-dependent and channel-independent models. Channel-dependent models learn cross-channel features but often overfit the channel ordering, which hampers adaptation when channels are added or reordered. Channel-independent models treat each channel in isolation to increase flexibility, yet this neglects inter-channel dependencies and limits performance. To address these limitations, we propose \textbf{CPiRi}, a \textbf{channel permutation invariant (CPI)} framework that infers cross-channel structure from data rather than memorizing a fixed ordering, enabling deployment in settings with structural and distributional co-drift without retraining. CPiRi couples \textbf{spatio-temporal decoupling architecture} with \textbf{permutation-invariant regularization training strategy}: a frozen pretrained temporal encoder extracts high-quality temporal features, a lightweight spatial module learns content-driven inter-channel relations, while a channel shuffling strategy enforces CPI during training. We further \textbf{ground CPiRi in theory} by analyzing permutation equivariance in multivariate time series forecasting. Experiments on multiple benchmarks show state-of-the-art results. CPiRi remains stable when channel orders are shuffled and exhibits strong \textbf{inductive generalization} to unseen channels even when trained on \textbf{only half} of the channels, while maintaining \textbf{practical efficiency} on large-scale datasets. The source code is released at https://github.com/JasonStraka/CPiRi.
AgentIF-OneDay: A Task-level Instruction-Following Benchmark for General AI Agents in Daily Scenarios
Jan 28, 2026The capacity of AI agents to effectively handle tasks of increasing duration and complexity continues to grow, demonstrating exceptional performance in coding, deep research, and complex problem-solving evaluations. However, in daily scenarios, the perception of these advanced AI capabilities among general users remains limited. We argue that current evaluations prioritize increasing task difficulty without sufficiently addressing the diversity of agentic tasks necessary to cover the daily work, life, and learning activities of a broad demographic. To address this, we propose AgentIF-OneDay, aimed at determining whether general users can utilize natural language instructions and AI agents to complete a diverse array of daily tasks. These tasks require not only solving problems through dialogue but also understanding various attachment types and delivering tangible file-based results. The benchmark is structured around three user-centric categories: Open Workflow Execution, which assesses adherence to explicit and complex workflows; Latent Instruction, which requires agents to infer implicit instructions from attachments; and Iterative Refinement, which involves modifying or expanding upon ongoing work. We employ instance-level rubrics and a refined evaluation pipeline that aligns LLM-based verification with human judgment, achieving an 80.1% agreement rate using Gemini-3-Pro. AgentIF-OneDay comprises 104 tasks covering 767 scoring points. We benchmarked four leading general AI agents and found that agent products built based on APIs and ChatGPT agents based on agent RL remain in the first tier simultaneously. Leading LLM APIs and open-source models have internalized agentic capabilities, enabling AI application teams to develop cutting-edge Agent products.
The Semantic Lifecycle in Embodied AI: Acquisition, Representation and Storage via Foundation Models
Jan 12, 2026Semantic information in embodied AI is inherently multi-source and multi-stage, making it challenging to fully leverage for achieving stable perception-to-action loops in real-world environments. Early studies have combined manual engineering with deep neural networks, achieving notable progress in specific semantic-related embodied tasks. However, as embodied agents encounter increasingly complex environments and open-ended tasks, the demand for more generalizable and robust semantic processing capabilities has become imperative. Recent advances in foundation models (FMs) address this challenge through their cross-domain generalization abilities and rich semantic priors, reshaping the landscape of embodied AI research. In this survey, we propose the Semantic Lifecycle as a unified framework to characterize the evolution of semantic knowledge within embodied AI driven by foundation models. Departing from traditional paradigms that treat semantic processing as isolated modules or disjoint tasks, our framework offers a holistic perspective that captures the continuous flow and maintenance of semantic knowledge. Guided by this embodied semantic lifecycle, we further analyze and compare recent advances across three key stages: acquisition, representation, and storage. Finally, we summarize existing challenges and outline promising directions for future research.
A Universal and Robust Framework for Multiple Gas Recognition Based-on Spherical Normalization-Coupled Mahalanobis Algorithm
Jan 05, 2026Electronic nose (E-nose) systems face two interconnected challenges in open-set gas recognition: feature distribution shift caused by signal drift and decision boundary failure induced by unknown gas interference. Existing methods predominantly rely on Euclidean distance or conventional classifiers, failing to account for anisotropic feature distributions and dynamic signal intensity variations. To address these issues, this study proposes the Spherical Normalization coupled Mahalanobis (SNM) module, a universal post-processing module for open-set gas recognition. First, it achieves geometric decoupling through cascaded batch and L2 normalization, projecting features onto a unit hypersphere to eliminate signal intensity fluctuations. Second, it utilizes Mahalanobis distance to construct adaptive ellipsoidal decision boundaries that conform to the anisotropic feature geometry. The architecture-agnostic SNM-Module seamlessly integrates with mainstream backbones including Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), and Transformer. Experiments on the public Vergara dataset demonstrate that the Transformer+SNM configuration achieves near-theoretical-limit performance in discriminating among multiple target gases, with an AUROC of 0.9977 and an unknown gas detection rate of 99.57% at 5% false positive rate, significantly outperforming state-of-the-art methods with a 3.0% AUROC improvement and 91.0% standard deviation reduction compared to Class Anchor Clustering (CAC). The module maintains exceptional robustness across five sensor positions, with standard deviations below 0.0028. This work effectively addresses the critical challenge of simultaneously achieving high accuracy and high stability in open-set gas recognition, providing solid support for industrial E-nose deployment.
SNM-Net: A Universal Framework for Robust Open-Set Gas Recognition via Spherical Normalization and Mahalanobis Distance
Dec 28, 2025Electronic nose (E-nose) systems face dual challenges in open-set gas recognition: feature distribution shifts caused by signal drift and decision failures induced by unknown interference. Existing methods predominantly rely on Euclidean distance, failing to adequately account for anisotropic gas feature distributions and dynamic signal intensity variations. To address these issues, this study proposes SNM-Net, a universal deep learning framework for open-set gas recognition. The core innovation lies in a geometric decoupling mechanism achieved through cascaded batch normalization and L2 normalization, which projects high-dimensional features onto a unit hypersphere to eliminate signal intensity fluctuations. Additionally, Mahalanobis distance is introduced as the scoring mechanism, utilizing class-wise statistics to construct adaptive ellipsoidal decision boundaries. SNM-Net is architecture-agnostic and seamlessly integrates with CNN, RNN, and Transformer backbones. Systematic experiments on the Vergara dataset demonstrate that the Transformer+SNM configuration attains near-theoretical performance, achieving an AUROC of 0.9977 and an unknown gas detection rate of 99.57% (TPR at 5% FPR). This performance significantly outperforms state-of-the-art methods, showing a 3.0% improvement in AUROC and a 91.0% reduction in standard deviation compared to Class Anchor Clustering. The framework exhibits exceptional robustness across sensor positions with standard deviations below 0.0028. This work effectively resolves the trade-off between accuracy and stability, providing a solid technical foundation for industrial E-nose deployment.
ACPO: Adaptive Curriculum Policy Optimization for Aligning Vision-Language Models in Complex Reasoning
Oct 01, 2025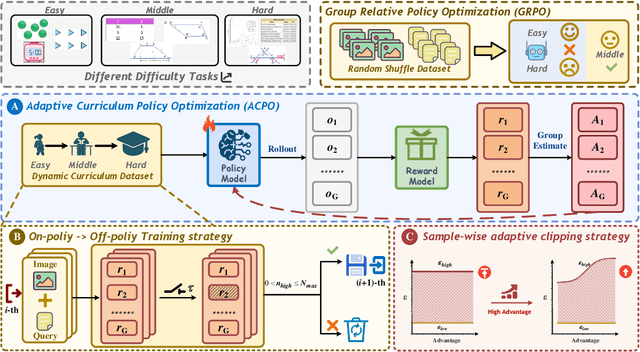


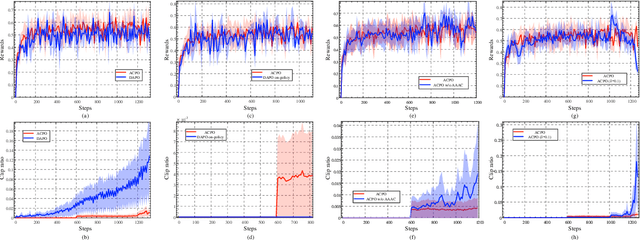
Aligning large-scale vision-language models (VLMs) for complex reasoning via reinforcement learning is often hampered by the limitations of existing policy optimization algorithms, such as static training schedules and the rigid, uniform clipping mechanism in Proximal Policy Optimization (PPO). In this work, we introduce Adaptive Curriculum Policy Optimization (ACPO), a novel framework that addresses these challenges through a dual-component adaptive learning strategy. First, ACPO employs a dynamic curriculum that orchestrates a principled transition from a stable, near on-policy exploration phase to an efficient, off-policy exploitation phase by progressively increasing sample reuse. Second, we propose an Advantage-Aware Adaptive Clipping (AAAC) mechanism that replaces the fixed clipping hyperparameter with dynamic, sample-wise bounds modulated by the normalized advantage of each token. This allows for more granular and robust policy updates, enabling larger gradients for high-potential samples while safeguarding against destructive ones. We conduct extensive experiments on a suite of challenging multimodal reasoning benchmarks, including MathVista, LogicVista, and MMMU-Pro. Results demonstrate that ACPO consistently outperforms strong baselines such as DAPO and PAPO, achieving state-of-the-art performance, accelerated convergence, and superior training stability.
RISK: A Framework for GUI Agents in E-commerce Risk Management
Sep 26, 2025E-commerce risk management requires aggregating diverse, deeply embedded web data through multi-step, stateful interactions, which traditional scraping methods and most existing Graphical User Interface (GUI) agents cannot handle. These agents are typically limited to single-step tasks and lack the ability to manage dynamic, interactive content critical for effective risk assessment. To address this challenge, we introduce RISK, a novel framework designed to build and deploy GUI agents for this domain. RISK integrates three components: (1) RISK-Data, a dataset of 8,492 single-step and 2,386 multi-step interaction trajectories, collected through a high-fidelity browser framework and a meticulous data curation process; (2) RISK-Bench, a benchmark with 802 single-step and 320 multi-step trajectories across three difficulty levels for standardized evaluation; and (3) RISK-R1, a R1-style reinforcement fine-tuning framework considering four aspects: (i) Output Format: Updated format reward to enhance output syntactic correctness and task comprehension, (ii) Single-step Level: Stepwise accuracy reward to provide granular feedback during early training stages, (iii) Multi-step Level: Process reweight to emphasize critical later steps in interaction sequences, and (iv) Task Level: Level reweight to focus on tasks of varying difficulty. Experiments show that RISK-R1 outperforms existing baselines, achieving a 6.8% improvement in offline single-step and an 8.8% improvement in offline multi-step. Moreover, it attains a top task success rate of 70.5% in online evaluation. RISK provides a scalable, domain-specific solution for automating complex web interactions, advancing the state of the art in e-commerce risk management.
CMP: A Composable Meta Prompt for SAM-Based Cross-Domain Few-Shot Segmentation
Jul 22, 2025Cross-Domain Few-Shot Segmentation (CD-FSS) remains challenging due to limited data and domain shifts. Recent foundation models like the Segment Anything Model (SAM) have shown remarkable zero-shot generalization capability in general segmentation tasks, making it a promising solution for few-shot scenarios. However, adapting SAM to CD-FSS faces two critical challenges: reliance on manual prompt and limited cross-domain ability. Therefore, we propose the Composable Meta-Prompt (CMP) framework that introduces three key modules: (i) the Reference Complement and Transformation (RCT) module for semantic expansion, (ii) the Composable Meta-Prompt Generation (CMPG) module for automated meta-prompt synthesis, and (iii) the Frequency-Aware Interaction (FAI) module for domain discrepancy mitigation. Evaluations across four cross-domain datasets demonstrate CMP's state-of-the-art performance, achieving 71.8\% and 74.5\% mIoU in 1-shot and 5-shot scenarios respectively.
DFR: A Decompose-Fuse-Reconstruct Framework for Multi-Modal Few-Shot Segmentation
Jul 22, 2025This paper presents DFR (Decompose, Fuse and Reconstruct), a novel framework that addresses the fundamental challenge of effectively utilizing multi-modal guidance in few-shot segmentation (FSS). While existing approaches primarily rely on visual support samples or textual descriptions, their single or dual-modal paradigms limit exploitation of rich perceptual information available in real-world scenarios. To overcome this limitation, the proposed approach leverages the Segment Anything Model (SAM) to systematically integrate visual, textual, and audio modalities for enhanced semantic understanding. The DFR framework introduces three key innovations: 1) Multi-modal Decompose: a hierarchical decomposition scheme that extracts visual region proposals via SAM, expands textual semantics into fine-grained descriptors, and processes audio features for contextual enrichment; 2) Multi-modal Contrastive Fuse: a fusion strategy employing contrastive learning to maintain consistency across visual, textual, and audio modalities while enabling dynamic semantic interactions between foreground and background features; 3) Dual-path Reconstruct: an adaptive integration mechanism combining semantic guidance from tri-modal fused tokens with geometric cues from multi-modal location priors. Extensive experiments across visual, textual, and audio modalities under both synthetic and real settings demonstrate DFR's substantial performance improvements over state-of-the-art methods.
CMaP-SAM: Contraction Mapping Prior for SAM-driven Few-shot Segmentation
Apr 07, 2025



Few-shot segmentation (FSS) aims to segment new classes using few annotated images. While recent FSS methods have shown considerable improvements by leveraging Segment Anything Model (SAM), they face two critical limitations: insufficient utilization of structural correlations in query images, and significant information loss when converting continuous position priors to discrete point prompts. To address these challenges, we propose CMaP-SAM, a novel framework that introduces contraction mapping theory to optimize position priors for SAM-driven few-shot segmentation. CMaP-SAM consists of three key components: (1) a contraction mapping module that formulates position prior optimization as a Banach contraction mapping with convergence guarantees. This module iteratively refines position priors through pixel-wise structural similarity, generating a converged prior that preserves both semantic guidance from reference images and structural correlations in query images; (2) an adaptive distribution alignment module bridging continuous priors with SAM's binary mask prompt encoder; and (3) a foreground-background decoupled refinement architecture producing accurate final segmentation masks. Extensive experiments demonstrate CMaP-SAM's effectiveness, achieving state-of-the-art performance with 71.1 mIoU on PASCAL-$5^i$ and 56.1 on COCO-$20^i$ datasets.