 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexInfer: Breaking Memory Constraint via Flexible and Efficient Offloading for On-Device LLM Inference
Mar 04, 2025
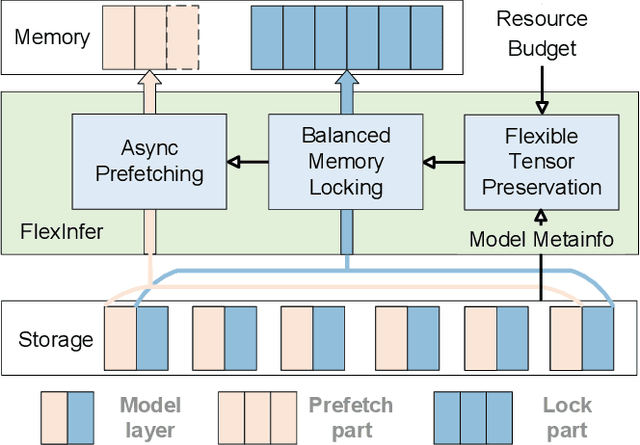
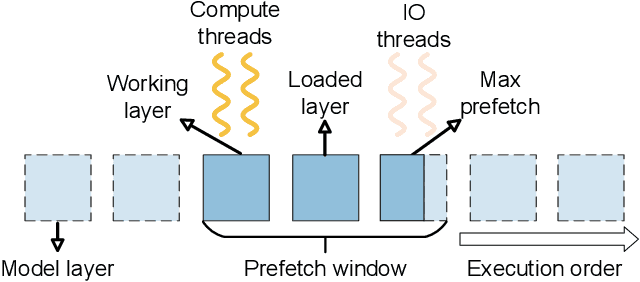
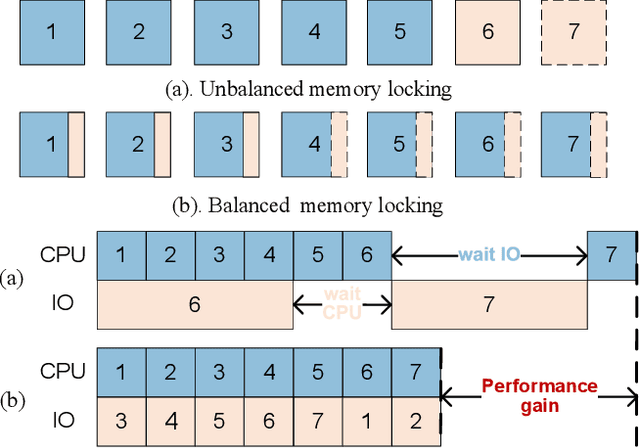
Large Language Models (LLMs) face challenges for on-device inference due to high memory demands. Traditional methods to reduce memory usage often compromise performance and lack adaptability. We propose FlexInfer, an optimized offloading framework for on-device inference, addressing these issues with techniques like asynchronous prefetching, balanced memory locking, and flexible tensor preservation. These strategies enhance memory efficiency and mitigate I/O bottlenecks, ensuring high performance within user-specified resource constraints. Experiments demonstrate that FlexInfer significantly improves throughput under limited resources, achieving up to 12.5 times better performance than existing methods and facilitating the deployment of large models on resource-constrained devices.
When Compression Meets Model Compression: Memory-Efficient Double Compression for Large Language Models
Feb 21, 2025Large language models (LLMs) exhibit excellent performance in various tasks. However, the memory requirements of LLMs present a great challenge when deploying on memory-limited devices, even for quantized LLMs. This paper introduces a framework to compress LLM after quantization further, achieving about 2.2x compression ratio. A compression-aware quantization is first proposed to enhance model weight compressibility by re-scaling the model parameters before quantization, followed by a pruning method to improve further. Upon this, we notice that decompression can be a bottleneck during practical scenarios. We then give a detailed analysis of the trade-off between memory usage and latency brought by the proposed method. A speed-adaptive method is proposed to overcome it. The experimental results show inference with the compressed model can achieve a 40% reduction in memory size with negligible loss in accuracy and inference speed.
EvoP: Robust LLM Inference via Evolutionary Pruning
Feb 19, 2025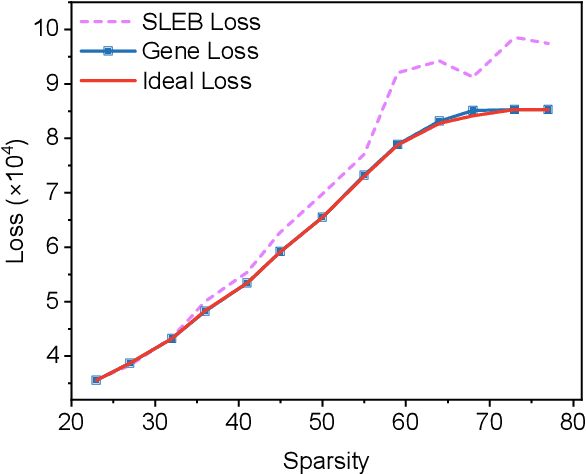
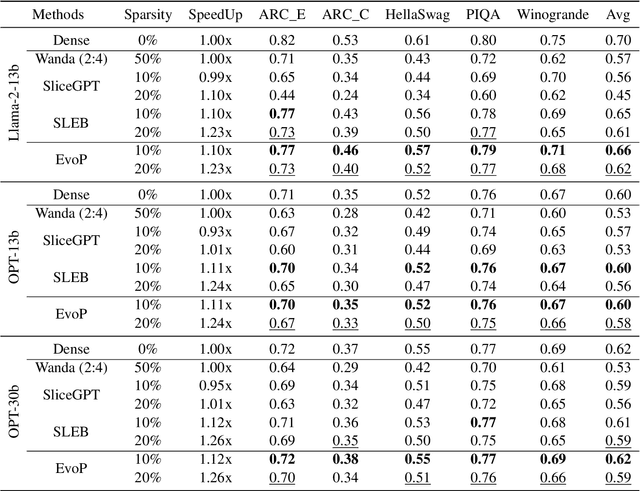
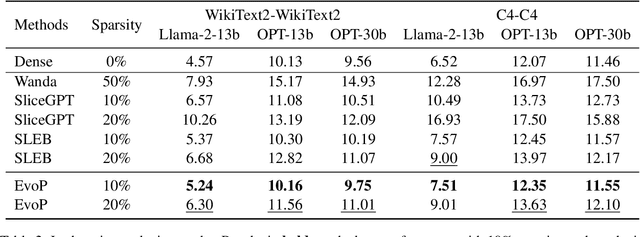
Large Language Models (LLMs) have achieved remarkable success in natural language processing tasks, but their massive size and computational demands hinder their deployment in resource-constrained environments. Existing structured pruning methods address this issue by removing redundant structures (e.g., elements, channels, layers) from the model. However, these methods employ a heuristic pruning strategy, which leads to suboptimal performance. Besides, they also ignore the data characteristics when pruning the model. To overcome these limitations, we propose EvoP, an evolutionary pruning framework for robust LLM inference. EvoP first presents a cluster-based calibration dataset sampling (CCDS) strategy for creating a more diverse calibration dataset. EvoP then introduces an evolutionary pruning pattern searching (EPPS) method to find the optimal pruning pattern. Compared to existing structured pruning techniques, EvoP achieves the best performance while maintaining the best efficiency. Experiments across different LLMs and different downstream tasks validate the effectiveness of the proposed EvoP, making it a practical and scalable solution for deploying LLMs in real-world applications.
On the Compressibility of Quantized Large Language Models
Mar 03, 2024



Deploying Large Language Models (LLMs) on edge or mobile devices offers significant benefits, such as enhanced data privacy and real-time processing capabilities. However, it also faces critical challenges due to the substantial memory requirement of LLMs. Quantization is an effective way of reducing the model size while maintaining good performance. However, even after quantization, LLMs may still be too big to fit entirely into the limited memory of edge or mobile devices and have to be partially loaded from the storage to complete the inference. In this case, the I/O latency of model loading becomes the bottleneck of the LLM inference latency. In this work, we take a preliminary step of studying applying data compression techniques to reduce data movement and thus speed up the inference of quantized LLM on memory-constrained devices. In particular, we discussed the compressibility of quantized LLMs, the trade-off between the compressibility and performance of quantized LLMs, and opportunities to optimize both of them jointly.